External Worker affinity on ATCs #2312
Comments
|
When registering externally the worker component will proxy over the Garden and Baggageclaim connections via the TSA. This allows operators to only worry about ingress from Worker -> TSA when they're configuring external workers. When when registering externally in "forward mode", the Worker registers with its addresses for BaggageClaim and Garden as the proxied addresses for the TSA. The ATC needs the worker to keep that connection alive, because if the TCP connection closes in the middle of the ATC using it, panic will ensue! CHAOS! ... basically the ATC won't be able to talk to workers if they're in the middle of a rebalance that closes off the connection to the TSA.. For reference: |
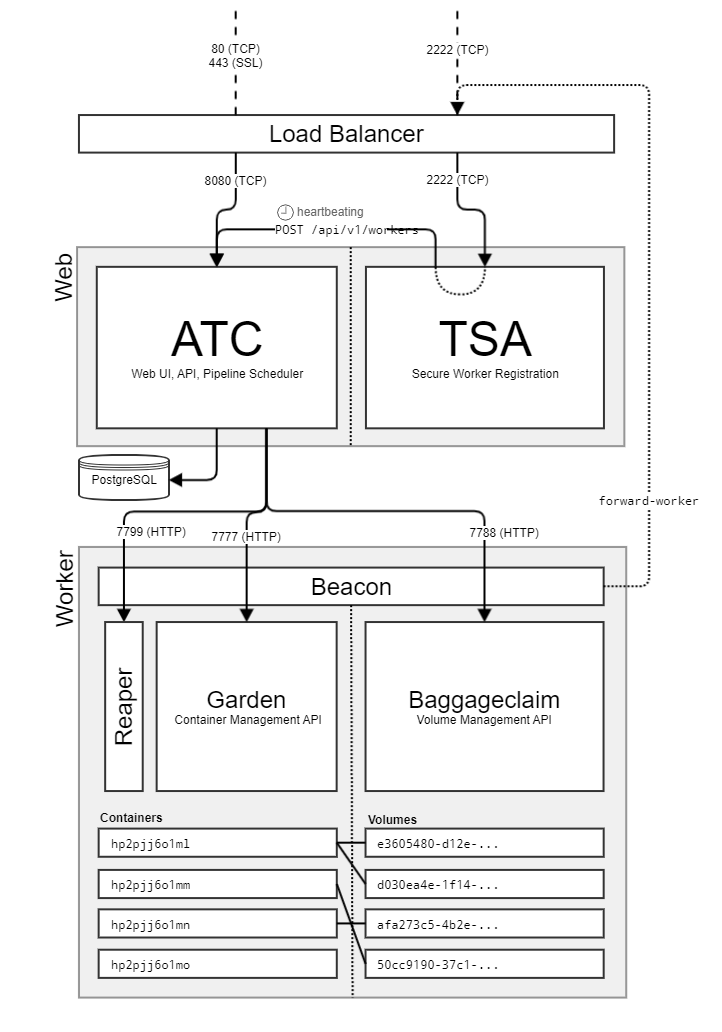
|
Just a few related questions: |
|
Considerations here:
|
|
hi @keithkroeger, when you were seeing all workers registered through one atc, what is the resource consumption on all atc nodes eg. CPU, memory and network throughput? Thx. |
|
Branch - atc-affinity#2312 |
|
Hello @xtremerui no information about network to mind, unfortunately. |
|
Changes that will be required on the ATC
|
any thoughts on that ? |
|
As part of this feature, we will be introducing a few parameters to the Worker that are noteworthy. Let us know if you have any thoughts or concerns ? |
- drainer will check process every second
This addresses a pre-existing race condition
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- drainer will check process every second
This addresses a pre-existing race condition
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- drainer will check process every second
This addresses a pre-existing race condition
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- drainer will check process every second
This addresses a pre-existing race condition
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- applies to forward workers Signed-off-by: Sameer Vohra <svohra@pivotal.io>
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
|
We updated the properties to simplify things as such; |
|
Hello @xtreme-sameer-vohra, are the various commits also containing some documentation for us poor users ? :-) |
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- beacon -> land, retire, delete Signed-off-by: Sameer Vohra <svohra@pivotal.io>
- fix keepalive strict checking for tcpConn Signed-off-by: Sameer Vohra <svohra@pivotal.io>
Signed-off-by: Sameer Vohra <svohra@pivotal.io>
This commit adds an ops file so that users can make use of the configurable worker rebalancing interval. concourse/concourse#2312 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
This commit adds an ops file so that users can make use of the configurable worker rebalancing interval. concourse/concourse#2312 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
- Make use of the worker healthcheck endpoint Previously, the liveness probe of the worker was based on logs, which could end up killing the whole worker in the case of a malformed pipeline. Now, making use of the native concourse healthchecking that the workers provide, we can delegate to concourse the task of telling k8s if it's alive or not. Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> Signed-off-by: Saman Alvi <salvi@pivotal.io> - Make use of signals to terminate workers Instead of making use of `concourse retire-worker` which initiates a connection to the TSA to then retire the worker, we can instead make use of the newly introduced mechanism of sending signals to the worker to tell it to retire, being less error-prone. The idea of this commit is to do similar to what's done for Concourse's official BOSH releases (see concourse/concourse-bosh-release@a3ebf6a?diff=split) Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes GARDEN_ env in favor of config file On the 5.x series of Concourse, there's no need to have all the garden flags specified as environment variables anymore. That's because the new image assumes that a `gdn` binary is shipped together, which can look for a set of configurations from a specific config file. The set of possible values that can be used in the configuration file can be found here [1]. [1]: https://github.com/cloudfoundry/guardian/blob/c1f268e69cd204e891f29bb020e32284a0054606/gqt/runner/runner.go#L41-L93 