This repository contains code for replicating results from the following publication:
- A Unified Syntax-aware Framework for Semantic Role Labeling
- Zuchao Li, Shexia He, Jiaxun Cai, Zhuosheng Zhang, Hai Zhao, Gongshen Liu, Linlin Li, Luo Si
- In EMNLP 2018
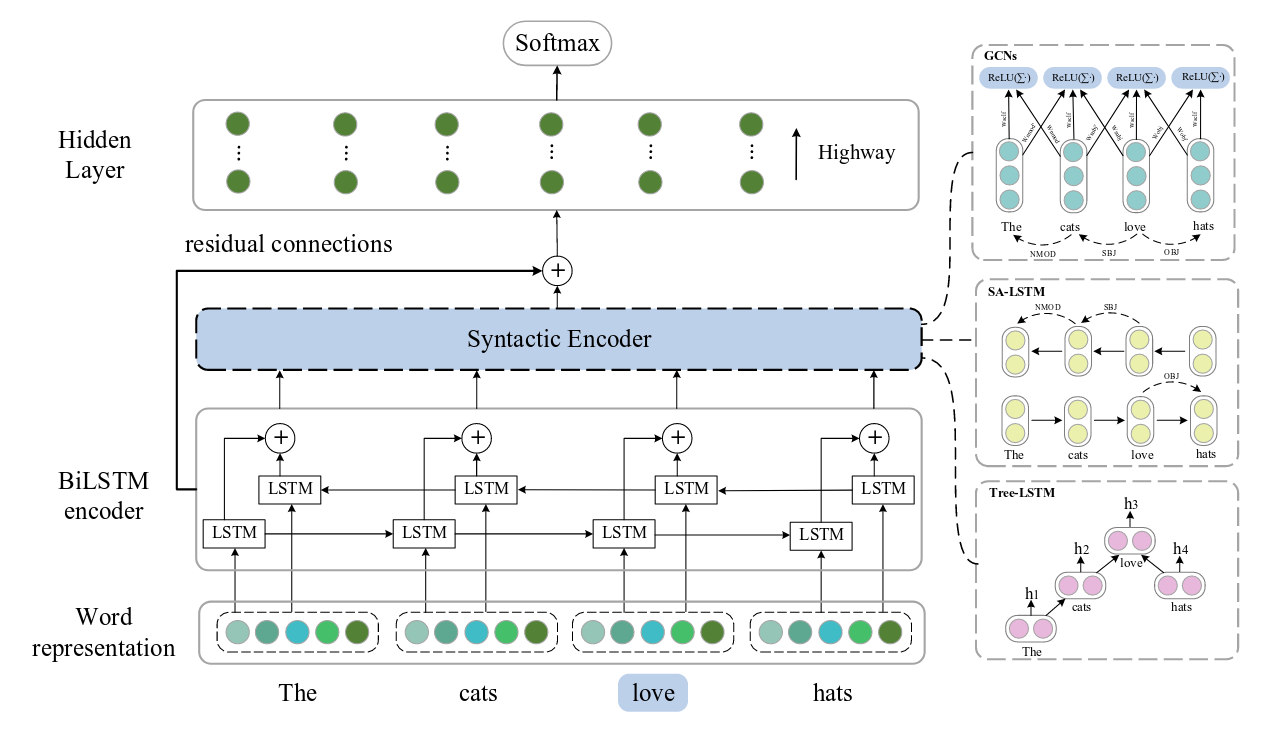
Semantic role labeling (SRL) aims to recognize the predicate-argument structure of a sentence. Syntactic information has been paid a great attention over the role of enhancing SRL. However, the latest advance shows that syntax would not be so important for SRL with the emerging much smaller gap between syntax-aware and syntax-agnostic SRL. To comprehensively explore the role of syntax for SRL task, we extend existing models and propose a unified framework to investigate more effective and more diverse ways of incorporating syntax into sequential neural networks. Exploring the effect of syntactic input quality on SRL performance, we confirm that high-quality syntactic parse could still effectively enhance syntactically-driven SRL. Using empirically optimized integration strategy, we even enlarge the gap between syntax-aware and syntax-agnostic SRL. Our framework achieves state-of-the-art results on CoNLL-2009 benchmarks both for English and Chinese, substantially outperforming all previous models.
If you use our code, please cite our paper as follows:
@inproceedings{li2018unified,
title={A Unified Syntax-aware Framework for Semantic Role Labeling},
author={Li, Zuchao and He, Shexia and Cai, Jiaxun and Zhang, Zhuosheng and Zhao, Hai and Liu, Gongshen and Li, Linlin and Si, Luo},
booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
year={2018}
}
Part of the codebase is extended from srl_syn_pruning.
- Python 3.6
- Pytorch 0.4.1
- allennlp (for ELMo intergration)
We perform experiments on CoNLL-2009 datasets both for English and Chinese.
python run.py --preprocess --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 python run.py --preprocess --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 --use_gcnpython run.py --preprocess --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 --use_sa_lstmpython run.py --preprocess --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 --use_tree_lstmpython run.py --preprocess --train --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 --use_rcnnpython run.py --eval --train_data data/conll09-english/conll09_train.dataset --valid_data data/conll09-english/conll09_dev.dataset --test_data data/conll09-english/conll09_test.dataset --ood_data data/conll09-english/conll09_test_ood.dataset --seed 100 --tmp_path temp --model_path model --result_path result --pretrain_embedding pretrain/glove.6B.100d.txt --pretrain_emb_size 100 --epochs 20 --dropout 0.1 --lr 0.001 --batch_size 64 --word_emb_size 100 --pos_emb_size 32 --lemma_emb_size 100 --use_deprel --deprel_emb_size 64 --bilstm_hidden_size 512 --bilstm_num_layers 4 --valid_step 1000 --use_highway --highway_num_layers 10 --use_flag_emb --flag_emb_size 16 --use_elmo --elmo_emb_size 300 --elmo_options pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json --elmo_weight pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 --clip 5 --model model/best_xx.xx.pklYou can refer to our paper for more details. Thank you!
Four types of syntactic inputs are used to explore the role of syntax in our unified framework, (1) the automatically predicted parse provided by CoNLL-2009 shared task, (2) the parsing results of the CoNLL-2009 data by state-of-the-art syntactic parser, the Biaffine Parser (Dozat and Manning, 2017), (3) corresponding results from another parser, the BIST Parser (Kiperwasser and Goldberg, 2016), which is also adopted by Marcheggiani and Titov (2017), (4) the gold syntax available from the official data set.