Make Dgraph work with standard GraphQL #933
Comments
|
http://dpeek.com/dgraphql/ thought you might like this... |
|
We need to have a thorough review of our QL, and see if we can get it to be close to compatibility with GraphQL. |
|
I've setup a GraphQL server as well and seem not to be able to figure out how to get data into and from a Dgraph database. Are there any (simple) examples how I would translate a GraphQL query to a Dgraph query in order t access the persistence layer |
|
We'll make a push to try to reconcile GraphQL+- with GraphQL past v1.0. |
|
In particular, I'd love to see how to make this work with Relay. In terms of streamlining an entire application stack, I think that would be huge! Right now I am using a MySQL-backed relay-compliant GraphQL server with Relay on the front end, in order to use Dgraph, I would need a clear path on how I could keep the benefits (and code) of my current client application. |
|
@manishrjain if you could create something like this for graphql+/-? Perhaps an abstraction layer that would allow folks to use existing standards (gremlin, RDF, etc.). Just read your article on Jupiter. Let's get this ship sailed! |
|
Just another reason to make a graphql-compliant processor: schema stitching. Seems like a natural fit. Microservices and Dgraph. |
|
I think maybe the schema stitching is a bit out of context. If you want to connect Dgraph to a "gateway" in GraphQL for example. You would need to have a GraphQL schema being offered by the Dgraph "natively". Dgraph uses GraphQL +/- only as a query concept. Dgraph does not have a schema defined as GraphQL. Unless natively implemented an option to generate Schemas making http://dpeek.com/dgraphql/ become obsolete. Basically if the Dgraph is to accept GraphQL natively, it will have to create a context mimicking the original idea. GraphQL +/- does not have things like interfaces, Unions, Enums and etc. Or "introspection." That is, the Dgraph Schema is distinct from the GraphQL schema. Then you would need to create an application that does an intermediate between Gateway => service.app with GraphQL end-point to stitch ==> Dgraph related with the service. I believe that if the Dgraph is to do this they will have to do an "imitation game". (joke) |
|
I feel like the best path would be to have an official GraphQL server
implementation that uses DGraph as a backend--or at least some good example
code. Something like JoinMonster or GraphCool, that is a framework that
makes it really easy to use DGraph with GraphQL, hopefully with Relay
support too. Right now, I don't know DGraph, so leaving a RDMS for it seems
a bit daunting, although the promised benefits are appealing. An backend
application framework would make it easier to get started.
…On Sun, Dec 31, 2017 at 9:59 AM, Michel Conrado ***@***.***> wrote:
I think maybe the schema stitching is a bit out of context. If you want to
connect Dgraph to a "gateway" in GraphQL for example. You would need to
have a GraphQL schema being offered by the Dgraph "natively". Dgraph uses
GraphQL +/- only as a query concept. Dgraph does not have a schema defined
as GraphQL. Unless natively implemented an option to generate Schemas
making http://dpeek.com/dgraphql/ become obsolete.
Basically if the Dgraph is to accept GraphQL natively, it will have to
create a context mimicking the original idea. GraphQL +/- does not have
things like interfaces, Unions, Enums and etc. Or "introspection."
That is, the Dgraph Schema is distinct from the GraphQL schema. Then you
would need to create an application that does an intermediate between
Gateway => service.app with GraphQL end-point to stitch ==> Dgraph related
with the service.
I believe that if the Dgraph is to do this they will have to do an
"imitation game". (joke)
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#933 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAbbLiBfK4ffWixy5TPRXNZMXRbxMEFxks5tF710gaJpZM4NY_Jn>
.
|
|
Yeah, a dialect in Join Monster would be the perfect strategy. Since JM (Join Monster) would only read the schema created and hence generate the queries in accordance with what was required. I had already suggested this while ago (join-monster/join-monster#266). And you can add a dialect that JM can transpose to GraphQL +/- or Cypher. But the problem lies in the other languages. There is no similar project that supports Go Lang, Elixir, Java, Python and so on. Unless Dgraph team take the concept of JM and create their respective code languages supports. But that is beyond the scope of the Dgraph team. |
|
Indeed, a graphdb-based BAAS fronted with GraphQL would be a killer |
|
Might this be a way to do this? |
Link to video from founder explaining this microservices approach |
|
Graphcool just released graph.cool 1.0 under the banner Prisma They are looking to get connectors made for many different databases, including Dgraph. To satisfy the issue, either Dgraph needs to natively handle standard GraphQL queries, or GraphQL queries should be "compiled" into GraphQL+/- (or other supported language e.g. gramlin, cypher). Regardless, the result would be an opinionated way to structure the graph data. Is that fair to say? So, rather than "Make Dgraph work with standard GraphQL", should we instead focus on how such an opinionated data model would look? It doesn't seem necessary to add a so that something like this GraphQL could be compiled or interpreted natively as I am working on a GraphQL API in front of my Dgraph data. I am very fond of how my data is represented in Dgraph and the ease of querying, but I still need to work out the (numerous) kinks in querying/mutating via standard GraphQL. I would love to love to work with and offer my results to the community. A description of my current take is in this gist. |
|
Just a fast comment - I think this is the recommended approach to be considered. https://docs.dgraph.io/howto/#giving-nodes-a-type UPDATE (2019): As we have a type system, this approach is no longer useful. |
|
Thanks @MichelDiz! Would it be prudent to create But I do like this. The |
|
Possible TypeDefinitions object below. I think it would be better if it followed the GraphQL schema AST object format more precisely. Also not included interfaces, indexes, etc., but I just wanted to get this out there. example schema schema example built schema
To validate GraphQL query against a type definition like the one below, perhaps facets would need to be described as a field, but with additional information. e.g.
|
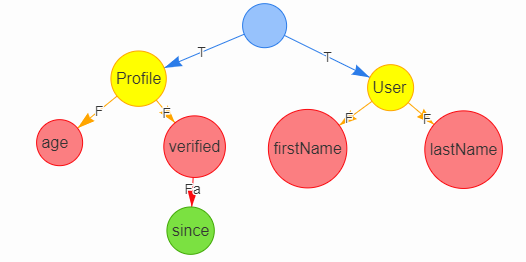
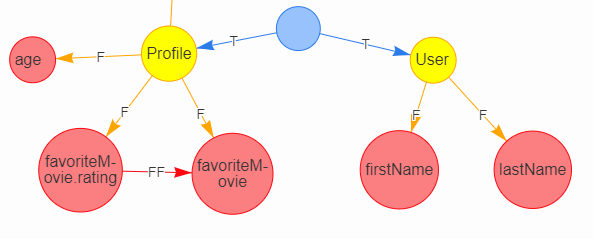
|
Facets of uid predicates vs. facets of scalars presents a dilemma. See standard GraphQL query: I think I offered my examples in a poor order, where the Also not sure how to Type
|

|
@ptpaterson are you trying this actually with Prisma and Dgraph? or just imagining/theorizing? Sounds pretty cool. And if it's, how do you doing? how is your environment of tests? |
|
Anyway this logic could be applied to create a Connector with Primas. Even independent of native Dgraph support. It could be a generic Connector within the Primas that use Dgraph-JS Cliente. These logical definitions could have a "persistent" format in the Connector. So every record made by the Connector would keep a pattern. And when the Prisma Dgraph Connector requested the data again, it would have the same format that it was modulating. So technically you do not need native and perfect support from Dgraph. It would be like Join-Monster. This creates Queries based on GraphQL Schema AST. Refs: |
|
Thank you for sharing your thoughts. Do you by any chance have a sample code to share? I would love to see what you have and contribute to it if I can |
|
Dgraph already natively supports a modified version of GraphQL. So, supporting the official spec would be native and should perform better than the overlay support that Neo4j and others have implemented. |
|
Wow, thanks @sorenhoyer ! I just checked if dgraph is compatible now with apollo - but (though its odd) - learned that neo4j has a graphql api. That helped a lot! PS: This issue is now older than one year... the lack of "native" client compatible GraphQL and a solid way to explore the Graph data with a GUI is a big standing barrier to approach dgraph for any project. I hope you guys make the turn some time. DX is key. I think this was one very bad turning point decision:
|
|
The authors of GraphQL have stressed on multiple occasions that it isn't intended as a complete query language for traversing graph dbs, or server-to-server. It's a server-client API. That's why Dgraph modified the syntax in the first place. Far better than standard GraphQL would be full support of both Gremlin and Cypher. In most cases, there is going to be some incongruity between the storage layer and the API. Some fields should be hidden (passwords), some are computed server-side, etc. There's caching, throttling, authentication and authorization, input validation, etc. Having client-compatible GraphQL really doesn't accomplish much because 99% of the time Dgraph will still have to pass through the API server anyway to implement the things that are far outside the scope of responsibility for a database. I think it would be far more valuable to contribute Dgraph support to something like Prisma. |
|
Prisma support would be awesome |
|
At the end of the day, it doesn’t matter what the technicalities are and what happens under the hood. Having no first class GraphQL<->Client support has inhibited dgraphs outlook as a deal breaker. |
|
I can't think of a realistic production scenario where lack of DB support for GraphQL clients is a deal-breaker. Most production GraphQL API's are backed by MySQL/Postgres or Mongo. And even then, it's probably behind another layer of indirection via an ORM. The lack of GraphQL support on the DB a complete non-issue for the vast majority of GraphQL API's. I'm actually really curious about how this would be used to connect directly to the client in a real-world app. This issue has the participation of less than 1% of the Dgraph userbase because connecting directly to the client via GraphQL is simply not a normal expectation for a DB. |
|
I agree with Frank Dugan. I believe that forcing the Dgraph to keep behind GraphQL might be a disadvantage. Because the Dgraph can evolve to such an extent that it would not be predicted by the current GraphQL language. Several features in Dgraph would not be predicted in GraphQL. Ideally, anyone who wants to have GraphQL support creates an API linked to Dgraph. Today there is dgraphql which is very interesting and there is the possibility of Prisma entering the game. These are valid proposals that do not leave the Dgraph stuck. Nevertheless, perhaps Dgraph could work on internal support for creating a GraphQL API. Just as other DBs provide a REST API. I believe that this can be implemented in the long term. But for those in a hurry, there is dgraphql and maybe Prisma. And I think the advantage of Dgraph being similar GraphQL with GraphQL + - is very good, even though it has several different things. Similarity helps in production. Just that. |
You might want to check the original spec thread by sashko, talk to the Prisma/GraphCool guys or reflect on the general notion, that there seems to be quite some demand to align GraphQL with a “true graph structure” because it decouples one from the limitations of rational databases and homogenizes the skills of the product people with the skills of the analysts (like back in the day with SQL). Anyhow, a top down answer is: If it’s so irrelevant, why did neo4j see the demand and why do people demand it? In the end, this is a matter of seeking adoption. As long as dgraph (without such features) keeps missing the 10x better threshold compared to the next graph database, there is little drive to onboard risk averse peers. |
|
My primary point, which was completely unaddressed, is this: No major database has been shunned in real-world production apps for lack of direct-to-client GraphQL implementations. Facebook does not build it this way, and they designed the spec. They recommend a completely decoupled business logic layer to handle the actual fetching of data from the DB. It's just not best practice to direct connect no matter what the query language. Exceptions being perhaps Firebase/Couchbase, but those examples have pretty serious limitations in functionality. It's not that this style of DB is irrelevant, it's just not realistic to expect all new databases to provide an entire API framework for GraphQL. It's also important to consider leaving open the possibility of a polyglot backend. Dgraph has many other areas of growth that are FAR more important for adoption before this proposal. When a team is evaluating an up-and-coming DB, the primary question is not going to be, "Did they shoehorn the API query language we like into the client drivers?" The questions are going to be the fit to domain model, the constraints, the type system, the reliability, the scalability, the financial situation of the company developing it, etc. Neo4j does not directly support GraphQL. They created a library to translate GraphQL queries into Cypher, the primary purpose being to make it easier to write resolvers. This still requires standing up a GraphQL server. The more advanced features of Cypher are accessed by type annotations on the server-side, not directly accessible to the client because in their words:
