Proposal for loops #495
Comments
|
Gathering some real world workflows that use looping, for inspiration: |
|
our REANA example has this requirement https://awesome-workshop.github.io/reproducible-analyses/07-higgstotautau-parallel/index.html |
|
Thanks @lukasheinrich , which bit is the loop? Is it "do the same thing to each of these inputs" or is it "run this part until a condition is met"? |
|
We are looking at workflow engines for a possible project. This would be a prerequisite for our usecase (e.g. time-loops, optimization, etc.). |
|
Hello @Karel-van-de-Plassche ! Do you need loops within the workflow (repeat these steps, folding their outputs into their inputs) or loops over entire workflow (run this simulation workflow until the critical threshold is met)? |
|
To @lukasheinrich @tiborsimko @clelange @Karel-van-de-Plassche @DaanVanVugt @nielsdrost : the point of my questions is to better understand both where loops are desired and what types of operations between iterations are needed. I can imagine many different types of scenarios, but we should design for specific and not theoretical needs. If incrementing a counter is sufficient, then @tetron design is good enough. If the outputs of one round of the loop need to become inputs, perhaps with a complicated transformation, then I'm not sure the current design is sufficient. There could be other considerations based on real, specific use cases. But we don't have those use cases to study, which makes it difficult to sketch how these loops would work. However, do not despair! The loop construct would be a small percentage of a typical scientific/research workflow. The easiest way to advance this proposal would be to implement @tetron 's design as an extension to CWL v1.2 in a fork of the CWL reference runner. This would give us a lot of experience in what works and what does not. That extension could look like: step3:
in:
a: a
out: [out]
run: blah.cwl
requirements:
cwltool:Loop:
while: $(self.a < 5)
loop:
a: $(self.a + 1)I (@mr-c) and others would help you implement and test such an extension, but I can't do it alone :-) |
|
This issue has been mentioned on Common Workflow Language Discourse. There might be relevant details there: https://cwl.discourse.group/t/while-style-reccurent-step-feature-request/349/2 |
|
An open question is how to incorporate the results of the previous iteration in the next round. One approach using the current proposal: the references to the previous iteration's results could occur in the |
|
This issue has been mentioned on Common Workflow Language Discourse. There might be relevant details there: https://cwl.discourse.group/t/access-envdef-of-workflow-in-cwltool/572/10 |
|
That's what the I realize that's not totally clear in the original proposal, here's a revised one, this feeds the value of "out" back into "b": |
|
I have a slight more complete proposal that I want to share with you. It comes from both language considerations and real scientific applications requirements. First of all, it is necessary to state that here I am only considering iterations with loop-carried dependencies, as loop-independent iterations can be more efficiently expressed with the Loops as extensions of conditionsThe basic propositions that guide this proposal are the following:
I think that the loop construct in CWL should preserve this properties, so I propose to use the already existing
Let's examine the first two cases with the previous example (with the Assume that Extended
|
| field | required | type | description |
|---|---|---|---|
when |
optional | Expression | If defined, only run the step while the expression evaluates to true. If false and no iteration has been performed, the step is skipped. A skipped step produces a null on each output. |
loop field syntax
Since the while clause has been removed, we only need to define the syntax of the loop clause. Here I propose something like this:
| field | required | type | description |
|---|---|---|---|
loop |
optional | array<LoopInput> | map<id, source | LoopInput> |
Defines the input parameters of the loop iterations after the first one (inputs of the first iteration are the step input parameters). If no loop rule is specified for a given step in field, the initial value is kept constant among all iterations. |
The LoopInput will be shaped as follows. It is basically a reduced version of the WorkflowStepInput structure with the possibility to include outputs of the previous step execution in the valueFrom Expression.
| field | required | type | description |
|---|---|---|---|
id |
optional | string | It must reference the id of one of the elements in the in field of the step. |
source |
optional | string | Specifies one or more of the step output parameters that will provide input to the loop iterations after the first one (inputs of the first iteration are the step input parameters). |
linkMerge |
optional | LinkMergeMethod | The method to use to merge multiple inbound links into a single array. If not specified, the default method is "merge_nested". |
pickValue |
optional | PickValueMethod | The method to use to choose non-null elements among multiple sources. |
valueFrom |
optional | string | Expression | To use valueFrom, StepInputExpressionRequirement must be specified in the workflow or workflow step requirements. If valueFrom is a constant string value, use this as the value for this input parameter. If valueFrom is a constant string value, use this as the value for this input parameter. If valueFrom is a parameter reference or expression, it must be evaluated to yield the actual value to be assiged to the loop input field. The self value in the parameter reference or expression must be null if there is no source field, or the value of the parameter(s) specified in the source field. The value of inputs in the parameter reference or expression must be the input object to the last iteration of the workflow step after assigning the source values. The value of outputs in the parameter reference or expression must be the outputs of the last step execution. |
Loop output modes
A single way to deal with loop outputs is not enough in my opinion. Therefore, I propose to add a field called outputMethod which behaves similarly to the scatterMethod input. Until now, I have identified three possible values for this field:
| symbol | description |
|---|---|
last |
Default. Propagates only the last computed element to the subsequent steps when the loop terminates. |
all_propagate |
Propagates each output value to the subsequent steps after every loop iteration. |
all_concat |
Propagates a single array with all output values to the subsequent steps when the loop terminates. |
To simplify things, I suggest to have a single outputMethod field for a step instead of specifying a different behaviour for each output element. Note that both last and all_propagate behaviours are transparent when a single iteration is performed (and also when the step is skipped). Conversely, the all_concat option will return arrays with a single value.
Here I present a concrete example for each output behaviour:
last output mode
This is the most recurrent behaviour and it is typical of the optimization processes, when I want to iterate until I reach a given precision of my estimate. For example:
optimization:
in:
a: a
threshold: threshold
when: $(outputs.error > inputs.threshold)
run: optimize.cwl
out: [value, error]
loop:
a: value
outputMethod: last
This loop keeps optimizing the initial a value until the error value falls below a given (constant) threshold. Then, the last values of value and error will be propagated.
all_propagate output mode
This behaviour is needed for example when a recurrent simulation produces loop-carried results, but each result can be processed independently by the rest of the workflow. For example:
simulation:
in:
a: a
day:
valueFrom: 0
max_day: max_day
when: $(outputs.day < inputs.max_day)
run: optimize.cwl
out: [value]
loop:
a: value
day:
valueFrom: $(inputs.day + 1)
outputMethod: all_propagate
In this case, subsequent steps can start processing outputs even before the simulation step terminates. Note that the implementation of this second case is a bit more complicated, as the subsequent steps must be notified (under the hood) that the loop has terminated, i.e. that no more input values will arrive.
The all_concat mode
This behaviour is needed when a recurrent simulation produces loop-carried results, but the subsequent steps need to know the total amount of computed values to proceed. The example is very similar to the previous one, so it is not reported.
The Arbitrary Cycles pattern
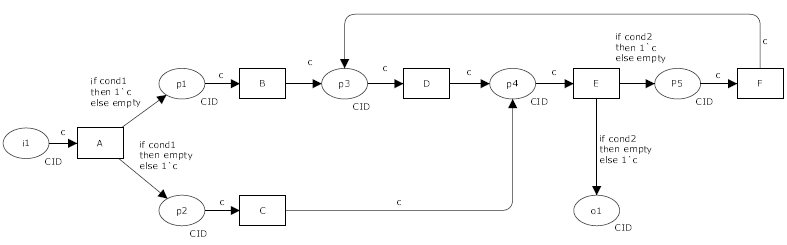
This proposal is general enough to implement the Arbitrary Cycles pattern in CWL. Here is an example of a full Workflow implementing the reference example.
