Machine Learning with PySpark
Goal - Make Practical Machine Learning Scalable & Easy
- ML Algorithms: common learning algorithms such as classification, regression, clustering, and collaborative filtering
- Featurization: feature extraction, transformation, dimensionality reduction, and selection
- Pipelines: tools for constructing, evaluating, and tuning ML Pipelines
- Persistence: saving and load algorithms, models, and Pipelines
- Utilities: linear algebra, statistics, data handling, etc.
- A Pipeline in PySpark ML is a concept of an end-to-end transformation-estimation process (with distinct stages) that ingests some raw data (in a DataFrame form), performs the necessary data carpentry (transformations), and finally estimates a statistical model (estimator).
- A Pipeline can be purely transformative, that is, consisting of Transformers only. MLlib standardizes APIs for machine learning algorithms to make it easier to combine multiple algorithms into a single pipeline.
- DataFrame - Storage mechanism
- Transformer - An algorithm which converts one DataFrame to another DF. Eg. model is a transformer
- Estimator - Creates transformer using fit on a DataFrame. learning algo is a estimator which trans on a DF & produces a model
- Pipeline - Chains multiple Transformer & Estimators to create a flow.
- Parameters - Input to Transformers & Estimators
- Transformer implements a method transform(), which converts one DataFrame into another, generally by appending one or more columns.
- Feature transformer might take a dataframe & converts into another dataframe with new columns using available columns
- New dataframes with new cols only & no previous cols.
- an Estimator implements a method fit(), which accepts a DataFrame and produces a Model, which is a Transformer
- Eg - LogisticRegression is an estimator, and calling fit on it creates a LogisticRegressionModel, which is a Mode & hence a transformer.
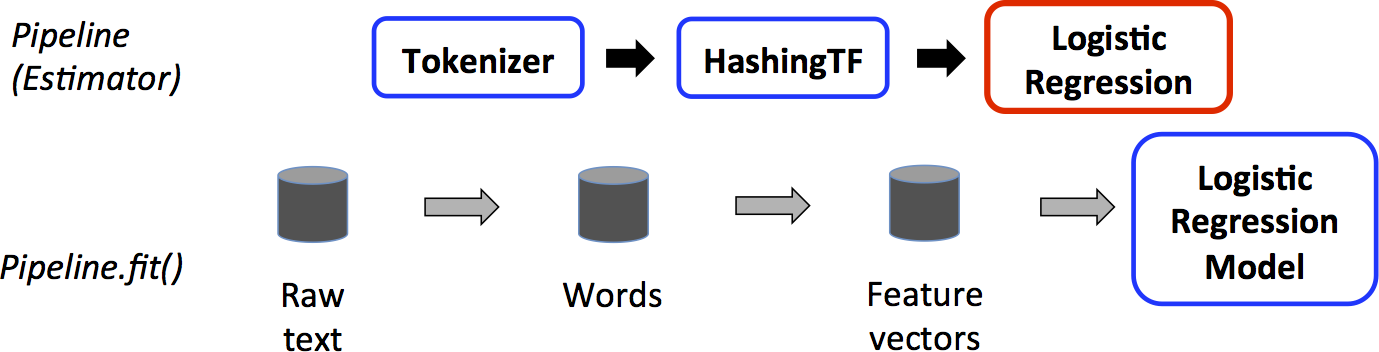
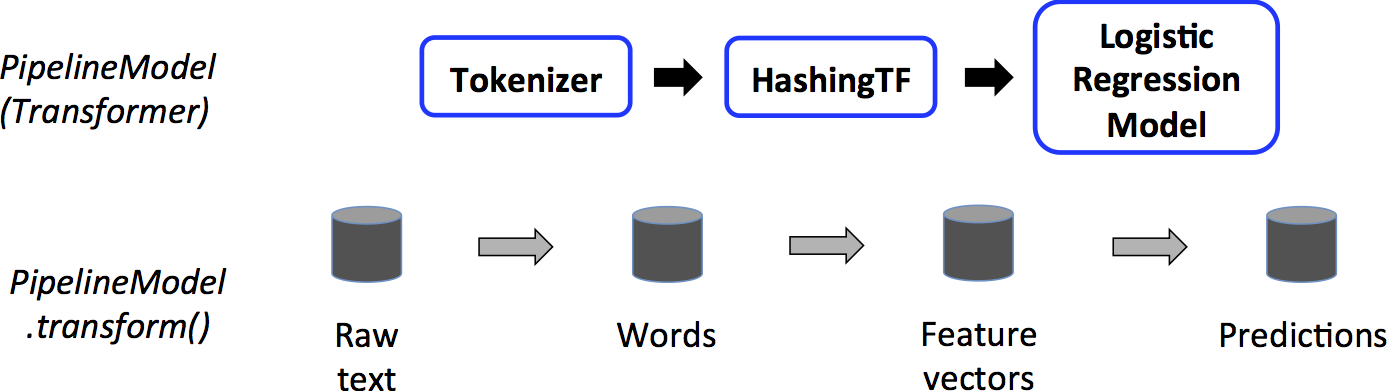
- MLlib Estimators and Transformers use a uniform API for specifying parameters.
- Pipelines & Models once created can be persisted in a location.
- Persisted pipelines/models can be loaded & used again.
- Pipelines/Models can be created using R & used using Scala/Python or vice-versa.