Add AdamW optimizer #4050
Add AdamW optimizer #4050
Conversation
|
Thank you for this PR! It looks very interesting. I have only skimmed through the paper but do you think it would be possible to reproduce (i.e. make plots) the experiments in the paper for CIFAR-10? |
|
Sure, I will try and post the results here! |
|
I modified the Chainer CIFAR10 example to compare SGDM, Adam and AdamW with VGG16 (so the experiment is different from the paper). Loss Accuracy Like they say in the paper, AdamW seems to beat Adam in the latter half of the training in terms of accuracy (although the validation loss is higher, strange?) and becomes competitive with SGDM. |


|
Thank you for PR! |
|
Sure, that is a good idea, and much more maintainable! I will change the implementation in that manner. |
|
I merged AdamW into Adam. I set |
|
Thank you for the fix! As for the documentation, users without knowledge of AdamW would think Chainer's implementation of Also we should mention the name |
|
I updated the documentation. Did you have something like this in mind? |
|
@tkerola can you kindly also test my branch to make the nice graphs? I am not on my linux box for a while and I cannot get it running on my mac's gpu for some reason... |
|
Sure, I will test it with the same training script. |
|
As requested by @kashif, I redid the experiment above with AMSGrad added, so all 4 methods are compared. Loss: Accuracy: |
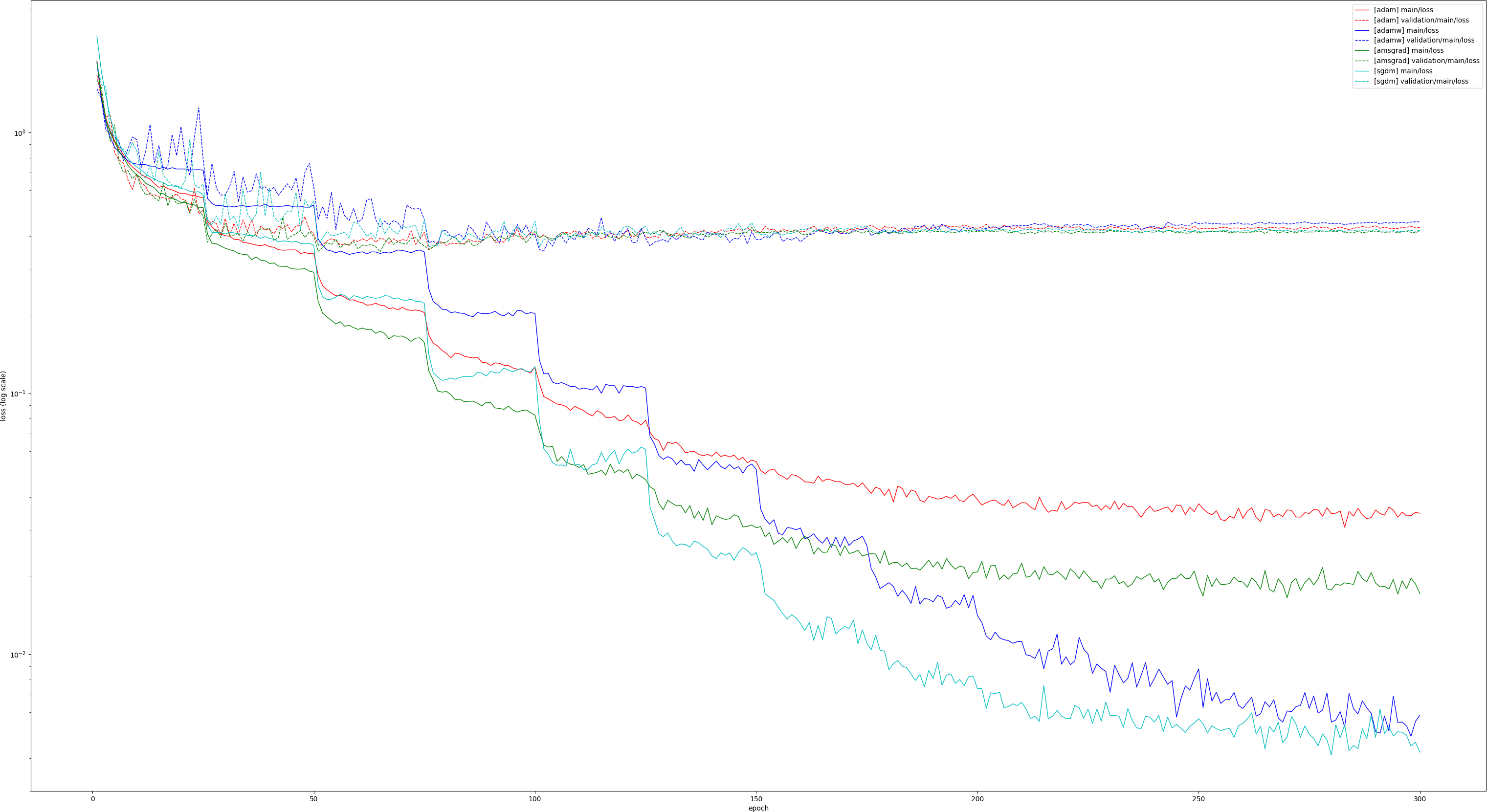
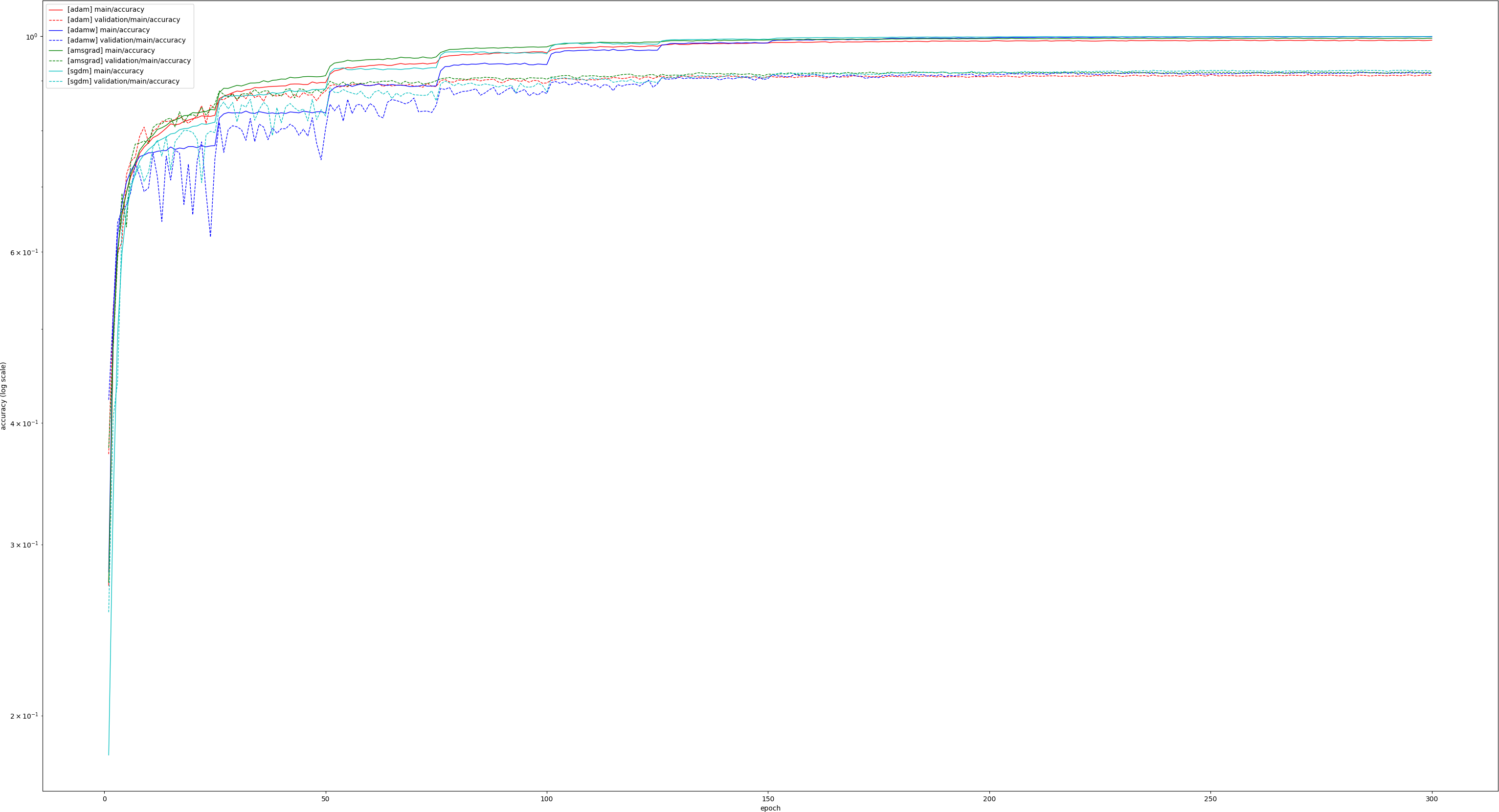
|
@tkerola also I wanted to ask, would it make sense to fix the weight decay in chainer using this method, rather than implementing new optimizers? I am also thinking along similar lines for the AMSGrad PR... what do you think? |
|
Hmm, do you have any idea of how to implement that efficiently? |
|
jenkins, test this please |
1 similar comment
|
jenkins, test this please |
|
LGTM! |
This PR implements AdamW, which was proposed in the following paper: https://openreview.net/forum?id=rk6qdGgCZ
As shown in the paper, the current way that weight decay is implemented in Chainer does not work properly with Adam. AdamW is a modified version of Adam that properly handles weight decay,
and was shown to improve results.
While the original paper calls the algorithm AdamW, I call it
AdamWeightDecayin this implementation, since I thought that it better spells out the purpose of the algorithm. Please let me know if you think the name should be changed toAdamW.Note that this modification of Adam is theoretically applicable to AMSGrad as well (#4032).