cwlVersion: v1.3
class: Workflow
inputs:
i1: Any
outputs:
o1:
type: Any
outputSource: subworkflow/o1
steps:
A:
run: A.cwl
in:
in1: in1
out: [p1, p2]
B:
run: B.cwl
in:
p1: A/p1
out: [p3]
C:
run: C.cwl
in:
p2: A/p2
out: [p4]
subworkflow:
when: $(outputs.o1 !== null)
run:
class: Workflow
inputs:
p3: Any
p4: Any
outputs:
o1:
type: Any
outputSource: E/o1
p3:
type: Any
outputSource: F/p3
steps:
D:
run: D.cwl
in:
p3: p3
out: [p4]
E:
run: E.cwl
in:
p4:
source:
- p4
- D/p4
pickValue: the_only_non_null
out: [o1, p5]
F:
run: F.cwl
in:
p5: E/p5
out: [p3]
in:
p3: B/p3
p4: C/p4
out: [o1, p3]
loop:
p3: p3
outputMethod: last
|
Thank you for this very thoughtful proposal!
I agree with this
The version I proposed was basically only
These both makes sense.
This I have concerns about. It has significant implications for the current CWL model of computation. There's certainly value in being able to being able to start computation of downstream steps before all iterations/instances of a loop or scatter step has completed, but I think we should try to address that as a separate proposal. |
|
Few comments here:
This is not a big problem, as the
I am a bit scared about that, as the next syntactical step here would be to specify outputs from other steps as Allowing cross-step loops would be obviously more intuitive for users, but from an implementation point of view it would require huge changes in the way CWL processes dependencies, much more than the |
|
Plus, I would like to start a discussion about two remaining open points in the The
|
|
With regards to With regards to If an In other words: For a step with both
Of course, an implementation is welcome to optimize execution by making elements available to down-stream steps (especially steps that themselves are Your query about |
To achieve the concept of more than one entry point, shouldn't there be additional conditionals? Step B should be skipped if For another illustration, download http://www.workflowpatterns.com/patterns/control/images/cp10_flash.swf and play it using https://ruffle.rs/demo/ |
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Default behaviorMy vote is for the 2nd case. This follows naturally from having Combining scatter and loopI would strongly prefer to not allow these in the same step. It seems like an unusual case, and if someone does need to do it, they can use a subworkflow to achieve the correct nesting. We can enforce this in schema by having disjoint ScatterWorkflowStep and LoopWorkflowStep types. all_propagateI have an idea for a "Channel" type that would make it possible to support various concurrency cases, including this one. I'll write something up in another ticket. Qualify the
|
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
|
This issue has been mentioned on Common Workflow Language Discourse. There might be relevant details there: https://cwl.discourse.group/t/loop-requirement-implementation/611/1 |
|
This issue has been mentioned on Common Workflow Language Discourse. There might be relevant details there: https://cwl.discourse.group/t/loop-requirement-implementation/611/3 |
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c
Loop construct prototype implemented as an extension, with tests Based upon @GlassOfWhiskey 's work in common-workflow-language/common-workflow-language#495 (comment) With comments from @tetron @mr-c Co-authored-by: GlassOfWhiskey <iacopo.c92@gmail.com>
|
2023 update: the loops extension has been implemented in https://cwltool.readthedocs.io/en/latest/loop.html The proposal for adding loops as a built-in construct for a future version of CWL (v1.3) is at common-workflow-language/cwl-v1.3#5 |
Design sketch for loops.
The distinction between loops and scatter is that loops are explicitly sequential, whereas scatter is a parallel operation.
A looping step consists of a
whilecondition and aloopspecification. Theloopspecification describes how to update the input object for the next iteration. The output of the step defaults to the output of the last iteration, but could also be constructed using the. (note from @mr-c: theresultfield describe in #494resultfield was dropped from how conditionals were implemented in CWL v1.2).The text was updated successfully, but these errors were encountered: