Support hotspot key detection in Pegasus #495
Comments
We can name this RPC to struct hotkey_detect_request {
optional gpid partition;
}
struct hotkey_detect_response {
optional int err;
optional blob hashkey;
}
We can name it struct stop_hotkey_detect_request {
optional gpid partition;
}
struct stop_hotkey_detect_response {
optional int err;
} |
What is THRESHOLD_1 and THRESHOLD_2?
What is read_watch_list? I recommend that you can describe the data structures first, the pseudocodes like functions or classes should not be our first concern. Of course, it will be fine to include them, you can give a highly-descriptive function name without implementation, rather than give something like "excpetion_read_check". I don't really know what it means. |
|
Update2.2.1 How to start capturing databenchmark
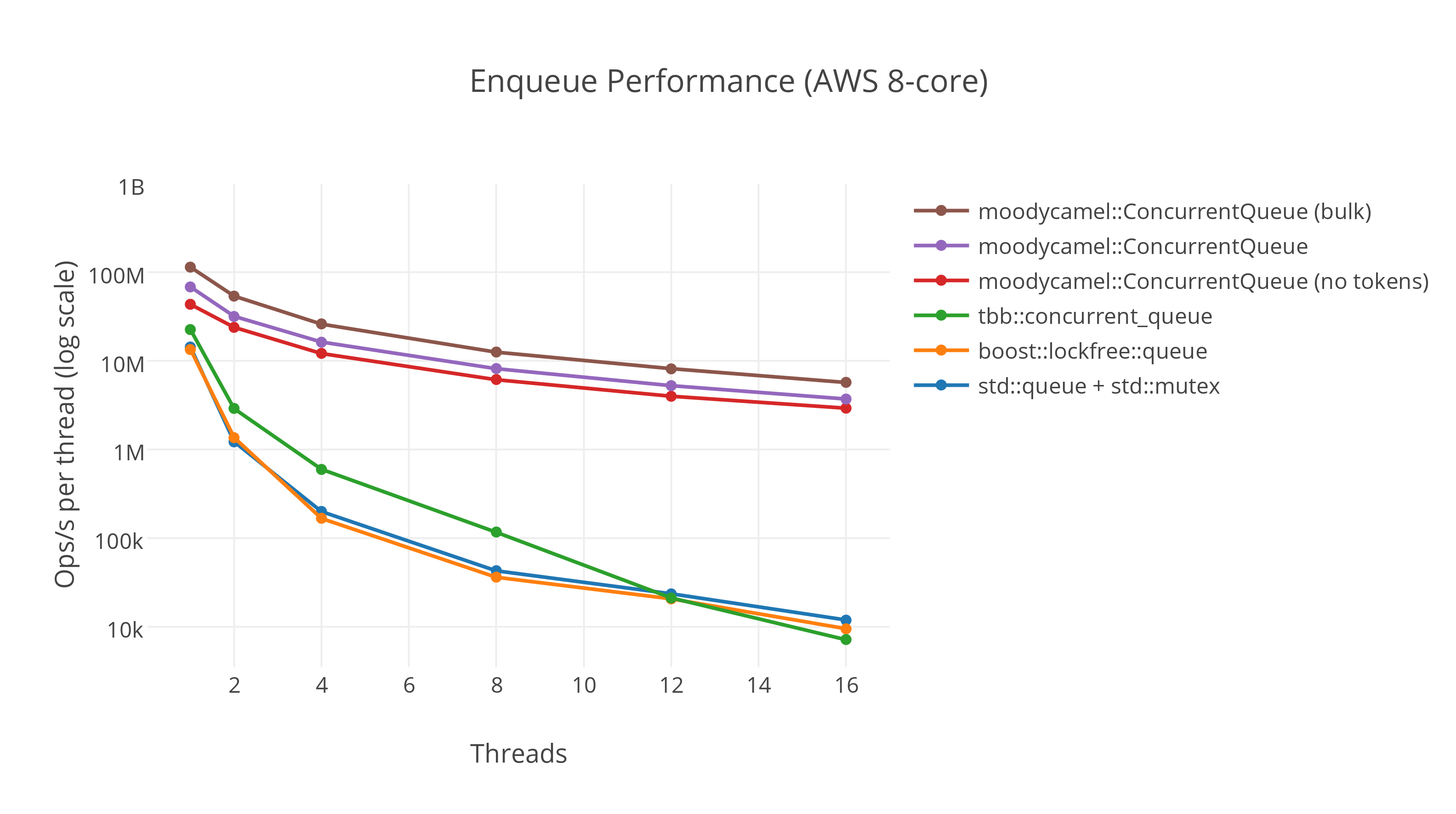
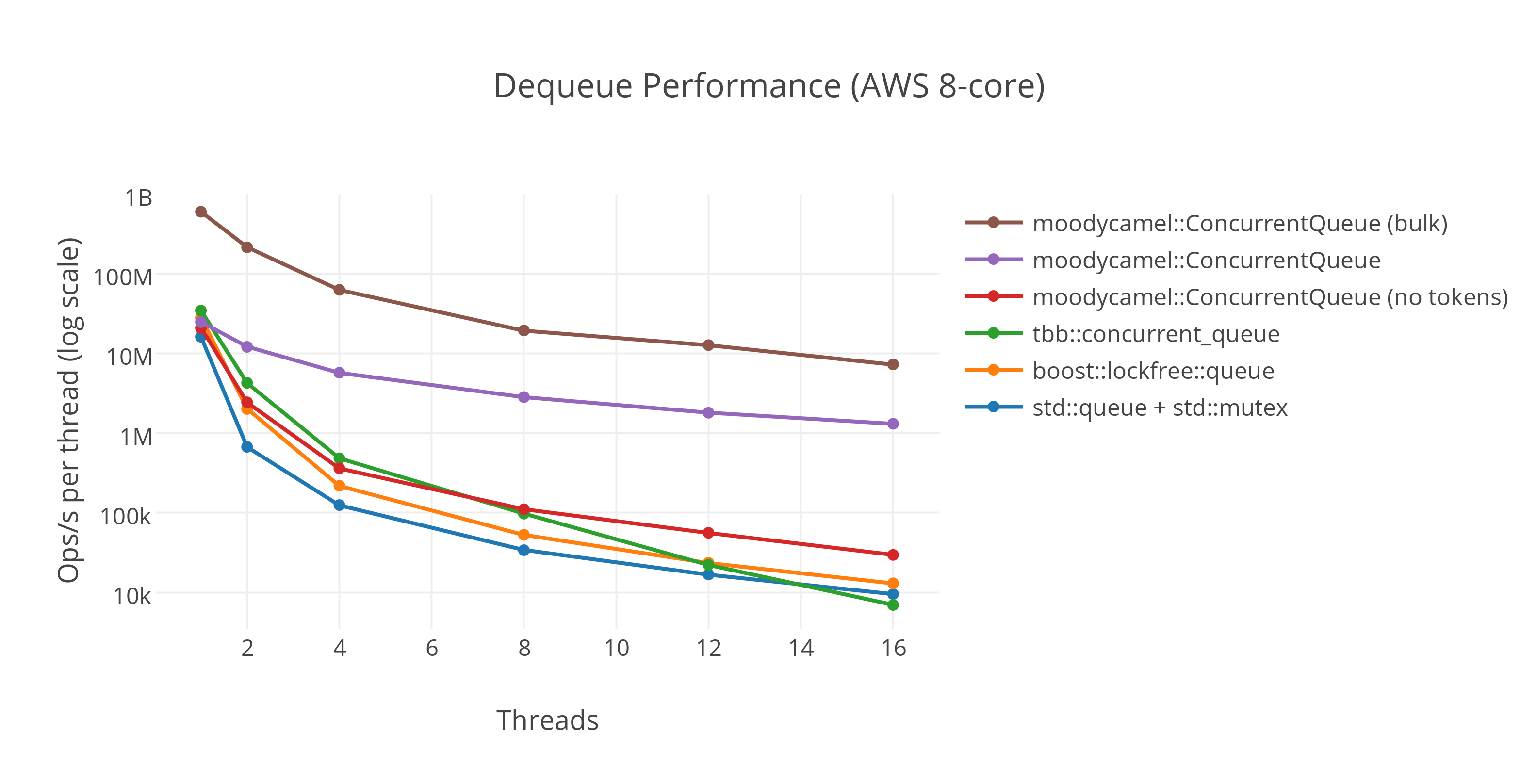
Test code: https://github.com/Smityz/multithreading Result analysis |

|
Maybe you can use atomic<T> in fine_level_capture, and define a struct, which has a map member |
|
When either coarse_level or fine_level run a period of time but no hot sub-partition or hot key detected, you should turn off |
|
A new idea of capture hotkey string(capture_fine_data)In the old design, we use try_lock and random selection to reduce the probability of lockup. It's a good idea but still has a lock. In the new design, we will have an exciting lock-free method to capture the huge data flow. Thread structureHow to allocate queue to the threadBy CAS we can handle this easily int find_queue(int threadID)
{
int t_size = size.load(memory_order_seq_cst);
for (int i=0;i<t_size;i++){
if (v[i]==threadID) return i;
}
while (!size.compare_exchange_weak(t_size, t_size + 1));
v[t_size] = threadID;
return t_size;
}How to ensure the thread-safety of queuesWe can use the producer-consumer queue to ensure thread safety meanwhile keeping high performance. https://github.com/cameron314/readerwriterqueue is recommended. We can also use |
Support hotspot key detection in Pegasus
Related PR #502
1 Background
At present, Pegasus lists the monitoring values for hotspot detection primitively, using manual methods for fault detection and troubleshooting, which is cumbersome for operation and maintenance. To make the data more visually presented, we have added a hotspot detection module #444 and #479, which scores relevant values of hotspot issues and feeds them back to falcon, reducing the burden of operation and maintenance. And in this Issue #495, I want to discuss the function of hotspot key detection.
This function is to find the possible hotspot key in the partition which hotspot detection algorithm recorded, and feed it back to the Ops, for timely troubleshooting.
At the same time, this work is also one of the solutions for hot data reading and writing problems.
2 Design
2.1 Timing diagram
2.2 How to start capturing data
According to #479, we can get a "hotspot_value" of each partition. We can set a threshold and if a partition's hotspot_value exceeded the threshold 3 times, the collector will send an RPC to the replica server.
2.2.1 First step
hotspot_calculator(in the collector) will check every partition's hotspot_value given by #479, if it is higher thanTHRESHOLD_OF_HOTSPOT_PARTITION_VALUEwe set (normally it would be 4), it will be recorded inglobal_read_count/global_write_count. This function will be started every time hotspot_value updated, which is carried out once a minute.2.2.2 Second step
hotspot_calculator(in the collector) will checkglobal_read_count/global_write_countstatus. Whenglobal_read_count/global_write_countis higher than theTHRESHOLD_OF_SEND_RPC_TO_DETECT_HOTKEY, which means these partitions are abnormal for threshold minutes, we will send an RPC to detect hotkey.2.3 How to capture data traffic
There are two points we need to pay attention to Thread-safety and low resource occupation
To reduce the load, we introduce a two-level model to filter data.
2.3.1 performance pre-test
According to the performance test, #495 (comment). I found that shunt data flow before try_lock can significantly improve efficiency. Use random sampling can further reduce latency.
2.3.2 RPC
Ref #495 (comment)
2.3.3 hotkey_collector
hotkey_collectoris used to capture and analyze data for one partition, it is running on the replica.hotkey_collectorhas four statuses:capture_data()andanalyse_data()have different frequencies, separate two functions contribute to improving efficiency.capture_data()will be executed in https://github.com/XiaoMi/pegasus/blob/b7492caceae817cfdb50a1a71d42de9d16c4a234/src/server/pegasus_server_impl.cpp#L573 and https://github.com/XiaoMi/pegasus/blob/b7492caceae817cfdb50a1a71d42de9d16c4a234/src/server/pegasus_server_impl.cpp#L562analyse_data()is a timing task.2.4 How to stop capturing data traffic
It can be terminated by timed out or by manual(send a RPC)
2.5 How to notify the result of hotkey detection
By logging in
derror(). We can search the specific error logs on the "hot" server or the collector.The text was updated successfully, but these errors were encountered: