Performance regression: Intel GDS mitigation (aka Downfall) #15873
Comments
|
The performance impact on The concerning aspect is that those routines are not even that dominated by the affected instructions, there is a lot of floating point math around them. The open PR #14324, which I opened to further increase performance by extending the use of |
|
FYI @bergbauer @nfehn @richardschu we need to be careful when measuring performance, the impact of GDS mitigations on performance is dramatic. |
@tamiko It is very important that we keep the old numbers as the data of what performance should be (or could be). We should then compare new modifications against these numbers. |
|
@kronbichler I will retain the current history and we will have to live with the kink in the graphs :-( |
|
Update: This is a performance tester run where the last 4 commits have the microcode mitigation: |
|
Indeed, the drop in performance is really bad, the worst numbers for |
|
#15875 is merged and the first results are in: https://dealii.org/performance_tests//reports/render.html?#!53ac485e6801587a97bce6ebca3cd11dc4f6ecb4.md - it helps less than I had hoped for, in particular I see even worse results for |
|
@kronbichler I have read that clang will gain an "avoid gather instructions" flag as well (gcc should already have one). Maybe this will help. |
Only Intel allows you to root your CPU (Bigcore) and PCH main core and get to very low level debugger, even on ucode level. No one else does. Yes, they never wanted to allow it. But haha. 🙃 |
|
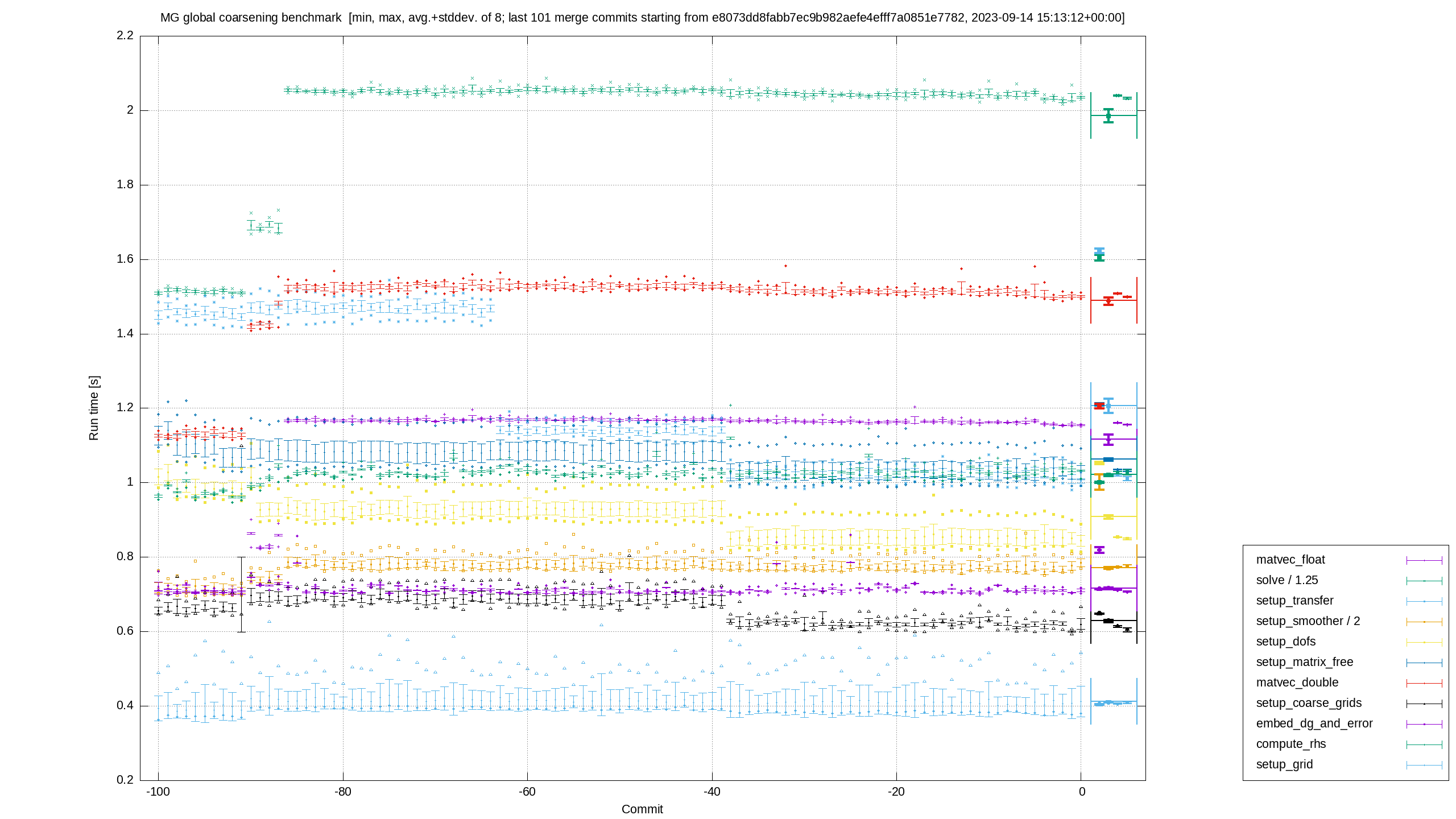
For assessing the slowdown after the merge of #15875 from figure https://dealii.org/performance_tests/graphs//whistler-gentoo-clang-16/e8073dd8fabb7ec9b982aefe4efff7a0851e7782-timing-mg_glob_coarsen.average.png in the benchmark .LBB608_102: # %.critedge257
# =>This Inner Loop Header: Depth=1
vpmovzxdq (%rcx,%rdi), %ymm1 # ymm1 = mem[0],zero,mem[1],zero,mem[2],zero,mem[3],zero
vpmovzxdq 16(%rcx,%rdi), %ymm2 # ymm2 = mem[0],zero,mem[1],zero,mem[2],zero,mem[3],zero
vxorps %xmm3, %xmm3, %xmm3
kxnorw %k0, %k0, %k1
vgatherqps (%rdx,%ymm2,4), %xmm3 {%k1}
vxorps %xmm4, %xmm4, %xmm4
kxnorw %k0, %k0, %k1
vgatherqps (%rdx,%ymm1,4), %xmm4 {%k1}
vpmovzxdq 32(%rcx,%rdi), %ymm5 # ymm5 = mem[0],zero,mem[1],zero,mem[2],zero,mem[3],zero
vpmovzxdq 48(%rcx,%rdi), %ymm6 # ymm6 = mem[0],zero,mem[1],zero,mem[2],zero,mem[3],zero
vxorps %xmm7, %xmm7, %xmm7
kxnorw %k0, %k0, %k1
vgatherqps (%rdx,%ymm6,4), %xmm7 {%k1}
vxorps %xmm8, %xmm8, %xmm8
kxnorw %k0, %k0, %k1
vgatherqps (%rdx,%ymm5,4), %xmm8 {%k1}
vpsllq $2, %ymm1, %ymm1
vpaddq %ymm1, %ymm0, %ymm1
vinsertf128 $1, %xmm7, %ymm8, %ymm7
vaddps 32(%rax,%rdi), %ymm7, %ymm7
vinsertf128 $1, %xmm3, %ymm4, %ymm3
vaddps (%rax,%rdi), %ymm3, %ymm3
vmovq %xmm1, %r8
vmovss %xmm3, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $1, %xmm3, (%r8)
vpsllq $2, %ymm5, %ymm4
vextracti128 $1, %ymm1, %xmm1
vmovq %xmm1, %r8
vextractps $2, %xmm3, (%r8)
vpaddq %ymm4, %ymm0, %ymm4
vpextrq $1, %xmm1, %r8
vextractps $3, %xmm3, (%r8)
vpsllq $2, %ymm2, %ymm1
vpaddq %ymm1, %ymm0, %ymm1
vextracti128 $1, %ymm3, %xmm2
vmovq %xmm1, %r8
vmovd %xmm2, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $1, %xmm2, (%r8)
vextracti128 $1, %ymm1, %xmm1
vmovq %xmm1, %r8
vextractps $2, %xmm2, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $3, %xmm2, (%r8)
vmovq %xmm4, %r8
vmovss %xmm7, (%r8)
vpextrq $1, %xmm4, %r8
vextractps $1, %xmm7, (%r8)
vextracti128 $1, %ymm4, %xmm1
vmovq %xmm1, %r8
vextractps $2, %xmm7, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $3, %xmm7, (%r8)
vpsllq $2, %ymm6, %ymm1
vpaddq %ymm1, %ymm0, %ymm1
vextracti128 $1, %ymm7, %xmm2
vmovq %xmm1, %r8
vmovd %xmm2, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $1, %xmm2, (%r8)
vextracti128 $1, %ymm1, %xmm1
vmovq %xmm1, %r8
vextractps $2, %xmm2, (%r8)
vpextrq $1, %xmm1, %r8
vextractps $3, %xmm2, (%r8)
addq $64, %rdi
cmpq %rdi, %rsi
jne .LBB608_102while it is for gcc (note that this processes only 8 elements at time, not all 16): movl (%rax), %edi
movl 4(%rax), %r14d
leaq 0(%r13,%rdi,4), %r12
vmovss (%r12), %xmm4
leaq 0(%r13,%r14,4), %rsi
vaddss (%rcx), %xmm4, %xmm11
movl 8(%rax), %edx
addq $32, %rax
vmovss %xmm11, (%r12)
vmovss (%rsi), %xmm12
leaq 0(%r13,%rdx,4), %rdi
vaddss 64(%rcx), %xmm12, %xmm10
movl -20(%rax), %r12d
addq $512, %rcx
vmovss %xmm10, (%rsi)
vmovss (%rdi), %xmm3
leaq 0(%r13,%r12,4), %r14
vaddss -384(%rcx), %xmm3, %xmm5
movl -16(%rax), %esi
vmovss %xmm5, (%rdi)
vmovss (%r14), %xmm8
leaq 0(%r13,%rsi,4), %rdx
vaddss -320(%rcx), %xmm8, %xmm2
movl -12(%rax), %edi
vmovss %xmm2, (%r14)
vmovss (%rdx), %xmm6
leaq 0(%r13,%rdi,4), %r12
vaddss -256(%rcx), %xmm6, %xmm14
movl -8(%rax), %r14d
vmovss %xmm14, (%rdx)
vmovss (%r12), %xmm15
leaq 0(%r13,%r14,4), %rsi
vaddss -192(%rcx), %xmm15, %xmm1
movl -4(%rax), %edx
vmovss %xmm1, (%r12)
vmovss (%rsi), %xmm7
leaq 0(%r13,%rdx,4), %rdi
vaddss -128(%rcx), %xmm7, %xmm0
vmovss %xmm0, (%rsi)
vmovss (%rdi), %xmm9
vaddss -64(%rcx), %xmm9, %xmm13
vmovss %xmm13, (%rdi)
cmpq %r8, %rax
jne .L30758Without disabling the scatter instructions, clang-16 generates movq (%r11), %r9
movq 160(%r9), %r9
vmovups (%rcx), %zmm0
vxorps %xmm1, %xmm1, %xmm1
kxnorw %k0, %k0, %k1
vgatherdps (%r9,%zmm0,4), %zmm1 {%k1}
vaddps -192(%r8), %zmm1, %zmm1
kxnorw %k0, %k0, %k1
vscatterdps %zmm1, (%r9,%zmm0,4) {%k1}
movq (%r11), %r9
movq 160(%r9), %r9
vmovups 64(%rcx), %zmm0
vxorps %xmm1, %xmm1, %xmm1
kxnorw %k0, %k0, %k1
vgatherdps (%r9,%zmm0,4), %zmm1 {%k1}
vaddps -128(%r8), %zmm1, %zmm1
kxnorw %k0, %k0, %k1
vscatterdps %zmm1, (%r9,%zmm0,4) {%k1}
movq (%r11), %r9
movq 160(%r9), %r9
vmovups 128(%rcx), %zmm0
vxorps %xmm1, %xmm1, %xmm1
kxnorw %k0, %k0, %k1
vgatherdps (%r9,%zmm0,4), %zmm1 {%k1}
vaddps -64(%r8), %zmm1, %zmm1
kxnorw %k0, %k0, %k1
vscatterdps %zmm1, (%r9,%zmm0,4) {%k1}
movq (%r11), %r9
movq 160(%r9), %r9
vmovups 192(%rcx), %zmm0
vxorps %xmm1, %xmm1, %xmm1
kxnorw %k0, %k0, %k1
vgatherdps (%r9,%zmm0,4), %zmm1 {%k1}
vaddps (%r8), %zmm1, %zmm1
kxnorw %k0, %k0, %k1
vscatterdps %zmm1, (%r9,%zmm0,4) {%k1}
addq $4, %rsi
addq $256, %rcx # imm = 0x100
addq $256, %r8 # imm = 0x100
cmpq %rsi, %rdi
jne .LBB608_186with the gcc code nearly the same movq 336(%rsp), %rax
vmovdqu32 (%r12,%r9), %zmm5
movq 160(%rax), %r10
kmovw %k0, %k7
vgatherdps (%r10,%zmm5,4), %zmm14{%k7}
vaddps 0(%r13,%r9), %zmm14, %zmm15
kmovw %k0, %k1
kmovw %k0, %k2
vscatterdps %zmm15, (%r10,%zmm5,4){%k1}
movq 336(%rsp), %rbx
vmovdqu32 64(%r12,%r9), %zmm2
movq 160(%rbx), %rdx
kmovw %k0, %k3
vgatherdps (%rdx,%zmm2,4), %zmm1{%k2}
vaddps 64(%r13,%r9), %zmm1, %zmm8
kmovw %k0, %k4
kmovw %k0, %k5
vscatterdps %zmm8, (%rdx,%zmm2,4){%k3}
movq 336(%rsp), %r15
vmovdqu32 128(%r12,%r9), %zmm6
movq 160(%r15), %r11
kmovw %k0, %k6
vgatherdps (%r11,%zmm6,4), %zmm11{%k4}
vaddps 128(%r13,%r9), %zmm11, %zmm9
kmovw %k0, %k7
kmovw %k0, %k1
vscatterdps %zmm9, (%r11,%zmm6,4){%k5}
movq 336(%rsp), %rcx
vmovdqu32 192(%r12,%r9), %zmm4
movq 160(%rcx), %rsi
kmovw %k0, %k2
vgatherdps (%rsi,%zmm4,4), %zmm7{%k6}
vaddps 192(%r13,%r9), %zmm7, %zmm0
kmovw %k0, %k3
kmovw %k0, %k4
vscatterdps %zmm0, (%rsi,%zmm4,4){%k7}
movq 336(%rsp), %rdi
vmovdqu32 256(%r12,%r9), %zmm12
movq 160(%rdi), %r8
kmovw %k0, %k5
vgatherdps (%r8,%zmm12,4), %zmm10{%k1}
vaddps 256(%r13,%r9), %zmm10, %zmm3
kmovw %k0, %k6
kmovw %k0, %k7
vscatterdps %zmm3, (%r8,%zmm12,4){%k2}
movq 336(%rsp), %rax
kmovw %k0, %k1
movq 160(%rax), %r10
vmovdqu32 320(%r12,%r9), %zmm13
vgatherdps (%r10,%zmm13,4), %zmm5{%k3}
vaddps 320(%r13,%r9), %zmm5, %zmm14
vscatterdps %zmm14, (%r10,%zmm13,4){%k4}
movq 336(%rsp), %rbx
vmovdqu32 384(%r12,%r9), %zmm15
movq 160(%rbx), %rdx
vgatherdps (%rdx,%zmm15,4), %zmm2{%k5}
vaddps 384(%r13,%r9), %zmm2, %zmm1
vscatterdps %zmm1, (%rdx,%zmm15,4){%k6}
movq 336(%rsp), %r15
vmovdqu32 448(%r12,%r9), %zmm8
movq 160(%r15), %r11
vgatherdps (%r11,%zmm8,4), %zmm6{%k7}
vaddps 448(%r13,%r9), %zmm6, %zmm11
addq $512, %r9
vscatterdps %zmm11, (%r11,%zmm8,4){%k1}
cmpq %r9, %r14
jne .L30875So to summarize, we see that clang is still emitting some gather instructions (in fact, it does use the more narrow ones with only |
{kind=link}
The performance impact of the microcode patches for the Intel Gather Data Sampling hardware vulnerability are dramatic. This is the first run of the performance testsuite after microcode patches have been applied:
[1] https://dealii.org/performance_tests//reports/render.html?#!233aaa70c2878d61afa282df563961b64265f622.md
All tests that make use of our
VectorizedArrayclass with optimizedgatherinstructions suffer signficantly.This affects just about all but the newest Intel CPUs...
We could simply accept this new state of affairs (and I would be able to redo the entire performance instrumentation over ~2000 merge commits again to get accurate readings).
But honestly, given the fact that the performance regression on current hardware is so bad, we should do something about it. A possible stop-gap measure could be to provide a compile-time switch to either use AVX
gatherinstructions, or an alternative sequence of sequential loads. This should mitigate the worst impact of this.@kronbichler ping What are your thoughts?
[1] The newest run at position "0" in the diagrams is with the newest microcode patches. To the left you see timings for the previous 100 merge commits (from "1" to "100"). (To the right are averages and their standard deviation over the last 1000, 100, 20, and 4 commits, respectively.)
The text was updated successfully, but these errors were encountered: