DagProcessor Performance Regression #30884
Comments
|
Can you please check if 2.6.0rc* version solves your problem? |
|
@george-zubrienko - I have some extra questions that might help to find out the root cause.
Generally speaking I would like to know your top-level parsing violates any of the best practices described in https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html#top-level-python-code ?
Having those answers might help in investigating the root cuase - the problem you describe is not reproducible easily - so we need to know what's so special about your DAGS or environment that triggers that behaviour. With the related #305903 it seemsed that the reason might be MySQL but knowing that you have Postgres suggests that either the problem is different or that it is something completely different than we suspected before. |
|
Combining answers here - I'll try with 2.6.0rc or maybe released version if it gets released before I get an hour to do a test.
I can pinpoint a few things:
We always try import only what we need in DAG files, but sometimes there can be imports for typehinting purposes only.
No, never.
Infamous In some dags we also read 1-2 connections stored in Airflow db. That's it.
See notes above.
Memory usage on dag file processor pod starts at around 180mb and grows to around 1.6gb on initial parse and then stabilizes around 700mb and cpu usage drops to ~2-3% from initial ~50%
No, we also have SLA and email/error callbacks fully disabled. Please find below a full example of DAG that consists of 1 task only: |
|
Adding more info:
let me know if you want to know helm values we pass when deploying |
|
Very helpful, thanks! |
|
Also - I am not sure if you could try it - the observation of @wooklist was that the root cause was this commit #30079 and it is very small. We could not see so far, why it would be the cause but if this would be possibl to modify installed dag file processor code and revert that commit, to see if that helps, that would help to narrow down the diagnosis immensely. |
|
And just to explain why - I will (in the meantime) try to reproduce it locally and see if we can observe similar behaviours on our installation, but just knowing that this is the cause could allow us to possibly remediate it with removal of that commit in 2.6.0 rc while we can even if we do not know exactly what is the mechanism behind the slow-down. |
|
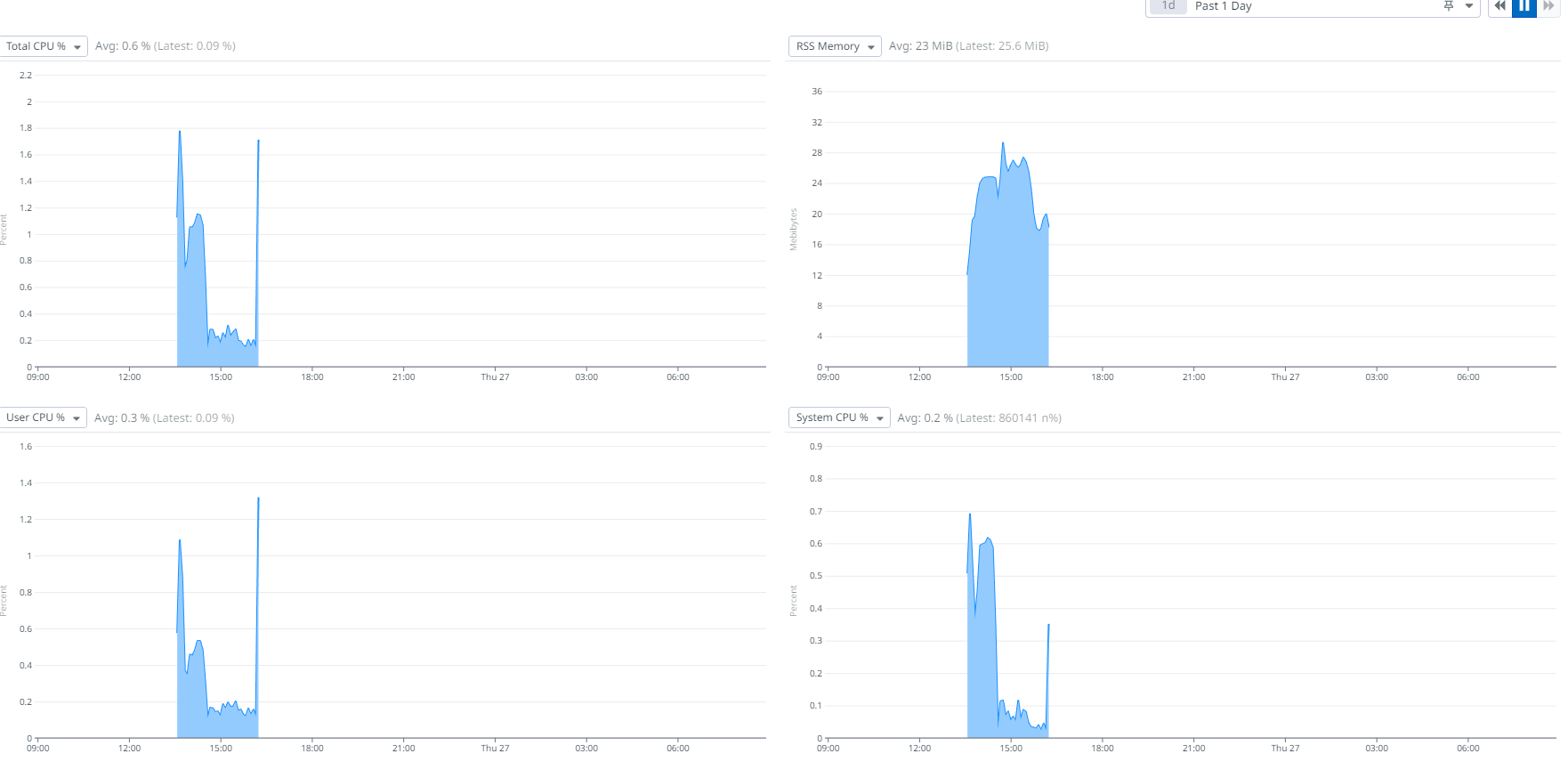
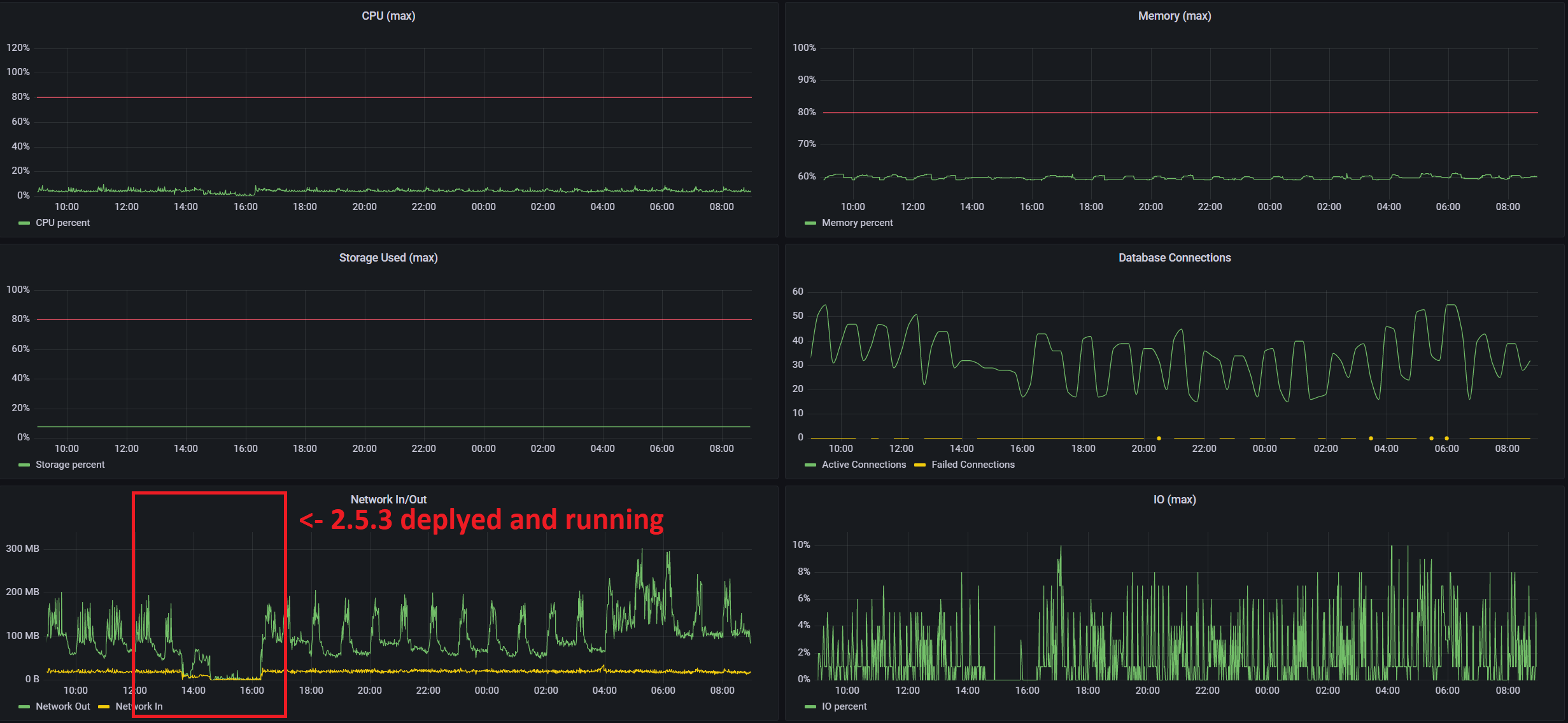
I remember looking at that commit, but I agree even if it is causing this behaviour, this is not an easy guess at all. For example, these are metrics from pgbouncer pod that guards our Postgres, when it ran with 2.5.3 - not much load at all, and cluster was not scheduling anything, so that load is webserver+dagprocessor.
In production our xact/s is between ~90 and ~300 depending on the number of running tasks. However, there was one change that stood out, but I could not explain it. After the upgrade, these are key metrics from Postgres it self (Azure single server btw):
You can see there is a significant drop in traffic between db and airflow cluster after we rolled out 2.5.3. Maybe it is nothing, but just so you have a more or less complete picture from our end. Since we already have an image with 2.5.3, I can add a layer on top with modified |
|
