Adds N-step learning for DQN-based agents. #317
Conversation
…asses that into replaybuffer
|
Results: N-step performs equal or slightly better than DQN in two domains: Qbert and Pong. Otherwise, N-step DQN performs worse. Unfortunately, we don't have a baseline to compare against. Space Invaders Breakout Seaquest Qbert Asterix Pong BeamRider |

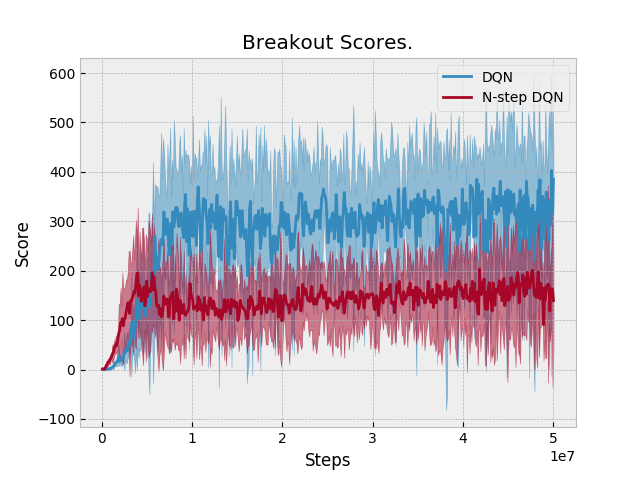
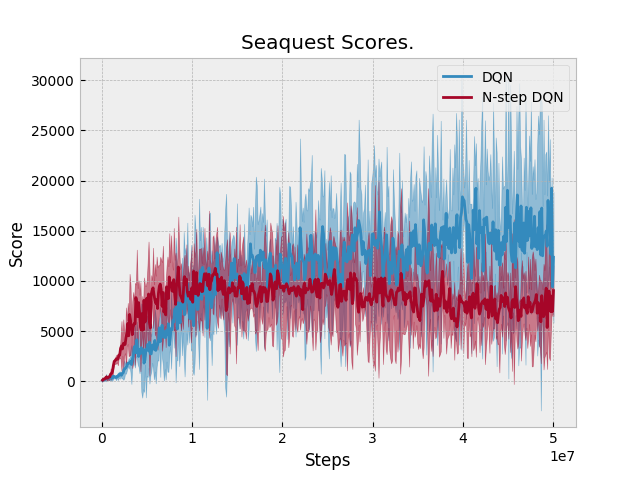
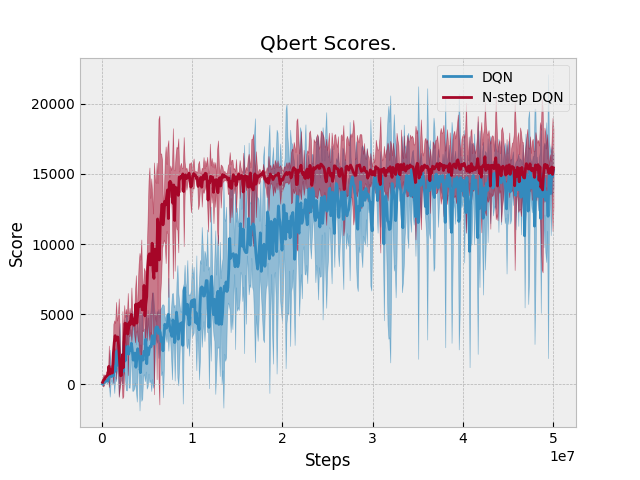


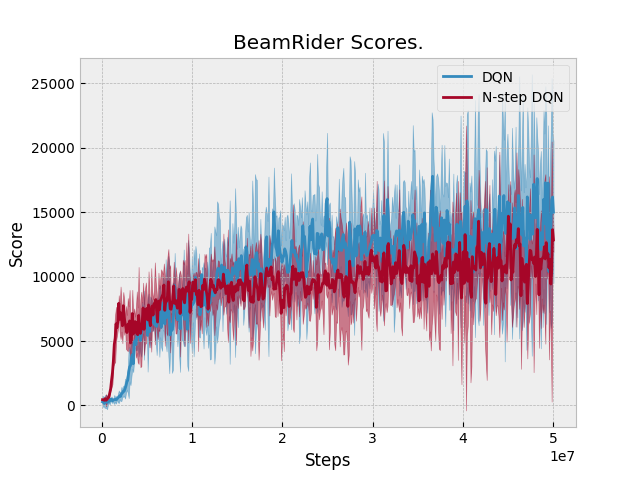
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
7 similar comments
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Just eyeballed this PR's DQN (which is actually double DQN) results and compared them to the Tuned DQN results from: The results look similar, so it suggests that the n-step DQN implementation of 1-step DQN does not adversely affect performance. |
|
Can you resolve the conflicts? |
|
The previous version of N-step DQN did not add an additional N-1 transitions when an episode finishes. These are the updated results after adding this feature to N-step learning. |
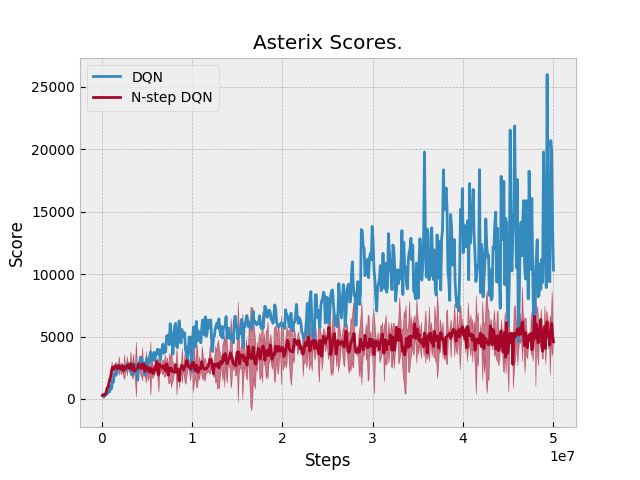

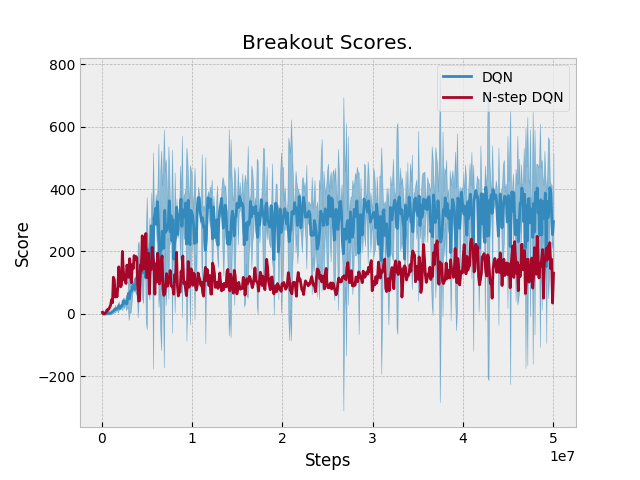
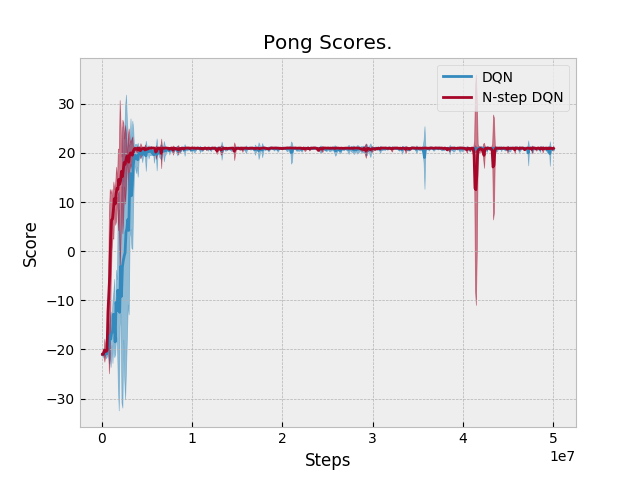


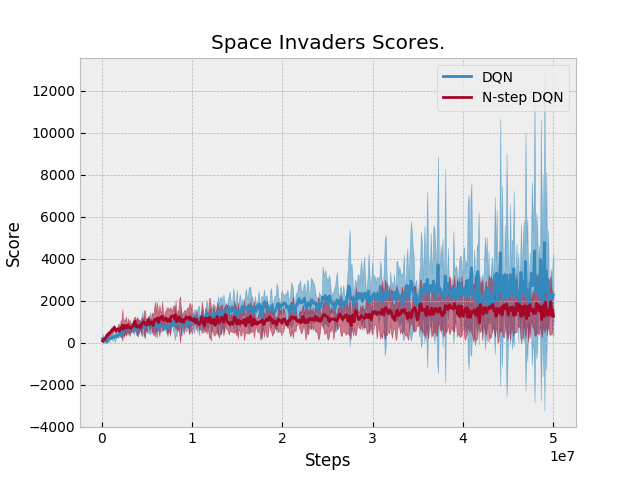
|
Looks good! |
Known affected agents:
-DQN