{kind=link}
pip install pdf2tablescamelot是一个很棒的pdf表格数据抽取库,但遗憾的是它不能处理基于图片的pdf表格。pdf2tables是对camelot的一个补充,pdf中能够使用camelot抽取的表格,用camelot抽取,而camelot处理不了的图片,则使用ocr的方式识别处理。
pdf2talbes使用了部分 @lxj0276 处理图片表格的代码 github tableDetect。以及SongpingWang发表的文章OpenCV—Python 表格提取 中的代码(版权声明:此文为博主SongpingWang原创文章,遵循CC BY-SA 4.0版权协议,转载请附上原文出处链接和本声明),向两位表示感谢。
opencv2读取或写入图像文件时不支持中文,因此有关文件路径的参数请全部使用英文。
pdf2tables需要安装以下软件才能正常运行
- python3.7
- tesseract tesseract下载,安装完毕后进需要将安装目录放入环境变量中,并保证命令行中tesseract -v可以打印出版本信息
- 阿里云表格识别接口 点击此处了解阿里云ocr 表格识别详情
ocr识别时,tesseract与aliyun可以任选其一,tesseract免费但速度较慢,aliyun速度快但需要付费(前500条免费)。
# 示例:
from pdf2tables import pdf_tables
imgOcrSettings = {
'pytesseract_kernel': np.ones((4, 4), np.uint8),
'pytesseract_bin_threshold': 127,
'pytesseract_iterations': 1,
# 单元格面积范围,决定哪些单元格会被选中
'pytesseract_areaRange': [10000, 100000],
'pytesseract_isDebug': False,
# 单元格边框,用来更精确地获取文本
'pytesseract_border': 10,
'img_ocr_type': ImgOcrType.Pytesseract,
'aliyun_appcode': 'b8f41a5f9b664a45af2bc9f58666a17e'
}
tables = extract(
'C:/pdf2tables/test_data/Jan-2010.pdf', lang='eng+tha', **imgOcrSettings)示例imgOcrSettings配置中:
- pytesseract前缀的为使用tesseract的配置,在
img_ocr_type等于ImgOcrType.Pytesseract时生效。 - aliyun前缀的为aliyun配置
pdf2tables会将ocr配置传递到image_tables模块中,配置使用前缀进行区分,如果使用aliyun,则可以忽略所有pytesseract配置,反过来也一样。
表格抽取完毕后,返回PageTable列表, PageTable定义如下
@dataclass
class PageTable:
'''
表格抽取结果类
'''
# 页数
page: int
# 数据列表
datas: []
# 本页文本
text: str示例imgOcrSettings配置中,如果isDebug设置为True,那么image_tables模块将会显示待分割抓取的图片,并将其保存在硬盘上。
例如:
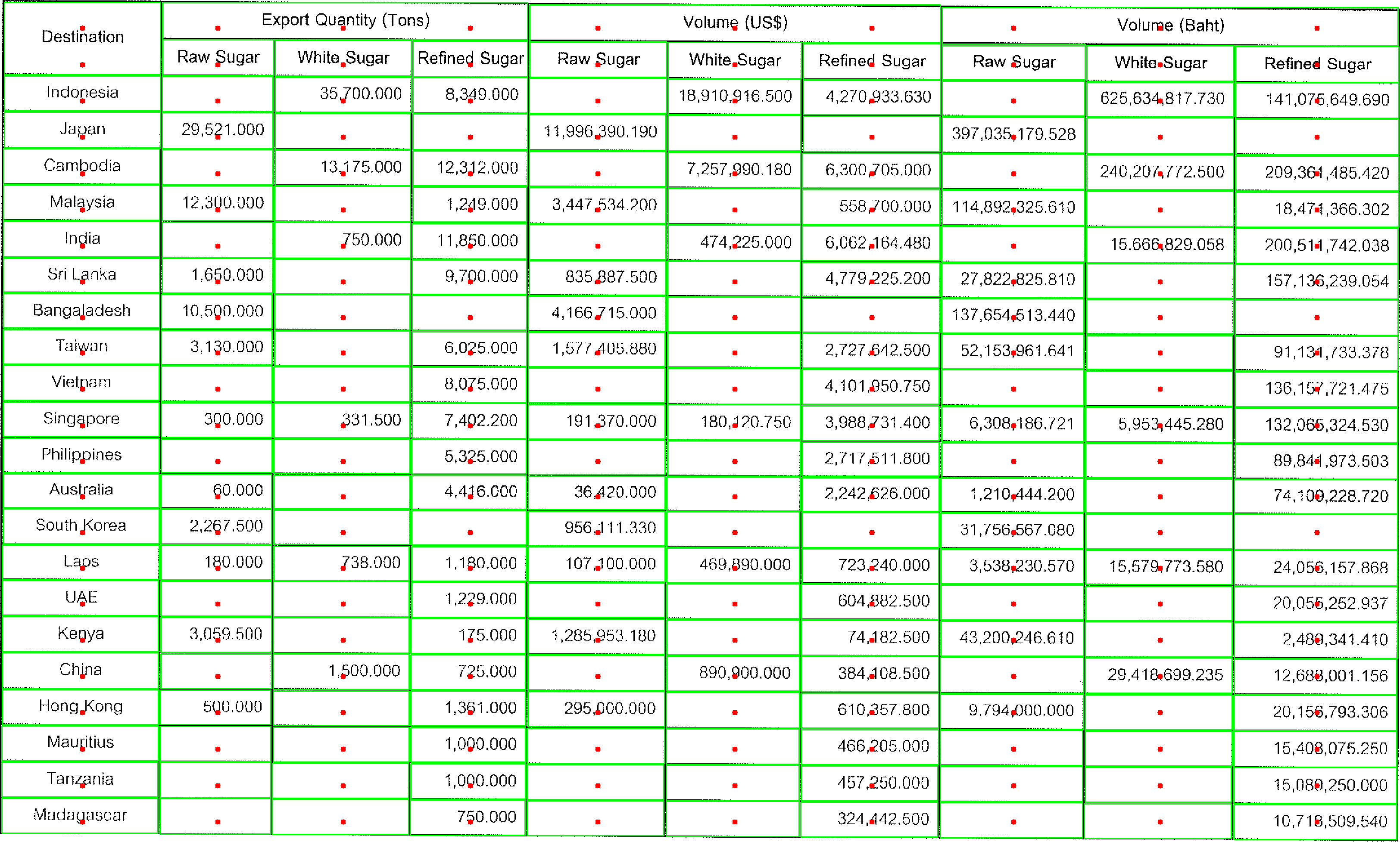
图片中绿色的边框为单元格,红色圆点为数据数组的标识,如果单元格有未被识别的情况,表现为某些单元格没有绿色边框包围,那么需要调整pytesseract_areaRange参数,让所有的表格都能够被绿色边框包围。
image_tables模块是使用tesseract抽取图片表格数据的模块,它会查找图片中的表格范围,截取表格为新图片,然后按单元格切分表格,最后将单元格图片中的文字识别出来。识别后的文字会按单元格的顺序存放。
主要方法:
- def detect_table(img): 检查表格,返回网格图和网格坐标图
- find_table(img, mask_img, save=False, save_dir=None): 查找表格,根据网格图找到表格轮廓,如果save=True,那么会将找到的表格保存为图片
- find_joint_points(joint): 查找网格坐标点,根据返回的结果可以产生数据数组
- class cutImage(object): 截取单元格的类
- get_text(self): 截取单元格为小图片并将其中的文本
使用阿里云接口抽取表格数据