Oh whoa! That's what I call "deep" data (not a big but "deep"). :). Thanks for that - it's super helpful. Quick question though - what was the version you had before 2.5.3 / rolled back to ? |
|
This is the Dockerfile content for our current image - also the one we tried to upgrade from: I don't have SHA unfortunately, and we do not rebuild images on a regular basis, so it might not be exactly the one available on Dockerhub right now. Update to 2.5.3 is simple: And poetry dependency spec I have provided in the issue description. If you want to build the exact same image, you can use this GH workflow: I can provide the lock file if you want to go this way. |
|
One more (really kind) request - not now but in case we do not find anything till you have the chance to experiment, but it almost looks like there is something that prevents the Variable.get to obtain the connection to retrieve anything from the database (and looks like this single Variable.get() is blocking everythig. That gives me some ideas to look (and why maybe it has not been experienced by others who have no Variables at the top-level code, but if we do not get there, just removing the Variables.get() and hardcoding the output - might be a quick way to test that hypothesis. |
|
I think I found it . completely different. What is your job_heartbeat_sec ? https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#job-heartbeat-sec |
Dag processor in 2.5.3 rollout always showed duration for all parse tasks around 56-60 secs, but I didn't know it is that setting that regulates that btw. |
|
OK. That would explain it then. It is then indeed the same issue as #30593 but the effect of it has been magnified by the fact that your job_heartbeeat sec is THAT long.
