
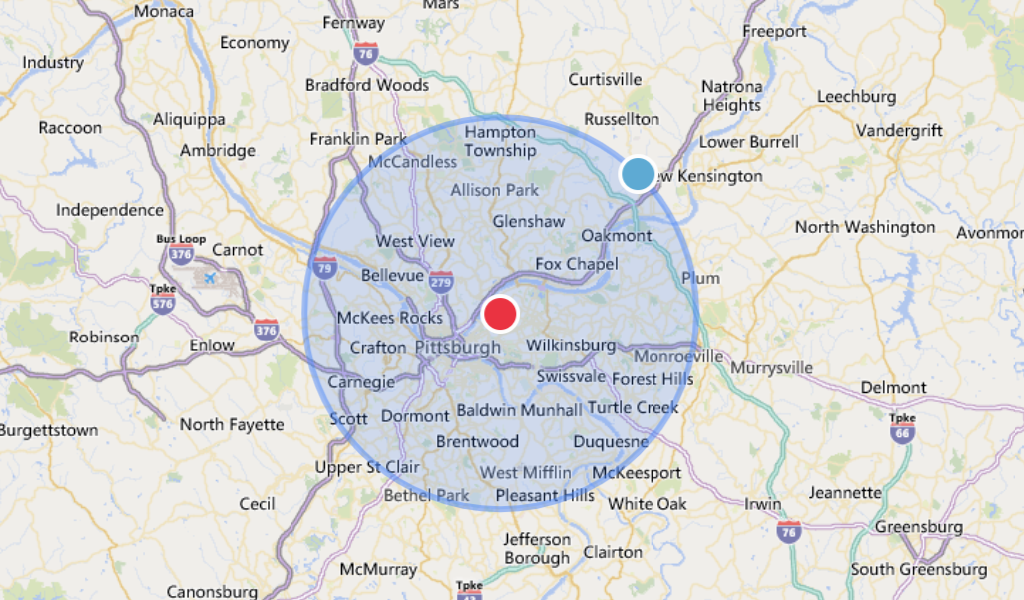
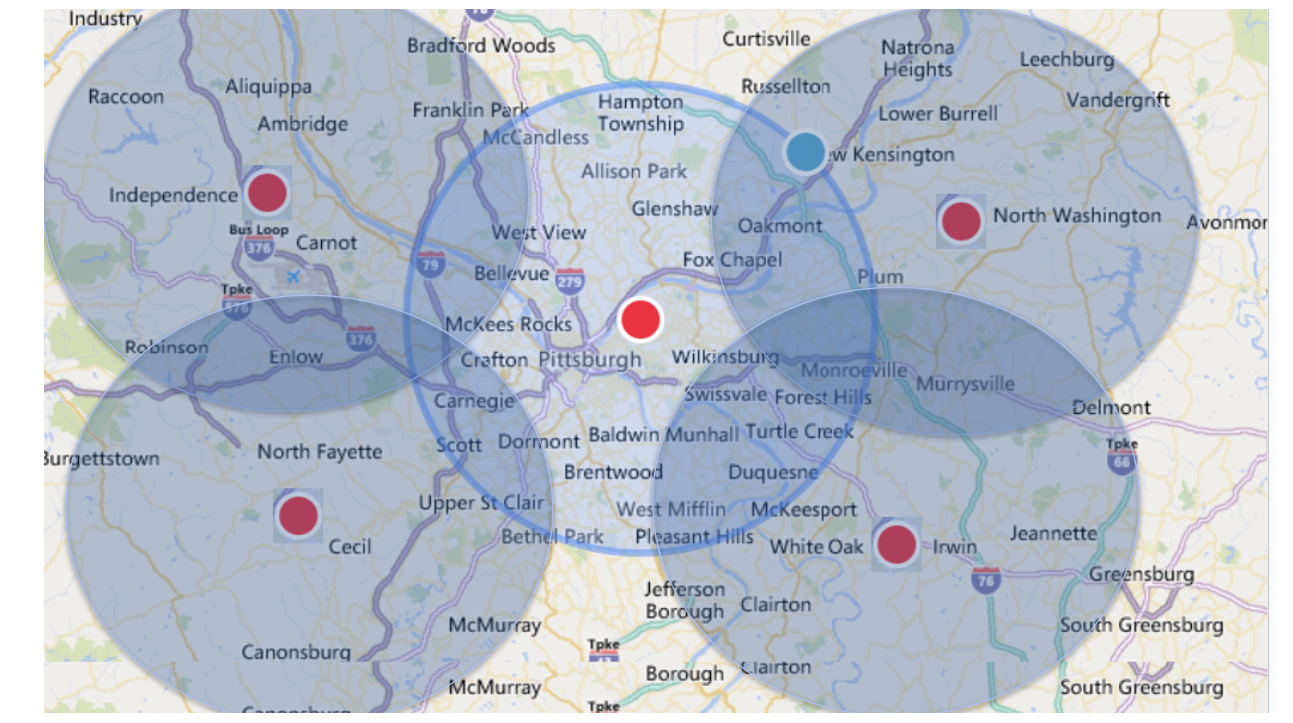
Determining nearby locations to a point on a map becomes difficult as datasets grow larger. For "small" datasets a direct comparison of distance can be used but does not scale as your data grows. To scale, a technique called geohashing is used but is not accurate due to how points are compared.
This solution provides accuracy and scale using Spark's distributed data processing as well as high performant caching. In this repo we demonstrate how you can use Spark's Serverless SQL for a high performant cache or a cloud's NoSQL (the example provided here is using CosmosDB). This can be extended to other NoSQLs like BigTable, DynamoDB, and MongoDB.
- Attach jar from this Github repo (under "releases") as a cluster library to a cluster running Spark 3.3.1, Scala 2.12
- Download and attach the Spark JDBC Driver as a cluster library
Data Dictionary ofinput/output can be found below.
import com.databricks.industry.solutions.geospatial.searches._
implicit val spark2 = spark
//Configuration Spark Serverless Connection
//For generating your auth token in your JDBC URL connection, see https://docs.databricks.com/dev-tools/auth.html#pat
val jdbcUrl = "jdbc:spark://eastus2.azuredatabricks.net:443/default...UID=token;PWD=XXXX"
val tempWorkTable = "geospatial_searches.sample_temp"
//Search Input Paramaters
val originTable="geospatial_searches.origin_locations"
val neighborTable="geospatial_searches.neighbor_locations"
val radius=5
val measurementType="miles"
val maxResults = 100
val degreeOfDataParallelism = 48 //This value should match the # of CPUs your cluster has. Increase for more parallelism (faster)
//Running the algorithm
val ds = SparkServerlessDS.fromDF(spark.table(neighborTable), jdbcUrl, tempWorkTable).asInstanceOf[SparkServerlessDS]
val searchRDD = ds.toInqueryRDD(spark.table(originTable), radius, maxResults, measurementType).repartition(degreeOfDataParallelism)
val resultRDD = ds.search(searchRDD)
val outputDF = ds.fromSearchResultRDD(resultRDD)
//Saving the results
outputDF.write.mode("overwrite").saveAsTable("geospatial_searches.search_results")For healthcare a common challenge is to find the most appropriate quality care for a member. In 01_geospatial_searches we demonstrate solving this problem using a sample dataset from Ribbon for a Medicare Advantage plan in the Los Angeles area to find and prioritize member care.
As of this release, Ribbon's Provider Directory data includes NPIs, practice locations, contact information with confidence scores, specialties, location types, relative cost and experience, areas of focus, and accepted insurance. The dataset also has broad coverage, including 99.9% of providers, 1.7M unique service locations, and insurance coverage for 90.1% of lives covered across all lines of business and payers. The data is continuously checked and cross-checked to ensure the most up-to-date information is shown. More information can be found in Databricks Marketplace
Disclaimer: By receiving and using the data being provided by Ribbon Health, the user accepts, acknowledges and agrees that the data, and any results therefrom is provided “as is” and to the fullest extent permitted by law, Ribbon Health disclaims all warranties, express or implied, including, but not limited to, implied warranties of merchantability, fitness for a particular purpose, or any warranty arising from a course of dealing, usage or trade practice. Ribbon Health does not warrant that the data will be error free or will integrate with systems of any third party.
Two tables are required with columns specified below. One is considered to have origin points and the other is neighborhoods to be found around points of origin (note these 2 datasets can refer to the same table). Duplicate locations with different IDs in the table are also acceptable.
| Column | Description | Expected Type |
|---|---|---|
| id | A unique identifier to be used to re-identify records and relate back to other datasets | String |
| latitude | the latitude value of the location | Double |
| longitude | the longitude value of the location | Double |
Warning It is best practice to filter out invalid lat/long values. This can cause cartesian products and greatly increase runtimes.
| Column | Description |
|---|---|
| origin.id | Origin table's ID column |
| origin.latitude | Origin table's latitude coordinate |
| origin.longitude | Origin table's longitude coordinate |
| searchSpace | The geohash searched. Larger string lengths equates to small search spaces (faster) and vice versa holds true |
| searchTimerSeconds | The number of seconds it took to find all neighbors for the origin point |
| neighbors | Array of matching results. Pivot to rows using explode() function |
| neighbors.value.id | Surrounding neighbor's ID column |
| neighbors.value.latitude | Surrounding neighbor's latitude coordinate |
| neighbors.value.longitude | Surrounding neighbor's longitude coordinate |
| neighbors.euclideanDistance | Distance between origin point and neighbor. The Unit is either Km or Mi matching the input specified |
| neighbors.ms | The unit of measurement for euclideanDistance (miles or kilometers) |
Search performance varies depending on several factors: size of origin and neighborhood tables, density of locations, search radius, and max results. General guidance for using Spark indexes (Z-order by) is provided below. Search time is included in the output data dictionary for the purpose of further fine tuning results.
| Neighborhood table size | Avg Search Time Per Record | Origin Table Throughput: 100 partitions | Origin Table Throughput: 440 partitions | Origin Table Throughput: 3000 partitions |
|---|---|---|---|---|
| 10K+ | 0.2s | 30K per minute | 132K per minute | 900K per minute |
| 100K+ | 0.5s | 12K per minute | 52K per minute | 360K per minute |
| 1M+ | 1.2s | 5K per minute | 21K per minute | 144K per minute |
DistanceInKm() and DistanceInMi() functions.
Input order: lat1, long1, lat2, long2
%python
from pyspark.sql.types import *
spark.udf.registerJavaFunction("distanceMi", "com.databricks.industry.solutions.geospatial.searches.DistanceInMi", DoubleType())
%sql
SELECT distanceMi("42.5787980", "-71.5728", "42.461886", "-71.5485457") -- 8.1717 (miles)Databricks's Mosiac offers a rich feature set of analytical functions used for Geospatial analysis.
Knowing which points are nearby is helpful. Given a proximity of a series of points this use case can be extended to include personalized driving information using OSRM on Databricks
Please note the code in this project is provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects. The source in this project is provided subject to the Databricks License. All included or referenced third party libraries are subject to the licenses set forth below.
Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.
Open Source libraries used in this project
| library | description | license | source | coordinates |
|---|---|---|---|---|
| Geohashes | Converting Lat/Long to a Geohash | Apache 2.0 | https://github.com/kungfoo/geohash-java | ch.hsr:geohash:1.4.0 |
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
Included in this repo is an example implementation of using Azure's CosmosDB as a data cache. Other NoSQLs can be supported by implementing the DataStore trait.
| library | description | license | source | coordinates |
|---|---|---|---|---|
| Spark + Azure Cosmos | Connecting DataFrames to CosmosDB | MIT | https://github.com/Azure/azure-cosmosdb-spark | com.azure.cosmos.spark:azure-cosmos-spark_3-2_2-12:4.11.2 |
| Azure Cosmos Client | Connectivity to CosmosDB | MIT | https://github.com/Azure/azure-cosmosdb-java | com.azure:azure-cosmos:4.39.0 |
- Attach jar from repo as a cluster library
- Install Azure/Databricks related libraries above using Maven coordinates
- Create An Azure NoSQL Container for document storage (Recommended setting index policy on Cosmos)
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [],
"excludedPaths": [
{
"path": "/*"
},
{
"path": "/\"_etag\"/?"
}
]
}import com.azure.cosmos.spark._, com.azure.cosmos.spark.CosmosConfig, com.azure.cosmos.spark.CosmosAccountConfig, com.databricks.industry.solutions.geospatial.searches._
implicit val spark2 = spark
// Provide Connection Details, replace the below settings
val cosmosEndpoint = "https://XXXX.documents.azure.com:443/"
val cosmosMasterKey = "..."
val cosmosDatabaseName = "GeospatialSearches"
val cosmosContainerName = "GeoMyTable"
// Configure NoSQL Connection Params
//https://github.com/Azure/azure-sdk-for-java/blob/main/sdk/cosmos/azure-cosmos-spark_3_2-12/docs/migration.md
implicit val cfg = Map("spark.cosmos.accountEndpoint" -> cosmosEndpoint,
"spark.cosmos.accountKey" -> cosmosMasterKey,
"spark.cosmos.database" -> cosmosDatabaseName,
"spark.cosmos.container" -> cosmosContainerName,
"spark.cosmos.write.bulk.enabled" -> "true",
"spark.cosmos.write.strategy" -> "ItemOverwrite"
)
//Populate the NoSQL DataStore from the first dataset
val ds = CosmosDS.fromDF(spark.table(searchTable), cfg)
//Set radius to search for
val radius=25
val maxResults = 5
val measurementType="miles"
//Set the tables for search (same table in this case)
val targetTable = "geospatial_searches.sample_facilities"
val searchTable = "geospatial_searches.sample_facilities"
//Secondary dataset search (We're using same dataset for both tables)
val searchRDD = ds.toInqueryRDD(spark.sql(targetTable), radius, maxResults, measurementType)
//Perform search and save results
val resultRDD = ds.asInstanceOf[CosmosDS].search(searchRDD)
ds.fromSearchResultRDD(resultRDD).write.mode("overwrite").saveAsTable("geospatial_searches.sample_results")