栈的结构可以看看深入理解操作系统,里面有关于栈的具体代码执行中的分配情况,更容易理解js的执行上下文

看一个例子:
(function foo(i) {
if (i === 3) {
return;
}
else {
foo(++i);
}
}(0));

一个函数调用就会在栈中创建一个栈帧。然而,我们主要关心的是在js层面,在解释器的内部,每次调用执行环境会有两个阶段:
- 创建阶段
- 初始化作用域链
- 创建变量、函数和参数
- 创建arguments object,检查上下文获取入参,初始化形参名称和数值,并创建一个引用拷贝
- 扫描上下文获取内部函数声明:发现一个函数就在variable object中创建一个和函数名一样的属性,该属性作为一个引用的指针指向函数
- 如果在variable object中已经存在了相同名称的属性,那么属性会重写
- 对发现的每一个内部变量的声明,都在variable object中创建一个和变量名一样的属性,并将其初始化undefine
- 如果在对象中发现已经存在相同变量名称的属性,那么就跳过,不做任何操作,继续扫描
- 确定this的值
- 激活/代码执行阶段
-
执行上下文中的函数代码,逐行运行js代码,并给变量赋值
executionContextObj = { scopeChain: { /* variableObject + all parent execution context's variableObject */ }, //作用域链:{变量对象+所有父执行环境的变量对象} variableObject: { /* function arguments / parameters, inner variable and function declarations */ }, //变量对象:{函数形参+内部的变量+函数声明(但不包含表达式)} this: {}
看一个例子:
function foo(i) {
var a = 'hello';
var b = function privateB() {
};
function c() {
}
}
foo(22);
当刚调用foo(22)函数的时候,创建阶段的上下文大致是下面的样子:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: { // 创建了参数对象
0: 22,
length: 1
},
i: 22, // 检查上下文,创建形参名称,赋值/或创建引用拷贝
c: pointer to function c() // 检查上下文,发现内部函数声明,创建引用指向函数体
a: undefined, // 检查上下文,发现内部声明变量a,初始化为undefined
b: undefined // 检查上下文,发现内部声明变量b,初始化为undefined,此时并不赋值,右侧的函数作为赋值语句,在代码未执行前,并不存在
},
this: { ... }
}
在执行完后的上下文大致如下:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: 'hello',
b: pointer to function privateB()
},
this: { ... }
}
其实你如果理解了线程的问题,你就知道线程才是真正的并行,一般的思路就是用多线程来实现异步
当你同时要做两件事儿的时候,他们是执行在不同的线程中去,这就像柜台卖东西,来了一个人就得找一个员工陪他,直到这个人走了这个员工才能接待下一个客人
店内的员工就像线程池中的空闲的线程一样,空闲的时候可以去接待客人,课时同时只能接待一个人,要接待其他的人就得开辟一个线程
这种实在是非常的耗费系统的资源,于是浏览器实际是单线程的,也就是说同一时间只做一件事儿,这点跟apache是不一样的,apache是一个典型的多线程的服务器,每一个请求都会有一个线程单独处理,但是作为浏览器而言,javascript主要的用途是跟用户互动以及操作DOM。如果他是多线程的话,那么就会很麻烦,假定有两个线程,一个添加内容,一个删除内容,这时候浏览器就要考虑线程的同步问题了
所以,我们需要考虑在单线程的情况下,如何实现异步?
单线程就意味着,所有任务都需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务很耗时,后一个任务就不得不一直等着
如果排队是因为计算量大,CPU忙不过来,倒也算了,但是很多时候CPU都是闲着,因为IO设备很慢(比如ajax操作从网络读取数据),不得不等结果出来,再往下执行
javascript语言的设计者意识到,这时候主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回头把挂起的任务继续执行下去
于是,所有的任务就分成了两种,一种是同步任务,一种是异步任务,同步任务指的是,在主线程中排队执行的任务,只有前一个任务执行完毕后才能执行后一个任务。异步任务指的是,不进入主线程,而进入"任务队列"的任务,只有任务队列通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行
主线程从任务队列中读取事件,这个过程是循环不断的,所以,整个运行机制就是Event Loop(事件循环)
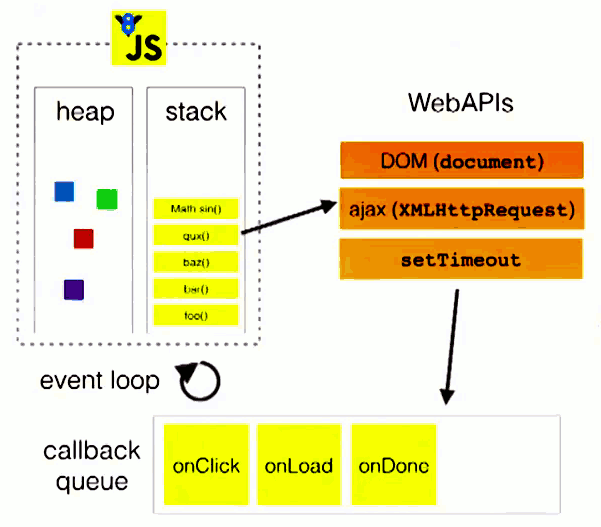
像是这样:
// `eventLoop` is an array that acts as a queue (first-in, first-out)
var eventLoop = [ ];
var event;
// keep going "forever"
while (true) {
// perform a "tick"
if (eventLoop.length > 0) {
// get the next event in the queue
event = eventLoop.shift();
// now, execute the next event
try {
event();
}
catch (err) {
reportError(err);
}
}
}
宏队列,macrotask,也叫task,一些异步的任务的回调会进入macro task queue
- setTimeout
- setInterval
- setImmediate
- requestAnimationFrame
- I/O
- UI rendering(浏览器独有)
微队列,microtask,也叫jobs,另一些异步任务的回调会进入micro task queue
- process.nextTick(Node独有)
- Promise
- Object.observe
- MutationObserve

让我们看一下一个代码执行的具体流程:
- 执行全局script同步代码,这些同步代码执行完毕后,调用栈清空(有几个函数就有几个栈帧)
- 从微队列中取出位于队首的回调任务,放入执行栈中执行,长度减一
- 继续取出位于队首的任务,放入调用栈中执行,直到把微队列中的所有任务执行完毕。如果这时候在执行的时候产生了新的微任务,那么会加入到队列的末尾,也会在这个周期被调用执行
- 所有的微队列的任务执行完毕的时候,此时队列为空,调用栈为空
- 取出宏队列中位于队首的任务,放入栈中执行
- 执行完毕后,调用栈为空
- 重复3-7的过程
这就是浏览器的事件循环Event Loop
实例代码理解:
console.log(1); //同步代码
//第一个宏任务
setTimeout(() => {
console.log(2);
Promise.resolve().then(() => {
console.log(3) //第二个微任务
});
});
new Promise((resolve, reject) => {
console.log(4) //同步代码
resolve(5)
}).then((data) => {
console.log(data); //第一个微任务
})
//第二个宏 任务
setTimeout(() => {
console.log(6);
})
console.log(7); // 同步代码
简单的说,就是微任务 ---> 第一个宏任务 ---> 微任务 ---> 第二个宏任务 ----> 不断循环
先来看nodeJS中的libuv的结构图:

nodeJS中执行宏任务有6个阶段:

各个阶段执行的任务如下:
- timers阶段:这个阶段执行setTimeout和setinterval预定的callback
- I/O callback阶段:执行除了close事件的callbacks、被timers设定的callbacks、setImmediate()设定的callbacks这些之外的callbacks
- idle,prepare阶段:仅node内部使用
- poll阶段:获取新的I/O事件,适当的条件下node会阻塞
- check阶段:执行setImmediate()设置的callbacks
- close callback阶段:执行socket.on('close')这些
你可以理解为在node中宏任务有很多种,但在浏览器中只有一种
不同的宏任务会放在不同的宏队列里面
nodejs中微队列主要有两个:
- next tick queue 是放置process.nextTick回调任务
- 其他的:比如promise
你可以理解为浏览器只有一个微任务队列,而在nodeJS中有两个

大体解释下nodeJS的event loop过程:
- 执行全局的script同步代码
- 执行微任务,先执行所有的next tick 中的所有任务,再执行类似于promise之类的微任务
- 开始执行宏任务,一共6个阶段,从第一阶段开始执行相应每一个阶段宏任务中的所有任务,注意,这里是所有每个阶段的宏任务队列的所有任务,在浏览器中只是取出第一个宏任务,每一个阶段的宏任务执行完毕后,开始执行微任务
- 微任务nextTick--->微任务Promise---->timers阶段 ---> 微任务 ---> I/O阶段 ---> 微任务 --> check阶段 ---> 微任务 ---> close阶段 --> 微任务 --> 重新回到timers阶段 ---> 继续循环


看一个例子:
console.log('1'); //同步代码
//timer阶段的宏任务1
setTimeout(function() {
console.log('2');
process.nextTick(function() {
console.log('3');
})
new Promise(function(resolve) {
console.log('4');
resolve();
}).then(function() {
console.log('5')
})
})
//微任务Promise
new Promise(function(resolve) {
console.log('7');
resolve();
}).then(function() {
console.log('8')
})
//微任务nextTick
process.nextTick(function() {
console.log('6');
})
//timer阶段的宏任务2
setTimeout(function() {
console.log('9');
process.nextTick(function() {
console.log('10');
})
new Promise(function(resolve) {
console.log('11');
resolve();
}).then(function() {
console.log('12')
})
})
总结:
-
浏览器可以理解成只有1个宏任务队列和1个微任务队列,先执行全局Script代码,执行完同步代码调用栈清空后,从微任务队列中依次取出所有的任务放入调用栈执行,微任务队列清空后,从宏任务队列中只取位于队首的任务放入调用栈执行,注意这里和Node的区别,只取一个,然后继续执行微队列中的所有任务,再去宏队列取一个,以此构成事件循环。
-
NodeJS可以理解成有4个宏任务队列和2个微任务队列,但是执行宏任务时有6个阶段。先执行全局Script代码,执行完同步代码调用栈清空后,先从微任务队列Next Tick Queue中依次取出所有的任务放入调用栈中执行,再从微任务队列Other Microtask Queue中依次取出所有的任务放入调用栈中执行。然后开始宏任务的6个阶段,每个阶段都将该宏任务队列中的所有任务都取出来执行(注意,这里和浏览器不一样,浏览器只取一个),每个宏任务阶段执行完毕后,开始执行微任务,再开始执行下一阶段宏任务,以此构成事件循环。
-
MacroTask包括: setTimeout、setInterval、 setImmediate(Node)、requestAnimation(浏览器)、IO、UI rendering
-
Microtask包括: process.nextTick(Node)、Promise、Object.observe、MutationObserver
流是一种数据传输手段,是有顺序的,有起点和终点,比如你要把数据从一个地方传到另外一个地方
流非常的重要,gulp/webpack/http里面的请求和响应,http里的socket都是流,包括后面的压缩和加密
有时候我们不关于文件的主体内容,只关心能不能取到数据,取到数据后应该怎么处理
对于小型的文本文件,我们可以把文件的内容全部读入内存,然后再写入文件
对于体积较大的二进制文件,比如音频、视频文件,动辄好几个G大小,如果使用这种方法,很容易让内存爆仓
理想的方法是读一部分,写一部分,不管文件有多大,只要时间允许,总会处理完成
个人对于流的理解:首先实现流必须要理解文件的读写,而操作系统是用open/read/write实现文件的读写的
在nodejs中有四种流:
- Readable - 可读的流 (例如 fs.createReadStream()).
- Writable - 可写的流 (例如 fs.createWriteStream()).
- Duplex - 可读写的流 (例如 net.Socket).
- Transform - 在读写过程中可以修改和变换数据的 Duplex 流 (例如 zlib.createDeflate()).

资源的数据流并不是直接流向消费者,而是先push到缓存池,缓存池有一个水位标记highWatermark,超过这个标记阈值,push的时候会返回flase,从而控制读取数据流的速度,如同水管上的阀门,当水管面装满了水,就暂时关上阀门,不再从资源里抽水出来
- 消费者主动执行了pause()
- 消费速度比数据push到缓存池的生产速度慢

这是puase模式下的可读流,在这种模式下可读流有三个状态
- readable._readableState.flowing = null 目前没有数据消费者,所以不会从资源中读取数据
- readable._readableState.flowing = false 暂停从资源库读取数据,但不会暂停数据生成,主动触发readable.puase()方法,readable.unpip()方法或者接收"背压"可达到此状态
- readable._readableState.flowing = true 正在从资源中读取数据,监听"data"事件,调用readable.pipe()方法或者调用readable.resume()方法可达到此状态
这种模式下,需要显式的调用read方法来读取数据,readable状态只是代表着有数据可读,要读还是要调用read方法

数据流过来的时候,会直接写入到资源池,当写入速度比较缓慢或者写入暂停时,数据流会进入队列池缓存起来,当生产者写入速度过快,把队列池装满了之后,就会出现背压,这个时候是需要告诉生产者暂停生产,当队列释放完毕后,会给生产者发送一个drain消息,让他恢复生产
write方法向流中写入数据,并在数据处理完毕后调用callback.在确认了chunk后,如果内部缓冲区的大小小于创建流时设定的highWaterMark阈值,函数返回true.如果返回值为false(队列池已经满了),应该停止向流中写数据,直到drain事件触发
commonJS规范API:
require:加载所要依赖的其他模块 module.exports 或者 exports:对外暴露接口
特点:
- 模块输出的是一个值的拷贝,模块是运行时加载,同步加载
- CommonJS模块的顶层this指向当前模块
- exports是对module.exports的引用,不能直接给exports赋值,直接赋值无效
- 一个文件不能写多个module.exports,如果写多个,对外暴露的接口是最后一个
- 模块如果没有指定使用Module.exports或者exports对外暴露接口,在其他文件中引用该模块,得到的就是个空的对象
问题:
//创建两个文件,module1.js 和 module2.js,并且让它们相互引用
// module1.js
exports.a = 1;
require('./module2');
exports.b = 2;
exports.c = 3;
// module2.js
const Module1 = require('./module1');
console.log('Module1 is partially loaded here', Module1);
在 module1 完全加载之前需要先加载 module2,而 module2 的加载又需要 module1。这种状态下,我们从 exports 对象中能得到的就是在发生循环依赖之前的这部分。上面代码中,只有 a 属性被引入,因为 b 和 c 都需要在引入 module2 之后才能加载进来。
Node 使这个问题简单化,在一个模块加载期间开始创建 exports 对象。如果它需要引入其他模块,并且有循环依赖,那么只能部分引入,也就是只能引入发生循环依赖之前所定义的这部分。
AMD规范API:
define(id?,[]?,callback) 定义声明模块,参数id,模块id标识(可选),参数二是一个数组(可选),依赖其他的模块,最后是回调函数
require([module],callback) 加载模块,参数1是数组,指定加载的模块,参数2是回调函数,模块加载完毕后执行
require.config({
baseUrl://基础路径
path://对象,对外加载的模块名称
shim://对象,配置非AMD模式的文件
})
特点:异步加载,不会阻塞页面的加载,能并行加载多个模块,但是不能按需加载,必须提前加载所需依赖
ES6规范API:
export 用于规定模块的对外接口
import 用与输入其他模块提供的功能
特点:
- 顶层的this指向undefined,即不应该在顶层代码中使用this
- 自动采用严格模式 ”use strict“
- 静态化,编译时加载或者静态加载,编译时候输出接口
- export/import必须处于模块的顶层
- 模块输出的是值的引用
问题:
ES6 中,imports 是 exprts 的只读视图,直白一点就是,imports 都指向 exports 原本的数据,比如:
//------ lib.js ------
export let counter = 3;
export function incCounter() {
counter++;
}
//------ main.js ------
import { counter, incCounter } from './lib';
// The imported value `counter` is live
console.log(counter); // 3
incCounter();
console.log(counter); // 4
// The imported value can’t be changed
counter++; // TypeError
因此在 ES6 中处理循环引用特别简单,看下面这段代码:
//------ a.js ------
import {bar} from 'b'; // (1)
export function foo() {
bar(); // (2)
}
//------ b.js ------
import {foo} from 'a'; // (3)
export function bar() {
if (Math.random()) {
foo(); // (4)
}
}
假设先加载模块 a,在模块 a 加载完成之后,bar 间接性地指向的是模块 b 中的 bar。无论是加载完成的 imports 还是未完成的 imports,imports 和 exports 之间都有一个间接的联系,所以总是可以正常工作。
异步的实现这里就不再叙述了,这里要分析的是异步代码管理的几种写法:
我们要控制异步,让他能跟同步一样
- 回调函数(简单来说,就是在一个异步任务的回调函数中再套一个异步任务,根据程序的执行顺序,永远都会先执行同步代码,第一个异步任务的代码首先被执行,剩下的就是第二个异步任务了,简单吧,实现的话通过setTimeout你可以很轻松的把一个函数变成一个异步的任务)
- 事件监听(事件也是宏任务,但是实现来说的话,事件是需要手动触发的,自己实现一下很容易)
- Promise(无非还是callback,只不过改了一种顺眼的写法而已了,它严格上来讲也是因为回调实现的,实现一个也非常的轻松)
- Generator(实现原理确认是跟栈帧有关系的)
- async/await(是在generator的基础上的语法糖)
ES6中引入了很多此前没有的概念,Iterator就是其中一个。它是一个指针对象,类似于单项链表的数据结构,通过next()将指针指向下一个节点
我们可以定义一个数组,然后生成数组的Iterator对象
const arr = [100,200,300]
const iterator = arr[Symbol.iterator]()
好,我现在已经生成了一个数组的Iterator对象,有两种方式使用它:next 和for...of
console.log(iterator.next()) // { value: 100, done: false }
console.log(iterator.next()) // { value: 200, done: false }
console.log(iterator.next()) // { value: 300, done: false }
console.log(iterator.next()) // { value: undefined, done: true }
在看第二种:
let i
for (i of iterator) {
console.log(i)
}
// 打印:100 200 300
执行const h = Hello()得到的就是一个iterator对象,因为h[Symbol.iterator]是有值的,那么就可以用next()和for...of进行操作
function* Hello() {
yield 100
yield (function () {return 200})()
return 300
}
const h = Hello()
console.log(h[Symbol.iterator]) // [Function: [Symbol.iterator]]
下面是结果:
console.log(h.next()) // { value: 100, done: false }
console.log(h.next()) // { value: 200, done: false }
console.log(h.next()) // { value: 300, done: false }
console.log(h.next()) // { value: undefined, done: true }
let i
for (i of h) {
console.log(i)
}
下面我们来分析一下所有的步骤:
- Generator不是函数,不是函数,不是函数
- hello()不会立即出发执行,而是一上来暂停
- 每次h.next()都会打破暂停状态去执行,直到遇到下一个yield或者return
- 遇到yield时候,会执行yield后面的表达式,并返回执行之后的值,然后再次进入暂停状态,此时done:false
- 遇到return时,会返回值,执行结束,即done:true
- 每次h.next()的返回值都是{value:....,done:....}的形式
next和yield参数传递
我们之前已经知道,yield具有返回数据的功能。yield后面的数据被返回,存放到返回结果的value属性中
function* G() {
yield 100
}
const g = G()
console.log( g.next() ) // {value: 100, done: false}
还有另外一个方向的参数传递,就是next向yield传递
function* G() {
const a = yield 100
console.log('a', a) // a aaa
const b = yield 200
console.log('b', b) // b bbb
const c = yield 300
console.log('c', c) // c ccc
}
const g = G()
g.next() // value: 100, done: false
g.next('aaa') // value: 200, done: false
g.next('bbb') // value: 300, done: false
g.next('ccc') // value: undefined, done: true
- 执行第一个g.next()时,为传递任何参数,返回的{value: 100, done: false},这个应该没有疑问
- 执行第二个g.next('aaa')时,传递的参数是'aaa',这个'aaa'就会被赋值到G内部的a标量中,然后执行console.log('a', a)打印出来,最后返回{value: 200, done: false}
- 执行第三个、第四个时,道理都是完全一样的,大家自己捋一捋。
有一个要点需要注意,就g.next('aaa')是将'aaa'传递给上一个已经执行完了的yield语句前面的变量,而不是即将执行的yield前面的变量。这句话要能看明白,看不明白就说明刚才的代码你还没看懂,继续看。
普通函数在被调用时,JS引擎会创建一个栈帧,在里面准备好局部变量、函数参数、临时值、代码执行的位置(也就是说这个函数的第一行对应到代码区里的第几行机器码),在当前栈帧里设置好返回位置,然后将新帧压入栈顶。待函数执行结束后,这个栈帧将被弹出栈然后销毁,返回值会被传给上一个栈帧。
当执行到yield语句时,Generator的栈帧同样会被弹出栈外,但Generator在这里耍了个花招——它在堆里保存了栈帧的引用(或拷贝)!这样当iter.next方法被调用时,JS引擎便不会重新创建一个栈帧,而是把堆里的栈帧直接入栈。因为栈帧里保存了函数执行所需的全部上下文以及当前执行的位置,所以当这一切都被恢复如初之时,就好像程序从原本暂停的地方继续向前执行了。
而因为每次yield和iter.next都对应一次出栈和入栈,所以可以直接利用已有的栈机制,实现值的传出和传入。
这就是Generator魔法背后的秘密!

koa的实现步骤:
- 封装node http server
- 构造request,response,context对象
- 中间件机制
- 错误处理
// application.js
let http = require('http');
class Application {
/**
* 构造函数
*/
constructor() {
this.callbackFunc;
}
/**
* 开启http server并传入callback
*/
listen(...args) {
let server = http.createServer(this.callback());
server.listen(...args);
}
/**
* 挂载回调函数
* @param {Function} fn 回调处理函数
*/
use(fn) {
this.callbackFunc = fn;
}
/**
* 获取http server所需的callback函数
* @return {Function} fn
*/
callback() {
return (req, res) => {
this.callbackFunc(req, res);
};
}
}
module.exports = Application;
request是对node原生request的封装,response是对node原生response的封装,context对象则是回调函数上下文对象,挂载了request和response对象
首先创建request.js
// request.js
let url = require('url');
module.exports = {
get query() {
return url.parse(this.req.url, true).query;
}
};
很简单,就是导出一个对象,其中包含query的读取方法,用this.req.url是原生获取url的方法
然后创建response.js
// response.js
module.exports = {
get body() {
return this._body;
},
/**
* 设置返回给客户端的body内容
*
* @param {mixed} data body内容
*/
set body(data) {
this._body = data;
},
get status() {
return this.res.statusCode;
},
/**
* 设置返回给客户端的stausCode
*
* @param {number} statusCode 状态码
*/
set status(statusCode) {
if (typeof statusCode !== 'number') {
throw new Error('statusCode must be a number!');
}
this.res.statusCode = statusCode;
}
};
也很简单,status读取方法分别设置或读取this.res.statusCode ,body的读写方法分别设置this._data的属性
然后创建context.js
// context.js
module.exports = {
get query() {
return this.request.query;
},
get body() {
return this.response.body;
},
set body(data) {
this.response.body = data;
},
get status() {
return this.response.status;
},
set status(statusCode) {
this.response.status = statusCode;
}
};
可以看到主要是做一些常用方法的代理,通过context.query直接代理了context.request.query,context.body和context.status代理了context.response.body与context.response.status。而context.request,context.response则会在application.js中挂载
// application.js
let http = require('http');
let context = require('./context');
let request = require('./request');
let response = require('./response');
class Application {
/**
* 构造函数
*/
constructor() {
this.callbackFunc;
this.context = context;
this.request = request;
this.response = response;
}
/**
* 开启http server并传入callback
*/
listen(...args) {
let server = http.createServer(this.callback());
server.listen(...args);
}
/**
* 挂载回调函数
* @param {Function} fn 回调处理函数
*/
use(fn) {
this.callbackFunc = fn;
}
/**
* 获取http server所需的callback函数
* @return {Function} fn
*/
callback() {
return (req, res) => {
let ctx = this.createContext(req, res);
let respond = () => this.responseBody(ctx);
this.callbackFunc(ctx).then(respond);
};
}
/**
* 构造ctx
* @param {Object} req node req实例
* @param {Object} res node res实例
* @return {Object} ctx实例
*/
createContext(req, res) {
// 针对每个请求,都要创建ctx对象
let ctx = Object.create(this.context);
ctx.request = Object.create(this.request);
ctx.response = Object.create(this.response);
ctx.req = ctx.request.req = req;
ctx.res = ctx.response.res = res;
return ctx;
}
/**
* 对客户端消息进行回复
* @param {Object} ctx ctx实例
*/
responseBody(ctx) {
let content = ctx.body;
if (typeof content === 'string') {
ctx.res.end(content);
}
else if (typeof content === 'object') {
ctx.res.end(JSON.stringify(content));
}
}
}
可以看到,最主要的是增加了createContext方法,基于我们之前创建的context 为原型,使用Object.create(this.context)方法创建了ctx,并同样通过Object.create(this.request)和Object.create(this.response)创建了request/response对象并挂在到了ctx对象上面。此外,还将原生node的req/res对象挂载到了ctx.request.req/ctx.req和ctx.response.res/ctx.res对象上。
回过头去看我们之前的context/request/response.js文件,就能知道当时使用的this.res或者this.response之类的是从哪里来的了,原来是在这个createContext方法中挂载到了对应的实例上。一张图来说明其中的关系:
构建了运行时上下文ctx之后,我们的app.use回调函数参数就都基于ctx了。
/**
* @file simpleKoa application对象
*/
let http = require('http');
let context = require('./context');
let request = require('./request');
let response = require('.//response');
class Application {
/**
* 构造函数
*/
constructor() {
this.middlewares = [];
this.context = context;
this.request = request;
this.response = response;
}
// ...省略中间
/**
* 中间件挂载
* @param {Function} middleware 中间件函数
*/
use(middleware) {
this.middlewares.push(middleware);
}
/**
* 中间件合并方法,将中间件数组合并为一个中间件
* @return {Function}
*/
compose() {
// 将middlewares合并为一个函数,该函数接收一个ctx对象
return async ctx => {
function createNext(middleware, oldNext) {
return async () => {
await middleware(ctx, oldNext);
}
}
let len = this.middlewares.length;
let next = async () => {
return Promise.resolve();
};
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
await next();
};
}
/**
* 获取http server所需的callback函数
* @return {Function} fn
*/
callback() {
return (req, res) => {
let ctx = this.createContext(req, res);
let respond = () => this.responseBody(ctx);
let fn = this.compose();
return fn(ctx).then(respond);
};
}
// ...省略后面
}
module.exports = Application;
可以看到,首先对app.use进行改造了,每次调用app.use,就向this.middlewares中push一个回调函数。然后增加了一个compose()方法,利用我们前文分析的原理,对middlewares数组中的函数进行组装,返回一个最终的函数。最后,在callback()方法中,调用compose()得到最终回调函数,并执行
/**
* @file simpleKoa application对象
*/
let EventEmitter = require('events');
let http = require('http');
let context = require('./context');
let request = require('./request');
let response = require('./response');
class Application extends EventEmitter {
/**
* 构造函数
*/
constructor() {
super();
this.middlewares = [];
this.context = context;
this.request = request;
this.response = response;
}
// ...
/**
* 获取http server所需的callback函数
* @return {Function} fn
*/
callback() {
return (req, res) => {
let ctx = this.createContext(req, res);
let respond = () => this.responseBody(ctx);
let onerror = (err) => this.onerror(err, ctx);
let fn = this.compose();
// 在这里catch异常,调用onerror方法处理异常
return fn(ctx).then(respond).catch(onerror);
};
}
// ...
/**
* 错误处理
* @param {Object} err Error对象
* @param {Object} ctx ctx实例
*/
onerror(err, ctx) {
if (err.code === 'ENOENT') {
ctx.status = 404;
}
else {
ctx.status = 500;
}
let msg = err.message || 'Internal error';
ctx.res.end(msg);
// 触发error事件
this.emit('error', err);
}
}
module.exports = Application;
详细的源代码可以查看simpleKoa文件夹
牢记内存四区:全局区、代码区、堆区、栈区
全局区的变量是在程序执行完毕后释放的,也就是你关闭页面后消失的。而栈里面的数据是当函数执行完毕后浏览器自动回收的
堆区的变量是需要手动回收的,代码区存放一条一条执行的指令
程序执行过程中的栈结构:main函数位于栈底---->执行一个函数就压入栈(函数的栈帧)----->函数参数首先入栈 -----> 返回地址入栈 ------> 被保存的寄存器的值(main函数中可能有些值是存在寄存器中的,所以要保存一下)-----> 局部变量 -----> 参数构造区(该函数要传递出去的参数)
内存泄漏是指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况
内存泄漏的几种情况:
1) 全局变量
a = 10;
global.b = 11;
这种比较简单的原因,是因为全局的变量只能在代码执行完毕后才会被清除掉
2) 闭包
function out(){
const bigData = new Buffer(10);
inner = function(){
void bigData;
}
}
闭包会引用到父级函数中的变量,如果闭包未被释放,就会导致内存泄漏。上面的例子是inner直接挂在了root上,从而导致内存泄漏(bigData不会释放)
3) 事件监听
事件监听也可能出现内存泄漏。例如对同一个事件重复监听,忘记移除,将造成内存泄漏。例如nodejs中的Agent的keep-alive为true的时候
分析nodeJS中的内存泄漏可以通过内存快照来查看
一个程序首先要经历一个编译的过程:
main.c sum.c ----> 翻译器 cpp(预处理文件) ccl(c编译器生成汇编) as(汇编器生成一个可重定位二进制文件) 生成main.o ---> 翻译器 cpp,ccl,as生成sum.o ----> main.o + sum.o 通过ld链接器(符号解析和重定位) ---> 可执行文件 proc
这个可执行文件有代码段、数据段、符号表和一些调试信息
这里会用到虚拟内存,比如当我们用gcc编译一个c程序的时候,这时候程序还没有运行,根本没有物理内存的地址?所以,需要一个虚拟内存,内核会为系统中的每一个进程维护一份相互独立的页映射表,页映射表的基本原理就是将程序运行过程中需要访问的一段虚拟内存空间通过页映射表映射到一段物理内存中。
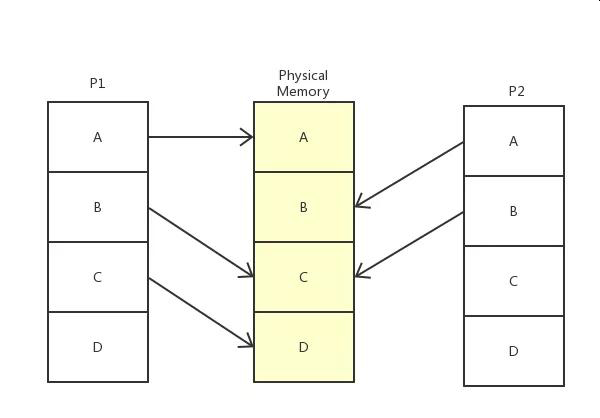
虚拟内存是操作系统里面的概念,对于操作系统来说,虚拟内存就是一张张的对照表,p1获取a内存里的数据时候应该去物理内存的A地址去找,而找B内存里的数据应该去物理内存的C地址
我们知道系统的基本单位字节,如果将每一个虚拟内存的字节都对应到物理内存的地址,那么每个条目至少需要8个字节(32位地址),在4G内存情况下,需要32G的空间来存表,于是操作系统引入了页的概念
在系统启动的时候,操作系统将整个物理内存以4K为单位,划分为各个页。之后进行内存分配都以页为单位。那么虚拟内存页对应物理内存页的映射表就笑的多了,4G内存只需要8M的映射表即可。一些进程没有使用到的虚拟内存页并不保存映射关系。操作系统虚拟内存到物理内存的映射表叫页表
我们知道通过虚拟内存的机制,每个进程都以为自己占用了全局的内存,进程访问内存的时候,操作系统都会把进程提供的虚拟内存转化成物理内存,再去对应的物理内存上获取数据。CPU中有一个硬件叫MMU内存管理单元专门用来翻译虚拟内存地址,CPU还为页表寻址设置了缓存机制
虚拟内存可以实现数据共享:在进程加载系统库(系统头文件stdio.h),总是要分配一块内存,将磁盘中的库文件加载到内存中,在直接使用物理内存时,由于物理内存的地址唯一,即使系统发现同一个库在系统内加载了两次,但每个进程指定的加载内存不一样,系统也无能为力,而在使用虚拟内存时,系统只需要将进程的虚拟内存地址指向库文件所在的物理内存地址即可,如上图所示,进程p1和p2的B地址都指向了物理地址C。
虚拟内存实现SWAP:Liunx提出了SWAP的概念,可以使用SWAP分区,再分配物理内存,但可用内存不足的时候,将暂时不同的内存数据放到磁盘上,让有需要的进程先使用,等进程再需要使用数据的时候,再讲这些数据加载到内存中来,这种交换的技术,可以让进程使用更多的内存
当你输入 ./proc 执行该程序的时候,会产生一个进程,操作系统会给这个进程分配对应的内存空间
一个进程指的是一个正在运行的程序。一个正在运行的程序在内存中的情况(虚拟内存): 内核内存(对用户来说不可见) ----> 用户栈(运行的时候创建) ----> 共享库的内存映射区域(c标准库、数学库等等库文件、头文件) ----> 运行时的堆(程序员自己分配的内存空间) ----> 读/写段(已经初始化未初始化的全局静态变量) ----> 只读代码段(常量、只读数据、程序代码)
以上可以简称:内存四区
让我们加入虚拟内存的技术,再来看看对应的虚拟内存和物理内存的情况:
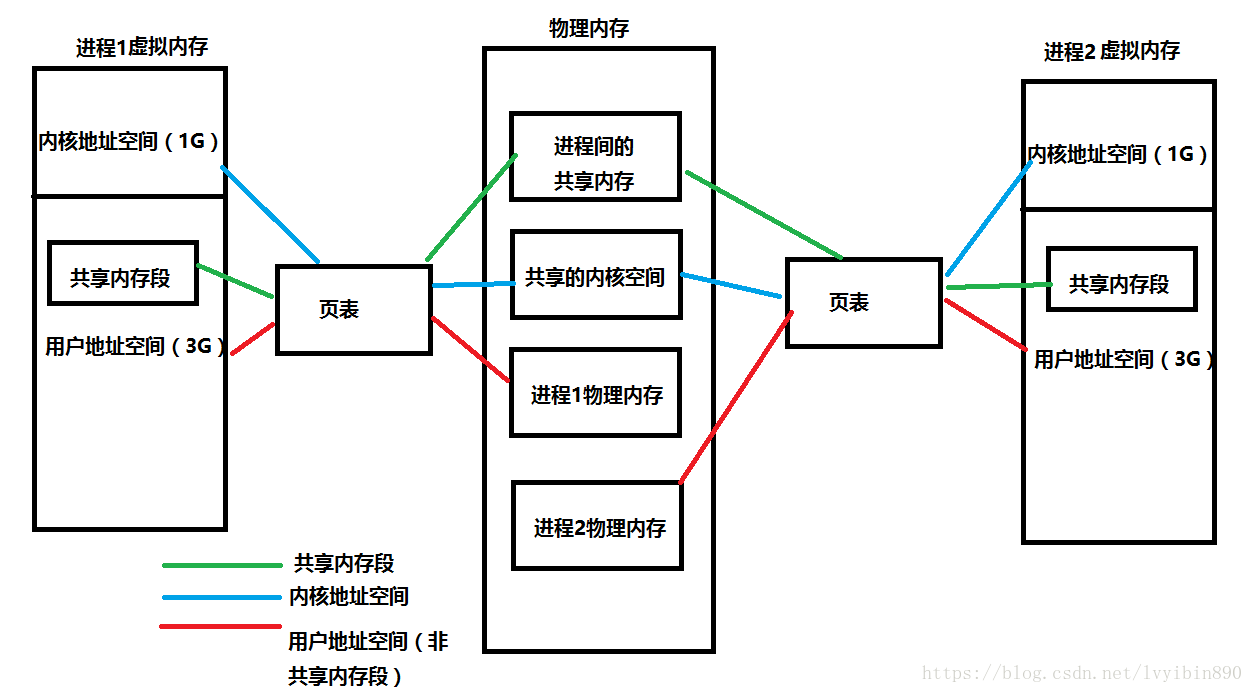
任何一条指令执行的顺序都是按下面的流程(这时候程序已经在内存中了):
- 取指:CPU从内存中读取指令字节,地址为程序计数器的值PC
- 译码:从寄存器文件读入最多两个操作数,ra和rb字段指明的寄存器
- 执行:算数逻辑单元要么执行指令指明的操作,计算内存引用的有效地址,要么增加或者减少栈指针,也可能设置条件码
- 访存:将数据写入内存或从内存读出数据(跟上面的内存四区联系一下)
- 写回:写回阶段最多可以写两个结果到寄存器文件
- 更新PC:将PC设置成吓一跳指令的地址
计算机的核心是cpu,它承担了所有的计算任务,它就像是一个工厂,时刻都在运行
假定工厂的电力有限,一次只能供给一个车间使用,也就是说,一个车间开工的时候,其他的车间都必须停工,背后的含义就是单个cpu一次只能运行一个任务
进程就好比工厂的车间,它代表cpu所能处理的单个任务,任一时刻,cpu总是运行一个进程,其他进程处于非运行状态
这就是并发,就是同一时刻只有一个任务在执行,因为速度太快所以感觉好像在同时发生一样。并行才是真正的同一时刻同时执行两个任务
工厂的车间之间可以独立生产,也可以协作生产,但同一时刻,只能有一个车间在生产,这就涉及到进程之间的通信问题
进程的通信分为以下几个方法:1. 管道 2. 信号 3. 共享内存 4. 消息队列(这些都是通过操作系统内核完成的)
一个车间内,可以有很多工人,他们协同完成一个任务
线程好比车间里面的工人,一个进程可以有多个线程,并且这些线程也并不是同一时刻一起运行,它也是并发的,而不是并行的
车间的空间是工人们共享的,比如很多房间是每个工人都可以进入的。这象征着一个进程的内存空间是共享的。每个线程都可以使用这些共享内存
可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表着一个线程使用某些共享内存的时候,其他的线程只能等待它结束才能使用这一块内存
这就涉及到线程同步的必要性,当多个线程共享相同的内存的时候,需要每一个线程看到相同的视图,当一个线程修改变量的时候,其他的线程也可以读取读取或者修改这个变量。就需要对线程进行同步,确保他们不会访问到无效的变量
一个防止他人进入的简单方法,就是门口加一把锁,先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去,这就是互斥锁,防止多个线程同时读写某一块内存区域
有时候你会好奇线程有堆栈吗?其实是有栈,并且这个栈是放在进程堆空间中分配的

子进程(child process)是进程中一个重要的概念,你可以通过nodejs的child_process模块来执行可执行文件,调用命令行命令,比如其他语言的程序等。也可以通过该模块将.js代码以子进程的方法启动。
Nodejs中的child_process.fork()在unix系统中最终调用的是liunx系统中的fork(),而系统中的fork()需要手动管理子进程的资源释放(waitpid),child_process.fork则不用关心这个问题,Nodejs会自动释放,并且可以在option中选择父进程死后是否允许子进程存活
- spawn()启动一个子进程来执行命令
- options.detached 父进程死后是否允许子进程存活
- options.stdio 指定子进程的三个标准流
- spawnSync() 同步版的spawn
- exec() 启动一个子进程来执行命令,带回调参数获知子进程的情况
- execSync() 同步版的exec()
- execFile() 启动一个子进程来执行一个可执行文件
- execFileSync() 同步版的execFile()
- fork() 加强版的spawn() ,返回值是childProcess对象可以与子进程交互
child.kill与chil.send的区别在于一个是信号、一个是IPC
子进程死亡不会影响父进程,不过子进程死亡的时候,会向他的父进程发送死亡信号,反之父进程死亡,一般情况下子进程也会死亡。但如果此时子进程处于可运行的状态、僵死状态等等的话,子进程将被init进程收养,称为孤儿进程。另外,子进程死亡的时候,父进程没有及时的调用wait()或者waitpid()来返回死亡进程的相关信息,此时子进程还有一个PCB残留在进程表中,被称为僵尸进程
Cluster是常见的nodejs利用多核的办法,它是基于child_process.fork()实现的,所以,cluster产生的进程之间是通过IPC通信的,并且它也没有拷贝父进程的空间,而是通过加入cluster.isMaster来区分父进程和子进程
const cluster = require('cluster'); // | |
const http = require('http'); // | |
const numCPUs = require('os').cpus().length; // | | 都执行了
// | |
if (cluster.isMaster) { // |-|-----------------
// Fork workers. // |
for (var i = 0; i < numCPUs; i++) { // |
cluster.fork(); // |
} // | 仅父进程执行 (a.js)
cluster.on('exit', (worker) => { // |
console.log(`${worker.process.pid} died`); // |
}); // |
} else { // |-------------------
// Workers can share any TCP connection // |
// In this case it is an HTTP server // |
http.createServer((req, res) => { // |
res.writeHead(200); // | 仅子进程执行 (b.js)
res.end('hello world\n'); // |
}).listen(8000); // |
} // |-------------------
// | |
console.log('hello'); // | | 都执行了
在上述代码中 numCPUs 虽然是全局变量但是, 在父进程中修改它, 子进程中并不会改变, 因为父进程与子进程是完全独立的两个空间. 他们所谓的共有仅仅只是都执行了, 并不是同一份.
你可以把父进程执行的部分当做 a.js, 子进程执行的部分当做 b.js, 你可以把他们想象成是先执行了 node a.js 然后 cluster.fork 了几次, 就执行了几次 node b.js. 而 cluster 模块则是二者之间的一个桥梁, 你可以通过 cluster 提供的方法, 让其二者之间进行沟通交流.
cluster的模块提供了两种分发连接的方式:(请求来的时候到底用哪个进程来处理)
第一种方式(默认方式),通过时间片轮转法分发连接,主进程监听端口,接收到新的连接后,通过时间片轮转法来决定将接收到的客户端的socket句柄传递给指定的worker处理,至于每个连接由哪个worker来处理,完全由内置的循环算法决定
第二种方式由主进程创建socket监听端口,将socket句柄直接分发给相应的worker,然后当连接进来的时候,就直接由相应的worker来接收并处理
使用第二种方式理论上性能应该比较高,然后时间上存在负载不均衡的问题,比如通常70%的连接可能被8个进程中的2个处理,其他的比较清闲
NodeJS中的父子进程通信是通过管道实现的libuv
在 IPC 通道建立之前, 父进程与子进程是怎么通信的? 如果没有通信, 那 IPC 是怎么建立的?
这个问题也挺简单, 只是个思路的问题. 在通过 child_process 建立子进程的时候, 是可以指定子进程的 env (环境变量) 的. 所以 Node.js 在启动子进程的时候, 主进程先建立 IPC 频道, 然后将 IPC 频道的 fd (文件描述符) 通过环境变量 (NODE_CHANNEL_FD) 的方式传递给子进程, 然后子进程通过 fd 连上 IPC 与父进程建立连接.
最后于进程间通信 (IPC) 的问题, 一般不会直接问 IPC 的实现, 而是会问什么情况下需要 IPC, 以及使用 IPC 处理过什么业务场景等.
实现一个守护进程,其实就是将普通的进程变成一个拥有以下特点的进程
- 后台运行
- 系统启动就存在
- 不予任何终端相关联,用于处理一些系统级别任务的特殊进程
进程组和会话组:进程组和会话组在进程之间形成了两级的层次:进程组是一组相关进程的集合,会话是一组相关进程组的集合
就像家族企业一样,如果从创建之初,所有家族成员墨守成规,循规蹈矩,默认情况下,就只会有一个公司、一个部门。但是也有些叛逆的子弟,愿意为家族开疆扩土,愿意成立新的部门。这些新的部门就是新创建的进程组。如果有子弟离经叛道,甚至不愿意呆在家族公司里,他别开天地,另创一个公司,那么这个新公司就是新创建的会话组
当有新的用户登录liunx的时候,登录进程会为这个用户创建一个会话。用户登录的shell就是会话的首进程。会话的首进程ID会作为整个会话的ID。会话是一个或多个进程组的集合,囊括了登录用户的所有活动
通常会话开始于用户登录,终止与用户退出,期间所有的进程都属于这个会话。一个会话一般包含一个会话首进程、一个前台进程组和一个后台的进程组
-
会话首进程:其实就是用户登录的shell
-
前台进程组:该进程组中的进程可以向终端设备进行读写操作,该进程组的ID等于控制终端进程组的ID
例如 cmd1 | cmd2 | cmd3 就可以创建一个进程组
- 后台进程组:会话中除了会话首进程和前台进程组以外的所有进程,都属于后台进程组。该进程组的进程只能向终端设备进行写操作
用户在执行命令时,可以在命令的结尾添加“&”符号,表示将命令放入后台执行。这样该命令对应的进程组即为后台进程组。
- fork()创建子进程,父进程exit()退出
这是创建守护进程的第一步。由于守护进程是脱离控制终端的,完成这一步后就会在shell终端里造成程序已经运行完毕的假象。之后的所有工作都在子进程中完成,而用户在shell终端里则可以执行其他的命令,从而形式上做到了与控制终端的脱离,在后台工作
由于父进程先于子进程退出,子进程变成了孤儿进程,并由init进程做为其父进程收养
- 在子进程调用setsid()创建新会话
在调用fork()函数后,子进程全盘拷贝了父进程的会话期、进程组、控制终端等,虽然父进程退出了,但会话期、进程组、控制终端等并没有改变。这还不是真正意义上的独立开来,而setsid()能够让进程完成独立出来
setsid()创建一个新的会话,调用进程担任新回话的首进程
- 再fork()一个子进程,父进程exit退出
现在,进程已经成为了无终端的会话组长了。但它可以重新申请打开一个控制终端,可以通过fork()一个子进程,该子进程不是会话首进程,该进程将不能重新打开控制终端
也就是说,通过再次创建子进程结束当前进程,使进程不再是会话手进程来禁止进程重新打开控制终端
- 在子进程中调用chidir()让根目录'/'称为子进程的工作目录
这一步也是必要的步骤。使用fork()创建的子进程集成了父进程当前的工作目录。由于在进程运行中,当前目录所在的文件系统是不能卸载的,这会对以后的使用造成猪都的麻烦。因此,通常的做法是让/作为守护进程的当前的工作目录,这样可以避免。也可以把/tmp当做是当前的工作目录。避免元原父进程当前目录带来的一些麻烦
- 在子进程中调用umask()重设文件权限掩码为0
文件权限掩码是指屏蔽掉文件权限中的对应位。比如有个文件权限掩码是050,它就屏蔽了文件组拥有者的可读与可执行权限。由于使用fork函数新建立的子进程集成了父进程的文件权限掩码,这就给该子进程使用文件带来了麻烦。因此,把文件权限掩码重设为0即清除掩码(权限为777),通常的做法就是umask(0),相当于将权限放开
- 在子进程中close()不需要的文件描述符
同文件权限码一样,用fork()函数新建的子进程会从父进程那里继承一些已经打开了的 文件。所以,我们关闭失去价值的输入、输出、报错对应的文件描述符
- 守护进程退出处理
当用户需要外部停止守护进程运行时候,往往使用Kill命令停止该守护进程。所以,守护进程中需要编码来实现kill发出的signal信号处理,达到进程的正常退出。
守护进程的代码实现
void init_daemon()
{
pid_t pid;
int i = 0;
if ((pid = fork()) == -1) {
printf("Fork error !\n");
exit(1);
}
if (pid != 0) {
exit(0); // 父进程退出
}
setsid(); // 子进程开启新会话, 并成为会话首进程和组长进程
if ((pid = fork()) == -1) {
printf("Fork error !\n");
exit(-1);
}
if (pid != 0) {
exit(0); // 结束第一子进程, 第二子进程不再是会话首进程
// 避免当前会话组重新与tty连接
}
chdir("/tmp"); // 改变工作目录
umask(0); // 重设文件掩码
for (; i < getdtablesize(); ++i) {
close(i); // 关闭打开的文件描述符
}
return;
}
高并发:在极短的单位时间内,极多个请求同时发起到服务器
服务器的压力会很大,然后,数据库的压力也会很大,所以,解决的思路应该放在服务器上(软件和硬件)和数据库(设计和查询)上面以及代码逻辑上
- 服务器硬件
- RAID
- 服务器软件
- 分布式系统负载均衡nginx
- 多应用拆分、集群
- 数据库
- 表、字段设计阶段考虑更优化的存储和运算
- 使用索引
- Redis缓存
- 主从复制、读写分离
- 分区表
- 垂直拆分、水平拆分
- 代码逻辑上
- 前端
- 使用ajax请求
- 减少合并HTTP请求
- 启动浏览器缓存和文件压缩
- CDN加速
- 防止盗链
- 后端
- 多进程处理请求(APACHE)、多进程多线程(NGINX),异步处理请求(NODEJS)三种不同的策略
- 消息队列中间件:activeMQ等,解决大量消息的异步处理能力。(这里可以参考下我设计的社区系统,用户登录成功后,又要检查用户信息、又要发送邮箱、最后还要检查是否有该用户的消息,这些连续的操作用消息队列再合适不过了)它跟系统编程中的进程间通信IPC方法-消息队列是一样的原理,通常用在多进程的服务器上,采用消息队列来进行通信
- 前端
- 单应用架构

这个阶段是网站的初期,也可以认为是互联网发展的早期,把所有的软件和应用都部署在同一台机器上
- 应用服务器和数据库服务器分离

这个阶段应用服务器和数据库服务器完全隔离开来,相互不影响,大大较少了网站宕机的风险
- 应用服务器集群

这个阶段,随着访问量的继续不断增加,单台应用服务器已经无法满足我们的需求。 假设我的数据库服务器还没有遇到性能问题,那我们可以通过增加应用服务器的方式来将应用服务器集群化,这样就可以将用户请求分流到各个服务器中,从而达到继续提升系统负载能力的目的。此时各个应用服务器之间没有直接的交互,他们都是依赖数据库各自对外提供服务。
系统架构发展到这个阶段,各种问题也会接踵而至:
1)用户请求交由谁来转发到具体的应用服务器上(谁来负责负载均衡)
2)用户如果每次访问到的服务器不一样,那么如何维护session,达到session共享的目的。
这时候加上负载均衡,session共享问题可以用过tomcat的session共享解决

- 数据库读写分离
架构演变到上面的阶段,并不是终点。通过上面的设计,应用层的性能被我们拉上来了, 但数据库的负载也在逐渐增大,那如何去提高数据库层面的性能呢?有了前面的设计思路以后,我们自然也会想到通过增加服务器来提高性能。但假如我们单纯的把数据库一分为二,然后对于数据库的请求,分别负载到两台数据库服务器上,那必定会造成数据库数据不统一的问题。
所以我们一般考虑数据库的主从复制、读写分离

这个架构设计的变化会带来如下几个问题:
1)主从数据库之间的数据需要同步(可以使用 mysql 自带的 master-slave 方式实现主从复制 );
2)应用中需要根据业务进行对应数据源的选择( 采用第三方数据库中间件,例如 mycat )。
- 使用搜索引擎缓解读库的压力
我们都知道数据库常常对模糊查找效率不是很高,像电商类的网站,搜索是非常核心的功能,即使是做了读写分离,这个问题也不能得到有效解决。那么这个时候我们就需要引入搜索引擎了,使用搜索引擎能够大大提升我们系统的查询速度,但同时也会带来一 些附加的问题,比如维护索引的构建、数据同步到搜索引擎等。

- 引入缓存机制缓存数据库的压力
然后,随着访问量的持续不断增加,逐渐会出现许多用户访问同一内容的情况,那么对于这些热点数据,没必要每次都从数据库重读取,这时我们可以使用到缓存技术,比如 redis、memcache 来作为我们应用层的缓存。
另外在某些场景下,如我们对用户的某些 IP 的访问频率做限制, 那这个放内存中就又不合适,放数据库又太麻烦了,那这个时候可以使用 Nosql 的方式比如 mongDB 来代替传统的关系型数据库。

- 数据库的水平/垂直拆分
我们的网站演进的变化过程,交易、商品、用户的数据都还在同一 个数据库中,尽管采取了增加缓存,读写分离的方式,但是随着数 据库的压力持续增加,数据库的瓶颈仍然是个最大的问题。因此我 们可以考虑对数据的垂直拆分和水平拆分。

- 垂直拆分:把数据库中不同业务数据拆分到不同的数据库;
- 水平拆分:把同一个表中的数据拆分到两个甚至更多的数据库中,水平拆分的原因是某些业务数据量已经达到了单个数据库的瓶颈,这时可以采取将表拆分到多个数据库中。

- 应用的拆分
随着业务的发展,业务量越来越大,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑将应用拆分,按照领域模型将我们的用户、商品、交易拆分成多个子系统。

这样拆分以后,可能会有一些相同的代码,比如用户操作,在商品和交易都需要查询,所以会导致每个系统都会有用户查询访问相关操作。这些相同的操作一定是要抽象出来,否则就是一个坑。所以通过走服务化路线的方式来解决。
那么服务拆分以后,各个服务之间如何进行远程通信呢? 通过 RPC 技术,比较典型的有:dubbo、webservice、hessian、http、RMI 等等。前期通过这些技术能够很好的解决各个服务之间通信问题,但是, 互联网的发展是持续的,所以架构的演变和优化也还在持续。
这个是我在写项目的时候最头疼的问题,没有之一。
我目前的主要做法是绕过层层的callback函数,在一个统一的入口处集中处理,错误冒泡到入口处的时候,打印错误信息
uncaughtException 的初衷是可以让你拿到错误之后可以做一些回收处理之后再 process.exit. 官方的同志们还曾经讨论过要移除该事件
所以你需要明白 uncaughtException 其实已经是非常规手段了, 应尽量避免使用它来处理错误. 因为通过该事件捕获到错误后, 并不代表 你可以愉快的继续运行 (On Error Resume Next). 程序内部存在未处理的异常, 这意味着应用程序处于一种未知的状态. 如果不能适当的恢复其状态, 那么很有可能会触发不可预见的问题. (使用 domain 会很夸张的加剧这个现象, 并产生新人不能理解的各类幽灵问题)
所以官方建议的使用 uncaughtException 的正确姿势是在结束进程前使用同步的方式清理已使用的资源 (文件描述符、句柄等) 然后 process.exit.
当 Promise 被 reject 且没有绑定监听处理时, 就会触发该事件unhandledRejection. 该事件对排查和追踪没有处理 reject 行为的 Promise 很有用
process.on('unhandledRejection', (reason, p) => {
console.log('Unhandled Rejection at: Promise', p, 'reason:', reason);
// application specific logging, throwing an error, or other logic here
});
somePromise.then((res) => {
return reportToUser(JSON.pasre(res)); // note the typo (`pasre`)
}); // no `.catch` or `.then`
黑盒测试 (Black-box Testing), 测试应用程序的功能, 而不是其内部结构或运作. 测试者不需了解代码、内部结构等, 只需知道什么是应用应该做的事, 即当键入特定的输入, 可得到一定的输出. 测试者通过选择有效输入和无效输入来验证是否正确的输出. 此测试方法可适合大部分的软件测试, 例如集成测试 (Integration Testing) 以及系统测试 (System Testing).
白盒测试 (White-box Testing) 测试应用程序的内部结构或运作, 而不是测试应用程序的功能 (即黑盒测试). 在白盒测试时, 以编程语言的角度来设计测试案例. 白盒测试可以应用于单元测试 (Unit Testing)、集成测试 (Integration Testing) 和系统的软件测试流程, 可测试在集成过程中每一单元之间的路径, 或者主系统跟子系统中的测试.
单元测试 (Unit Testing) 是白盒测试的一种, 用于针对程序模块进行正确性检验的测试工作. 单元 (Unit) 是指最小可测试的部件. 在过程化编程中, 一个单元就是单个程序、函数、过程等; 对于面向对象编程, 最小单元就是方法, 包括基类、抽象类、或者子类中的方法.
另外, 每次修改代码之后, 通过单元测试来验证比把整个应用启动/重启验证要更快/更简单.
常用的测试工具:
- macha
- ava
- jest
集成测试也称综合测试、组装测试、联合测试, 将程序模块采用适当的集成策略组装起来, 对系统的接口及集成后的功能进行正确性检测的测试工作. 集成测试可以是黑盒的, 也可以是白盒的, 其主要目的是检查软件单位之间的接口是否正确, 而集成测试的对象是已经经过单元测试的模块.
例如你可以在本地将项目中的 web app 启动, 并模拟接口调用:
describe('Path API', () => {
// ...
describe('GET /v2/path/:_id', () => {
it('should return 200 GET /v2/path/:_id', () => {
return request
.get('/v2/path/' + pathId)
.set('Cookie', 'common_user=xxx')
.expect(200);
});
});
describe('POST /v2/path', () => {
it('should return 412 POST /v2/path lost params path', () => {
return request
.post('/v2/path')
.set('Cookie', 'common_user=xxx')
.expect(412);
});
it('should return 409 POST /v2/path when path exist', () => {
return request
.post('/v2/path')
.send({path: '/'})
.set('Cookie', 'common_user=xxx')
.expect(409);
});
it('should return 200 POST /v2/path successfully', () => {
return request
.post('/v2/path')
.send({path: '/comment'})
.set('Cookie', 'common_user=xxx')
.expect(200);
});
});
// ...
});
目前 Node.js 中流行的白盒级基准测试工具是 benchmark.
const Benchmark = require('benchmark');
const suite = new Benchmark.Suite;
suite.add('RegExp#test', function() {
/o/.test('Hello World!');
})
.add('String#indexOf', function() {
'Hello World!'.indexOf('o') > -1;
})
.on('cycle', function(event) {
console.log(String(event.target));
})
.on('complete', function() {
console.log('Fastest is ' + this.filter('fastest').map('name'));
})
// run async
.run({ 'async': true });
压力测试 (Stress testing), 是保证系统稳定性的一种测试方法. 通过预估系统所需要承载的 QPS, TPS 等指标, 然后通过如 Jmeter 等压测工具模拟相应的请求情况, 来验证当前应能能否达到目标.
对于比较重要, 流量较高或者后期业务量会持续增长的系统, 进行压力测试是保证项目品质的重要环节. 常见的如负载是否均衡, 带宽是否合理, 以及磁盘 IO 网络 IO 等问题都可以通过比较极限的压力测试暴露出来.
断言 (Assert) 是快速判断并对不符合预期的情况进行报错的模块. 是将:
if (condition) {
throw new Error('Sth wrong');
}
写成:
assert(!condition, 'Sth wrong');
等等情况的一种简化. 并且提供了丰富了 equal 判断, 对于对象类型也有深度/严格判断等情况支持.
Node.js 中内置的 assert 模块也是属于断言模块的一种, 但是官方在文档中有注明, 该内置模块主要是用于内置代码编写时的基本断言需求, 并不是一个通用的断言库 (not intended to be used as a general purpose assertion library)
常见的断言工具
- chai
- should.js
跨站脚本 (Cross-Site Scripting, XSS) 是一种代码注入方式, 为了与 CSS 区分所以被称作 XSS. 早期常见于网络论坛, 起因是网站没有对用户的输入进行严格的限制, 使得攻击者可以将脚本上传到帖子让其他人浏览到有恶意脚本的页面, 其注入方式很简单包括但不限于 JavaScript / VBScript / CSS / Flash 等.
当其他用户浏览到这些网页时, 就会执行这些恶意脚本, 对用户进行 Cookie 窃取/会话劫持/钓鱼欺骗等各种攻击. 其原理, 如使用 js 脚本收集当前用户环境的信息 (Cookie 等), 然后通过 img.src, Ajax, onclick/onload/onerror 事件等方式将用户数据传递到攻击者的服务器上. 钓鱼欺骗则常见于使用脚本进行视觉欺骗, 构建假的恶意的 Button 覆盖/替换真实的场景等情况 (该情况在用户上传 CSS 的时候也可能出现, 如早期淘宝网店装修, 使用 CSS 拼接假的评分数据等覆盖在真的评分数据上误导用户).
用户除了上传
<script>alert('xss')</script>
还可以使用图片url等方式来上传脚本进行攻击
<table background="javascript:alert(/xss/)"></table>
<img src="javascript:alert('xss')">
还可以使用各种方式来回避检查, 例如空格, 回车, Tab
<img src="javas cript:
alert('xss')">
还可以通过各种编码转换 (URL 编码, Unicode 编码, HTML 编码, ESCAPE 等) 来绕过检查
<img%20src=%22javascript:alert('xss');%22>
<img src="javascript:alert(/xss/)">
在百般无奈, 没有统一解决方案的情况下, 厂商们推出了 CSP 策略.
以 Node.js 为例, 计算脚本的 hashes 值:
const crypto = require('crypto');
function getHashByCode(code, algorithm = 'sha256') {
return algorithm + '-' + crypto.createHash(algorithm).update(code, 'utf8').digest("base64");
}
getHashByCode('console.log("hello world");'); // 'sha256-wxWy1+9LmiuOeDwtQyZNmWpT0jqCUikqaqVlJdtdh/0='
设置 CSP 头:
content-security-policy: script-src 'sha256-wxWy1+9LmiuOeDwtQyZNmWpT0jqCUikqaqVlJdtdh/0='
<script>console.log('hello geemo')</script> <!-- 不执行 -->
<script>console.log('hello world');</script> <!-- 执行 -->
跨站请求伪造 Cross-Site Request Forgery, CSRF 是一种伪造跨站请求的攻击方式. 例如利用你在 A 站 (攻击目标) 的 cookie / 权限等, 在 B 站 (恶意/钓鱼网站) 拼装 A 站的请求.
比如 Q 君是某论坛管理员. 已知这个论坛 A 删除的接口是 post 到某个地址, 并指定一个帖子的 id. 那么我可以在自己的博客 B 上组织一个 CSRF 请求. 然后诱使 Q 君来访问我的博客. 就可以在 Q 君不知情的情况下删除掉我想删的某个帖子.
钓鱼方式包括但不限于公开网站 (xss), 攻击者的恶意网站, email 邮件, 微博, 微信, 短信等及时消息.
同源策略是最早用于防止 CSRF 的一种方式, 即关于跨站请求 (Cross-Site Request) 只有在同源/信任的情况下才可以请求. 但是如果一个网站群, 在互相信任的情况下, 某个网站出现了问题:
a.public.com
b.public.com
c.public.com
...
以上情况下, 如果 c.public.com 上没有预防 xss 等情况, 使得攻击者可以基于此站对其他信任的网站发起 CSRF 攻击.
另外同源策略主要是浏览器来进行验证的, 并且不同浏览器的实现又各自不同, 所以在某些浏览器上可以直接绕过, 而且也可以直接通过短信等方式直接绕过浏览器.
解决方案:
- 同源检查
通过检查来过滤简单的 CSRF 攻击, 主要检查一下两个 header:
Origin Header
Referer Header
- CSRF token
简单来说, 对需要预防的请求, 通过特别的算法生成 token 存在 session 中, 然后将 token 隐藏在正确的界面表单中, 正式请求时带上该 token 在服务端验证, 避免跨站请求.
注入攻击是指当所执行的一些操作中有部分由用户传入时, 用户可以将其恶意逻辑注入到操作中. 当你使用 eval, new Function 等方式执行的字符串中有用户输入的部分时, 就可能被注入攻击. 上文中的 XSS 就属于一种注入攻击. 前面的章节中也提到过 Node.js 的 child_process.exec 由于调用 bash 解析, 如果执行的命令中有部分属于用户输入, 也可能被注入攻击.
Sql 注入是网站常见的一种注入攻击方式. 其原因主要是由于登录时需要验证用户名/密码, 其执行 sql 类似:
SELECT * FROM users WHERE usernae = 'myName' AND password = 'mySecret';
其中的用户名和密码属于用户输入的部分, 那么在未做检查的情况下, 用户可能拼接恶意的字符串来达到其某种目的, 例如上传密码为 '; DROP TABLE users; -- 使得最终执行的内容为:
SELECT * FROM users WHERE usernae = 'myName' AND password = ''; DROP TABLE users; --';
其能实现的功能, 包括但不限于删除数据 (经济损失), 篡改数据 (密码等), 窃取数据 (网站管理权限, 用户数据) 等. 防治手段常见于:
- 给表名/字段名加前缀 (避免被猜到)
- 报错隐藏表信息 (避免被看到, 12306 早期就出现过的问题)
- 过滤可以拼接 SQL 的关键字符
- 对用户输入进行转义
- 验证用户输入的类型 (避免 limit, order by 等注入)