Yes. That was a bug I introduced when fixing the liveness check for standalone dag file processor in #30278 - we are using that heartbeat historically for all the jobs (it's also used by local_task_job and triggerer btw) so the section where it is is actually wrong and we should move it out of scheduler section. Fix is here: #30899 There are few workarounds for that:
|
The standalone file processor as of apache#30278 introduced accidentally an artifficial delay between dag processing by adding heartbeat but missing to set "only_if_necessary" flag to True. If your dag file processing has been fast (faster than the scheduler job_heartbeat_sec) this introduced unnecessary pause between the next dag file processor loop (up until the time passed), it also introduced inflation of the dag_processing_last_duration metrics (it would always show minimum job_heartbeat_sec) Adding "only_if_necessary" flag fixes the problem. Fixes: apache#30593 Fixes: apache#30884
As I recall, we used to have a lot of issues with tasks (k8s pods) receiving SIGTERM in high load periods because they didn't heartbeat fast enough (at least that was our theory), then we figured out that was somehow related to database communication. First we tried to play around with pgbouncer settings - increasing number of allowed client connections and pool size, bumped database from 2 core / 8g to 4 core / 16g and base iops from like 100 to >2000, which helped for like a couple of months. Then people produced more dags, more tasks and it seemed unreasonable that we needed to bump database again, and pgbouncer was already running with 1k connection pool size. Then we found out that increasing that setting significantly reduces number of database sessions and our problems with dying tasks were resolved. I should probably have opened an issue on that as well, but we were so happy our models can be trained again, we sort of let it slip somewhere in the backlog. |
|
I don't know if our I'd be happy to try out |
The standalone file processor as of #30278 introduced accidentally an artifficial delay between dag processing by adding heartbeat but missing to set "only_if_necessary" flag to True. If your dag file processing has been fast (faster than the scheduler job_heartbeat_sec) this introduced unnecessary pause between the next dag file processor loop (up until the time passed), it also introduced inflation of the dag_processing_last_duration metrics (it would always show minimum job_heartbeat_sec) Adding "only_if_necessary" flag fixes the problem. Fixes: #30593 Fixes: #30884
The standalone file processor as of #30278 introduced accidentally an artifficial delay between dag processing by adding heartbeat but missing to set "only_if_necessary" flag to True. If your dag file processing has been fast (faster than the scheduler job_heartbeat_sec) this introduced unnecessary pause between the next dag file processor loop (up until the time passed), it also introduced inflation of the dag_processing_last_duration metrics (it would always show minimum job_heartbeat_sec) Adding "only_if_necessary" flag fixes the problem. Fixes: #30593 Fixes: #30884 (cherry picked from commit 00ab45f)
Cool. We will get RC3 soon
I think this is actually a very good point and comment. That actually makes me think that we should have DIFFERENT heartbeat expectations for local task (generally for each job type we have - as mentioned above historically they are the same) I created an issue for that and I will implement it during some of the tasks I am working on soon as part of our AIP-44 work. Issue here #30908 |
Apache Airflow version
2.5.3
What happened
Upgrading from
2.4.3to2.5.3caused a significant increase in dag processing time on standalone dag processor (~1-2s to 60s):Also seeing messages like these
In
2.4.3:What you think should happen instead
Dag processing time remains unchanged
How to reproduce
Provision Airflow with the following settings:
Airflow 2.5.3
Airflow 2.4.3
Image modifications
We use image built from
apache/airflow:2.4.3-python3.9, with some dependencies added/reinstalled with different versions.Poetry dependency spec:
For
2.5.3:For
2.4.3:Operating System
Container OS: Debian GNU/Linux 11 (bullseye)
Versions of Apache Airflow Providers
apache-airflow-providers-amazon==6.0.0
apache-airflow-providers-celery==3.0.0
apache-airflow-providers-cncf-kubernetes==4.4.0
apache-airflow-providers-common-sql==1.3.4
apache-airflow-providers-databricks==3.1.0
apache-airflow-providers-datadog==3.0.0
apache-airflow-providers-docker==3.2.0
apache-airflow-providers-elasticsearch==4.2.1
apache-airflow-providers-ftp==3.3.1
apache-airflow-providers-google==8.4.0
apache-airflow-providers-grpc==3.0.0
apache-airflow-providers-hashicorp==3.1.0
apache-airflow-providers-http==4.3.0
apache-airflow-providers-imap==3.1.1
apache-airflow-providers-microsoft-azure==5.2.1
apache-airflow-providers-mysql==3.2.1
apache-airflow-providers-odbc==3.1.2
apache-airflow-providers-postgres==5.2.2
apache-airflow-providers-redis==3.0.0
apache-airflow-providers-sendgrid==3.0.0
apache-airflow-providers-sftp==4.1.0
apache-airflow-providers-slack==6.0.0
apache-airflow-providers-snowflake==3.3.0
apache-airflow-providers-sqlite==3.3.2
apache-airflow-providers-ssh==3.2.0
Deployment
Official Apache Airflow Helm Chart
Deployment details
See How-to-reproduce section
Anything else
Occurs by upgrading the helm chart from 1.7.0/2.4.3 to 1.9.0/2.5.3 installation.
Are you willing to submit PR?
Code of Conduct
The text was updated successfully, but these errors were encountered: