Celery[redis] bunch of TID.reply.celery.pidbox objects taking a lot of memory #6089
Comments
|
are you profiling your code? if so then you should also be able to find out the root cause of memory leak and a possible solution |
|
Erm... my code does not make those keys - it is Celery that does that. I am guessing they are related to some of the Chords that we run every day. Why do they have TTL = -1? Our code does not touch the Celery broker (ElastiCache instance). |
|
I was trying to suggest that as it's being used in the production of your system, it would be wise to profile the Leakey source of celery :) |
|
Well, this is not a regular "memory leak" - Celery creates enormous objects in Redis with TTL=-1 and if it fails to delete them for whatever reason, we have trouble... |
|
Did you read what I wrote above? :) - It is not a regular memory leak! I humbly believe setting TTL=-1 for those keys is a bug. |
|
Anything related to the result expires setting? Perhaps you made the setting None so all the tasks for that worker keep their results in the backend (until TTL or eviction). Can you provide more info? |
|
No, we do not use the |
|
This seems to be same as celery/kombu#294 |
sorry for not being meaningfully helpful! do you have the bandwidth to come up with a workable solution to the problem? after you come with a PR we could share our effort with you. |
|
Our solution to this issue is to periodically remove keys that have been idle for more than X days red = app.backend.client
for key in red.scan_iter("*", 100000):
if key.decode().startswith('_kombu'):
continue
if red.object('idletime', key) >= (24 * 7 * 3600):
red.delete(key) |
|
We are hitting this issue as well. I've been trying to debug it but I wasn't able to understand the root cause yet. I'm trying to plot some of the data I have access to. This keys are never cleanup and we are manually deleting them once in a while --each week more frequently, tho. Not sure if related or not, but it seems our Redis gets OOM when we receive a bunch of tasks at the same time:
We are using: Is there any other important info I should be provide to help. I'm happy to keep debugging this, but I'd probably need more directions here. Note that we are only noticing this in production. Edit: after 1h it went from 283Mb to 726Mb of |
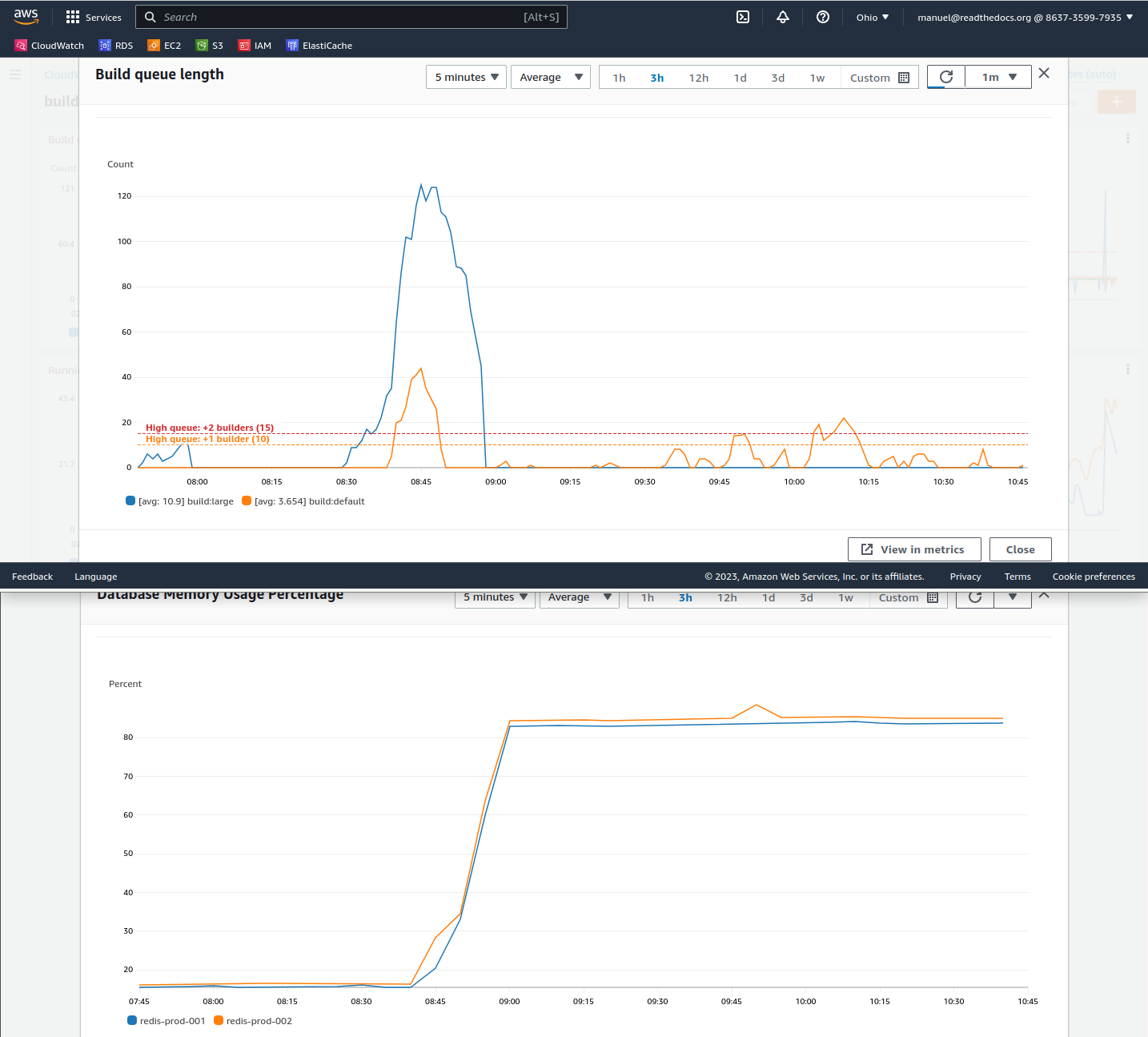
|
If I understand correctly, this is the Celery/Kombu code involved into this:
I suppose that's why (not supported on Redis) we have all the messages with |
Simple task to remove `pidbox` keys older than 15 minutes. This is a workaround to avoid Redis OOM for now. We will need to find out a better solution here. There is an upstream issue opened that we should check in the near future and probably remove this workaround: celery/celery#6089
Simple task to remove `pidbox` keys older than 15 minutes. This is a workaround to avoid Redis OOM for now. We will need to find out a better solution here. There is an upstream issue opened that we should check in the near future and probably remove this workaround: celery/celery#6089
|
Redis supports expiration of keys since the beginning. |
|
Yeah, but reading the docstring of the method, it seems the Celery integration with Redis does not support it: https://github.com/celery/kombu/blob/main/kombu/entity.py#L464-L473 |
* Celery: cleanup `pidbox` keys Simple task to remove `pidbox` keys older than 15 minutes. This is a workaround to avoid Redis OOM for now. We will need to find out a better solution here. There is an upstream issue opened that we should check in the near future and probably remove this workaround: celery/celery#6089 * Celery: use `redis` to get the client `app.backend.client` is not working anymore since we are not using a backend result anymore.
|
We are facing similar issue, Can some help with the final workable solution ? |
There was a strange bug where over a few months, celery's idle CPU usage kept increasing. It seems this may have been related to the healthcheck being killed by docker, without cleaning up after itself. This lead to hundreds of thousands of 'celery.pidbox' keys being left behind on redis, which slowed down redis. See celery/celery#6089
There was a strange bug where over a few months, celery's idle CPU usage kept increasing. It seems this may have been related to the healthcheck being killed by docker, without cleaning up after itself. This lead to hundreds of thousands of 'celery.pidbox' keys being left behind on redis, which slowed down redis. See celery/celery#6089
Since there is no guidance/advise request I had to file a bug report, and I apologise for that in advance. Recently we have started having memory issues with our Redis (ElastiCache) server. Using RedisInsight i found that we have hundreds of list objects that look like
70e68057-de21-3ed6-9798-26cd42ad8456.reply.celery.pidboxthat take between 50M and 150M of RAM and have TTL = -1 (in other words they do not expire!).Question is how to prevent this from happening? Is it a bug? Is there a way to maintain these keys (periodically cleanup somehow)? Any constructive advise is welcome!
The text was updated successfully, but these errors were encountered: