DataFibers (DF) - A pure streaming processing application on Kafka and Flink. The DF processor has two components defined to deal with stream ETL (Extract, Transform, and Load).
- Connects is to leverage Kafka Connect REST API on Confluent to landing or publishing data in or out of Apache Kafka.
- Transforms is to leverage streaming processing engine, such as Apache Flink, for data transformation.
You build the project using:
mvn clean package
The application is tested using vertx-unit.
The application is packaged as a fat jar, using the Maven Shade Plugin.
Once packaged, just launch the fat jar as follows ways
- Default with no parameters to launch standalone mode with web ui.
java -jar df-data-service-<version>-SNAPSHOT-fat.jar
- For more running features checking help option
java -jar df-data-service-<version>-SNAPSHOT-fat.jar -h
http://localhost:8000/ or http://localhost:8000/dfa/
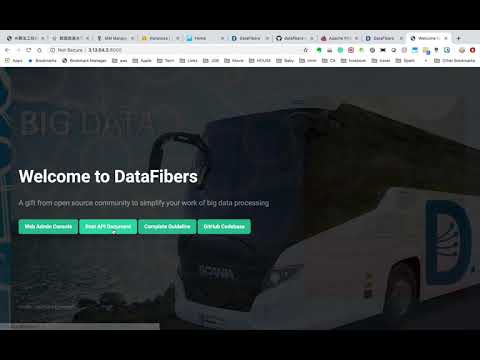
https://datafibers-community.gitbooks.io/datafibers-complete-guide/content/
- Fetch all installed connectors/plugins in regularly frequency
- Need to report connector or job status
- Need an initial method to import all available|paused|running connectors from kafka connect
- Add Flink Table API engine
- Add memory LKP
- Add Connects, Transforms Logging URL
- Add to generic function to do connector validation before creation
- Add submit other job actions, such as start, hold, etc
- Add Spark Structure Streaming
- Topic visualization
- Launch 3rd party jar
- Job level control, schedule, and metrics