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes references to fatal errors Previously, the Helm chart made use of a set of possible fatal errors that either `garden` or `baggageclaim` would produce, terminating the worker pod in those cases. Now, making use of the worker probing endpoint (see [1]), we're able to implement better strategies for determining whether the worker is up or not while not changing the contract that `health_ip:health_port` gives back the info that the worker is alive or not. [1]: concourse/concourse@c3b26a0 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Updates env to match concourse 5.x There were some changes to some variables in the next release of concourse. - Introduces bitbucket cloud auth variables In Concourse 5 it becomes possible to make use of Bitbucket cloud as an authenticator (see [1]). This commit includes the variables necessary for doing so, as well as the necessary keys under `secrets` to have those variables injected into web's environment. [1]: concourse/concourse#2631 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Add captureErrorMetrics and rebalanceInterval flags - RebalanceInterval: concourse/concourse#2312 - CaptureErrorMetrics: concourse/concourse#2754 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
- Make use of the worker healthcheck endpoint Previously, the liveness probe of the worker was based on logs, which could end up killing the whole worker in the case of a malformed pipeline. Now, making use of the native concourse healthchecking that the workers provide, we can delegate to concourse the task of telling k8s if it's alive or not. Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> Signed-off-by: Saman Alvi <salvi@pivotal.io> - Make use of signals to terminate workers Instead of making use of `concourse retire-worker` which initiates a connection to the TSA to then retire the worker, we can instead make use of the newly introduced mechanism of sending signals to the worker to tell it to retire, being less error-prone. The idea of this commit is to do similar to what's done for Concourse's official BOSH releases (see concourse/concourse-bosh-release@a3ebf6a?diff=split) Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes GARDEN_ env in favor of config file On the 5.x series of Concourse, there's no need to have all the garden flags specified as environment variables anymore. That's because the new image assumes that a `gdn` binary is shipped together, which can look for a set of configurations from a specific config file. The set of possible values that can be used in the configuration file can be found here [1]. [1]: https://github.com/cloudfoundry/guardian/blob/c1f268e69cd204e891f29bb020e32284a0054606/gqt/runner/runner.go#L41-L93 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes references to fatal errors Previously, the Helm chart made use of a set of possible fatal errors that either `garden` or `baggageclaim` would produce, terminating the worker pod in those cases. Now, making use of the worker probing endpoint (see [1]), we're able to implement better strategies for determining whether the worker is up or not while not changing the contract that `health_ip:health_port` gives back the info that the worker is alive or not. [1]: concourse/concourse@c3b26a0 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Updates env to match concourse 5.x There were some changes to some variables in the next release of concourse. - Introduces bitbucket cloud auth variables In Concourse 5 it becomes possible to make use of Bitbucket cloud as an authenticator (see [1]). This commit includes the variables necessary for doing so, as well as the necessary keys under `secrets` to have those variables injected into web's environment. [1]: concourse/concourse#2631 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Add captureErrorMetrics and rebalanceInterval flags - RebalanceInterval: concourse/concourse#2312 - CaptureErrorMetrics: concourse/concourse#2754 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
|
Re-branding this as an enhancement - we never supported worker rebalancing, so this was a whole new feature, not a misbehavior. |
- Make use of the worker healthcheck endpoint Previously, the liveness probe of the worker was based on logs, which could end up killing the whole worker in the case of a malformed pipeline. Now, making use of the native concourse healthchecking that the workers provide, we can delegate to concourse the task of telling k8s if it's alive or not. Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> Signed-off-by: Saman Alvi <salvi@pivotal.io> - Make use of signals to terminate workers Instead of making use of `concourse retire-worker` which initiates a connection to the TSA to then retire the worker, we can instead make use of the newly introduced mechanism of sending signals to the worker to tell it to retire, being less error-prone. The idea of this commit is to do similar to what's done for Concourse's official BOSH releases (see concourse/concourse-bosh-release@a3ebf6a?diff=split) Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes GARDEN_ env in favor of config file On the 5.x series of Concourse, there's no need to have all the garden flags specified as environment variables anymore. That's because the new image assumes that a `gdn` binary is shipped together, which can look for a set of configurations from a specific config file. The set of possible values that can be used in the configuration file can be found here [1]. [1]: https://github.com/cloudfoundry/guardian/blob/c1f268e69cd204e891f29bb020e32284a0054606/gqt/runner/runner.go#L41-L93 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes references to fatal errors Previously, the Helm chart made use of a set of possible fatal errors that either `garden` or `baggageclaim` would produce, terminating the worker pod in those cases. Now, making use of the worker probing endpoint (see [1]), we're able to implement better strategies for determining whether the worker is up or not while not changing the contract that `health_ip:health_port` gives back the info that the worker is alive or not. [1]: concourse/concourse@c3b26a0 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Updates env to match concourse 5.x There were some changes to some variables in the next release of concourse. - Introduces bitbucket cloud auth variables In Concourse 5 it becomes possible to make use of Bitbucket cloud as an authenticator (see [1]). This commit includes the variables necessary for doing so, as well as the necessary keys under `secrets` to have those variables injected into web's environment. [1]: concourse/concourse#2631 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Add captureErrorMetrics and rebalanceInterval flags - RebalanceInterval: concourse/concourse#2312 - CaptureErrorMetrics: concourse/concourse#2754 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
- Make use of the worker healthcheck endpoint Previously, the liveness probe of the worker was based on logs, which could end up killing the whole worker in the case of a malformed pipeline. Now, making use of the native concourse healthchecking that the workers provide, we can delegate to concourse the task of telling k8s if it's alive or not. Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> Signed-off-by: Saman Alvi <salvi@pivotal.io> - Make use of signals to terminate workers Instead of making use of `concourse retire-worker` which initiates a connection to the TSA to then retire the worker, we can instead make use of the newly introduced mechanism of sending signals to the worker to tell it to retire, being less error-prone. The idea of this commit is to do similar to what's done for Concourse's official BOSH releases (see concourse/concourse-bosh-release@a3ebf6a?diff=split) Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes GARDEN_ env in favor of config file On the 5.x series of Concourse, there's no need to have all the garden flags specified as environment variables anymore. That's because the new image assumes that a `gdn` binary is shipped together, which can look for a set of configurations from a specific config file. The set of possible values that can be used in the configuration file can be found here [1]. [1]: https://github.com/cloudfoundry/guardian/blob/c1f268e69cd204e891f29bb020e32284a0054606/gqt/runner/runner.go#L41-L93 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes references to fatal errors Previously, the Helm chart made use of a set of possible fatal errors that either `garden` or `baggageclaim` would produce, terminating the worker pod in those cases. Now, making use of the worker probing endpoint (see [1]), we're able to implement better strategies for determining whether the worker is up or not while not changing the contract that `health_ip:health_port` gives back the info that the worker is alive or not. [1]: concourse/concourse@c3b26a0 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Updates env to match concourse 5.x There were some changes to some variables in the next release of concourse. - Introduces bitbucket cloud auth variables In Concourse 5 it becomes possible to make use of Bitbucket cloud as an authenticator (see [1]). This commit includes the variables necessary for doing so, as well as the necessary keys under `secrets` to have those variables injected into web's environment. [1]: concourse/concourse#2631 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Add captureErrorMetrics and rebalanceInterval flags - RebalanceInterval: concourse/concourse#2312 - CaptureErrorMetrics: concourse/concourse#2754 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
- Make use of the worker healthcheck endpoint Previously, the liveness probe of the worker was based on logs, which could end up killing the whole worker in the case of a malformed pipeline. Now, making use of the native concourse healthchecking that the workers provide, we can delegate to concourse the task of telling k8s if it's alive or not. Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> Signed-off-by: Saman Alvi <salvi@pivotal.io> - Make use of signals to terminate workers Instead of making use of `concourse retire-worker` which initiates a connection to the TSA to then retire the worker, we can instead make use of the newly introduced mechanism of sending signals to the worker to tell it to retire, being less error-prone. The idea of this commit is to do similar to what's done for Concourse's official BOSH releases (see concourse/concourse-bosh-release@a3ebf6a?diff=split) Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes GARDEN_ env in favor of config file On the 5.x series of Concourse, there's no need to have all the garden flags specified as environment variables anymore. That's because the new image assumes that a `gdn` binary is shipped together, which can look for a set of configurations from a specific config file. The set of possible values that can be used in the configuration file can be found here [1]. [1]: https://github.com/cloudfoundry/guardian/blob/c1f268e69cd204e891f29bb020e32284a0054606/gqt/runner/runner.go#L41-L93 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Removes references to fatal errors Previously, the Helm chart made use of a set of possible fatal errors that either `garden` or `baggageclaim` would produce, terminating the worker pod in those cases. Now, making use of the worker probing endpoint (see [1]), we're able to implement better strategies for determining whether the worker is up or not while not changing the contract that `health_ip:health_port` gives back the info that the worker is alive or not. [1]: concourse/concourse@c3b26a0 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Updates env to match concourse 5.x There were some changes to some variables in the next release of concourse. - Introduces bitbucket cloud auth variables In Concourse 5 it becomes possible to make use of Bitbucket cloud as an authenticator (see [1]). This commit includes the variables necessary for doing so, as well as the necessary keys under `secrets` to have those variables injected into web's environment. [1]: concourse/concourse#2631 Signed-off-by: Ciro S. Costa <cscosta@pivotal.io> - Add captureErrorMetrics and rebalanceInterval flags - RebalanceInterval: concourse/concourse#2312 - CaptureErrorMetrics: concourse/concourse#2754 - Removes flags in web cmd and add missing flags - Introduce TSA_DEBUG* variables - uses *bind for healthcheck variables - update worker debug flags - update debug-bind-* variables for baggageclaim Signed-off-by: Ciro S. Costa <cscosta@pivotal.io>
We've observed situations where external workers will be unusually attached to web node (ATC/TSA) when an additional web node is added. The re-balancing of workers doesn't seem to happen as it should
cc @topherbullock
The text was updated successfully, but these errors were encountered: