-
Notifications
You must be signed in to change notification settings - Fork 28.2k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[SPARK-32855][SQL] Improve the cost model in pruningHasBenefit for fi…
…ltering side can not build broadcast by join type ### What changes were proposed in this pull request? This pr improve the cost model in `pruningHasBenefit` for filtering side can not build broadcast by join type: 1. The filtering side must be small enough to build broadcast by size. 2. The estimated size of the pruning side must be big enough: `estimatePruningSideSize * spark.sql.optimizer.dynamicPartitionPruning.pruningSideExtraFilterRatio > overhead`. ### Why are the changes needed? Improve query performance for these cases. This a real case from cluster. Left join and left size very small and right side can build DPP: 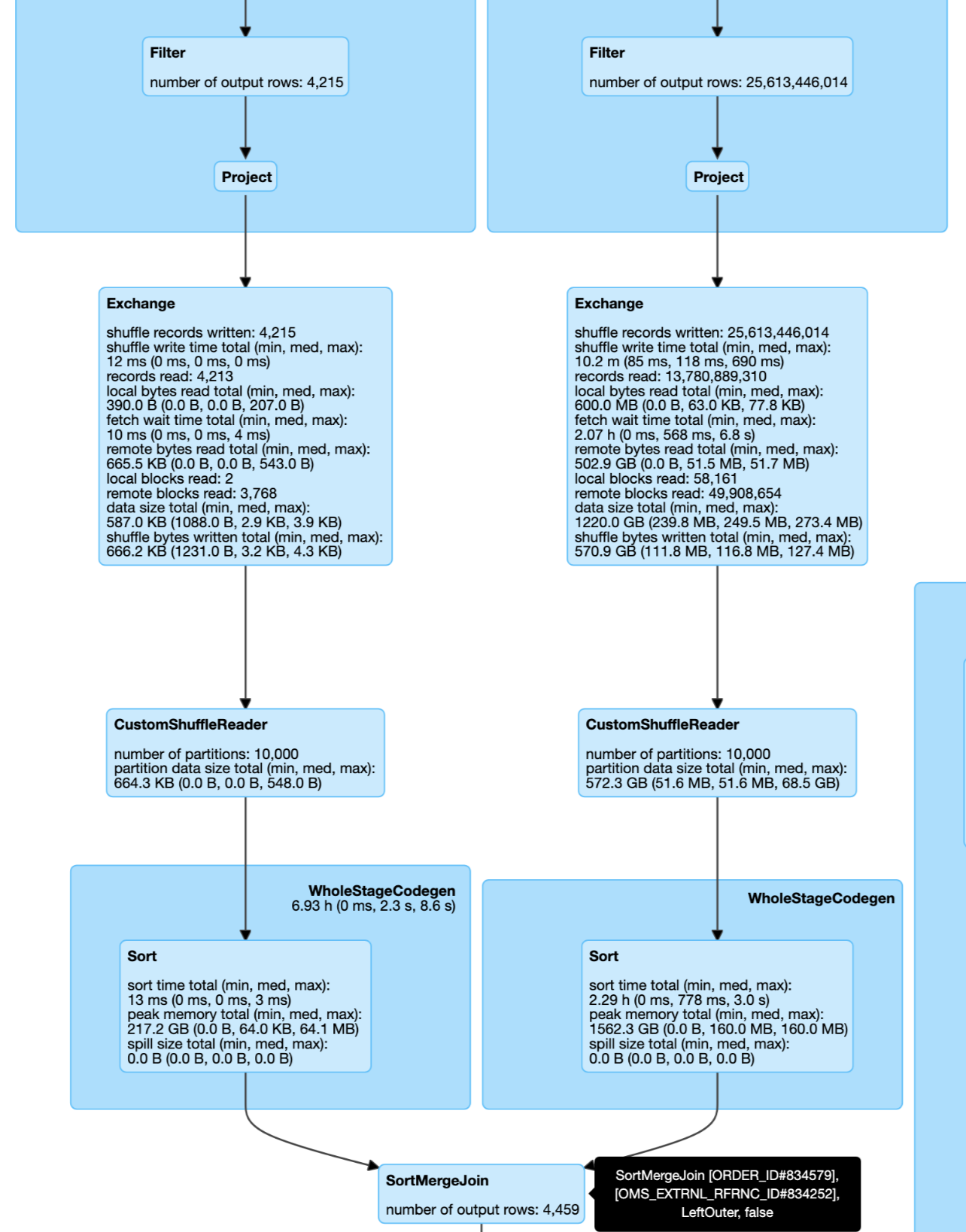 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. Closes #29726 from wangyum/SPARK-32855. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
- Loading branch information
Showing
3 changed files
with
71 additions
and
9 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters