This repository contains code for training and using the SRL model described in: Syntax for Semantic Role Labeling, To Be, Or Not To Be
If you use our code, please cite our paper as follows:
@inproceedings{he2018syntax,
title={Syntax for Semantic Role Labeling, To Be, Or Not To Be},
author={He, Shexia and Li, Zuchao and Zhao, Hai and Bai Hongxiao},
booktitle={Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018)},
year={2018}
}
Semantic role labeling (SRL) is dedicated to recognizing the predicate-argument structure of a sentence. Previous studies have shown syntactic information has a remarkable contribution to SRL performance. However, such perception was challenged by a few recent neural SRL models which give impressive performance without a syntactic backbone. This paper intends to quantify the importance of syntactic information to dependency SRL in deep learning framework. We propose an enhanced argument labeling model companying with an extended korder argument pruning algorithm for effectively exploiting syntactic information. Our model achieves state-of-the-art results on the CoNLL-2008, 2009 benchmarks for both English and Chinese, showing the quantitative significance of syntax to neural SRL together with a thorough empirical survey over existing models.
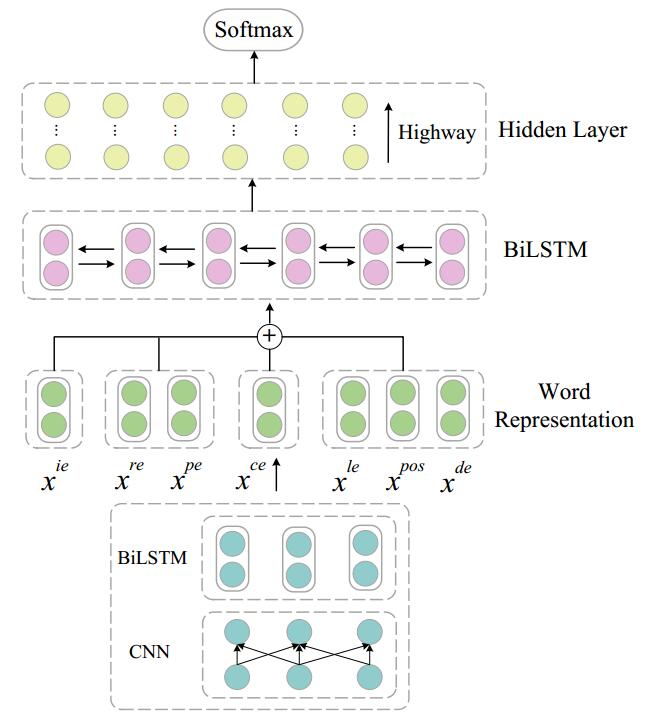
The framework of the proposed model:
this project is implemented on pytorch 0.3.1, the other version may need some modification.
python main.py --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --K 10 --seed 100 --tmp_path temp --model_path model --result_path result \
--pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 \
--bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5
--clip 5python main.py --eval --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --K 10 --seed 100 --tmp_path temp --model_path model --result_path result \
--pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 \
--bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5
--clip 5 --model model/xxx.pklYou can refer to our paper for more details. Thank you!