Re-enable cuda texture object based access in regions kernel #1903
Conversation
src/backend/cuda/kernel/regions.hpp
Outdated
| //#if (__CUDA_ARCH__ >= 300) | ||
| #if 0 | ||
| // Kepler bindless texture objects | ||
| #if __CUDA_ARCH__ >= 300 |
There was a problem hiding this comment.
Can you actually drop this ? We don't support pre 3.0 compute anymore.
src/backend/cuda/regions.cu
Outdated
| cudaDeviceProp prop = getDeviceProp(getActiveDeviceId()); | ||
|
|
||
| //Use texture objects with compute 3.0 or higher | ||
| if (prop.major>=3 && prop.minor>=0 && !std::is_same<T,double>::value) { |
|
@arrayfire/core-devel This is ready for merge. |
examples/benchmarks/regions.cpp
Outdated
| } | ||
|
|
||
| return 0; | ||
| } |
src/backend/cuda/kernel/regions.hpp
Outdated
| @@ -23,8 +23,9 @@ | |||
| #include <thrust/sort.h> | |||
| #include <thrust/transform_scan.h> | |||
|
|
|||
| #if __CUDACC__ | |||
| #include <type_traits> | |||
There was a problem hiding this comment.
Not anymore, it was used in first commit but I removed it now. Will remove it.
src/backend/cuda/kernel/regions.hpp
Outdated
|
|
||
| #if __CUDACC__ |
There was a problem hiding this comment.
Not really. It wasn't added in this change, so I didn't notice this.
| cudaTextureDesc texDesc; | ||
| memset(&texDesc, 0, sizeof(texDesc)); | ||
| texDesc.readMode = cudaReadModeElementType; | ||
| CUDA_CHECK(cudaCreateTextureObject(&tex, &resDesc, &texDesc, NULL)); |
There was a problem hiding this comment.
You are not releasing the texture.
|
@9prady9 did you re-run the benchmarks after the texture free? The difference earlier has been fairly minimal. I wonder if this change affects the overall performance. |
|
@pavanky The the performance looks good. |
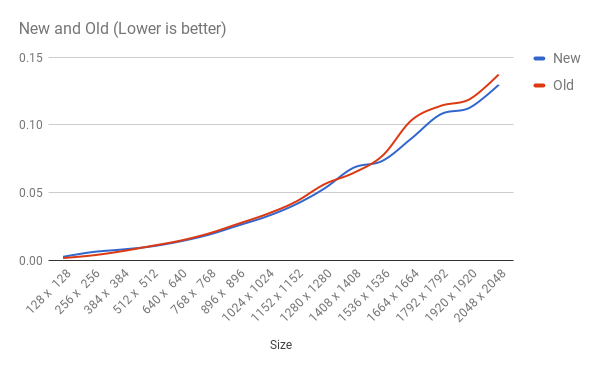
|
@pavanky If there is no additional feedback, I think this is ready for merge. |
|
@9prady9 can you close this PR and create a new one targeting v3.5 by cherry picking the appropriate commits? |
|
@9prady9 Nevermind, the problem is with the base branch. I am fixing v3.5 |
|
@9prady9 fixed now. |
|
The performance of this function depends on the input image. What input image did you use for this function? Can you test the performance where more iterations are required? How does it compare to the performance where there are only few iterations? Also, I am having trouble seeing how this access pattern takes advantage of the texture objects. Looks like you are loading into the shared memory so you are not taking advantage of the additional texture cache. You are using linear textures so you aren't taking advantage of the spatial locality accesses of Texture caches. I don't see a huge advantage to using this approach. Maybe it will be more pronounced in inputs with more iterations. |
|
Also we should probably be using cudaArray instead of cudaTextureObject. |
|
@umar456 There is an advantage to using texture objects for this section of code because it is doing 2D spatial access(reading more than one element per thread - I am not talking about per thread load) and textures surely have an advantage compared to global memory in that aspect. Does having the additional layer of shared memory reduce the performance ? It depends on whether shared memory has less latency compared to texture access. I think shared memory latency is better compared to texture access, but I am not certain of it. I had some benchmark sample using randomized input commited earlier, but removed it later and did a force push. Do you have any suggestion for the input you were talking about - the one that will cause regions to run more iterations ? @pavanky Is cudaArray similar to texture in performance ? I have seen couple of examples online where cudaArray_t is again wrapped around with cudaTextureObject_t. Not sure if it is equivalent in performance with textures. |
|
The benefits coming from texture memory seem to be fairly minimal at the moment. |
Remove pre-3.0-compute checks as we don't support 2.0 compute capability anymore
|
@pavanky @umar456 I have cleaned up more of it. I have tested the changes with two actual images(using timeit) and the improvement is around 20+%. One of them has lot of smaller regions(image with lot of text) and the other has huge but fewer regions.
|


There is no improvement except for some specific sizes. Note that I have run the benchmark on only 2^n sizes.
[skip arrayfire ci]