I think they know what they're talking about. Bringing up Prisma/Graphcool is actually supporting the idea that direct connections are untenable in the long run. Graphcool originally tried to be a complete framework generated from GraphQL SDL and it proved to be too difficult to handle all the edge cases where the storage layer was different than the operations exposed to the client. With Prisma it basically became an ORM where you still have to stand up your own GraphQL API, and even though one could interface to Prisma with GraphQL, it's usually done via the JS binding like most other ORMs. I felt this growing pain with my production apps, watching feature requests on Github, hoping the features I needed would be released for Graphcool, and can say Prisma was definitely the better way to go. Some people are asking for direct-to-client GraphQL API's for databases, but far from the majority. I used to think this was important, but I think that was my inexperience showing. The idea of being able to bypass writing the API server is tempting, but it only works in very, very simple scenarios, and it burdens the DB with many problematic concerns that already have great solutions in API frameworks. |
|
I believe you get lost between a technical argument and a business one.
Could you point me to the minor ones? People like me have an interest for such alternatives. But yes, you are right — at the end of the day, no major DB has been shunned for a lack of a REPL, Rest, a GUI, Persistance, Vertical Scaling, No Support for standard BI tools and so on — as long it saves data. There is simply a difference between providing a database and a application layer solution. Not rooting for the later is (in my opinion) a mistake. And with the — maybe accidental — use of the GraphQL keywords in the dgraph project description, I only got to follow this project as one of many particularly interested in just that. It’s sad that there is no first class spec conform GraphQL support - and be it a transpiler to the internal specless GraphQL Version. The user does not care. I personally find dgraph after 1,5 years In a “stuck in the middle approach” of not using a industry standard DSL like Cypher but also not implementing / caring / driving “a recent” data layer innovation like GraphQL. Right now, there is little differentiation, more risk and more work to even get started with dgraph as an alternative. And I really looked forward to it being different: https://twitter.com/dinoscheidt/status/946711393209868288?s=21 It’s not. |
|
I don't think I could point to any minor DB's that have been shunned specifically for lack of GraphQL support either. Perhaps I should have said "any" rather than "major." I wholeheartedly agree that lack of Cypher, and I'll add gremlin, has very much hurt adoption of Dgraph. GraphQL is intended to stick many backend systems together for a unified client API, and nothing currently prevents Dgraph plugging into that stack the same way every other DB out there does. A library like Neo4j created to help writing resolvers or a Prisma connection would go a long way to making that very seamless. But to plug directly into the DB from a client... Dgraph doesn't even have a concept of users or permissions. This would probably require a fundamental redesign of the architecture to implement. I don't think it's anywhere near the intended scope of the project. It sounds something like Firebase, which in my experience has great momentum at first, feels super productive, and then dumps on you with the limitations later on. The true power of GraphQL is preserving a unified, consistent, flexible client API while completely decoupling the underlying architecture, not in coupling it tightly to the persistence layer. |
|
I think we entered a loop here. I close this discussion from my side and point to how others reason about it. After all, my triggering comment up above is about “the mistake to have GraphQL slip from the radar” for dgraph. For example, the guys from sanity.io handle the problem with their graph query language (called GROQ) and GraphQL at (seemingly) first priority. They also currently lack GraphQL support. In the presentation below they acknowledge the same technical hurdles you bring up, but do not shy away of bridging to the value of GraphQL as a community in first class support. Maybe the dgraph team can jump on that to re-asses the priority GraphQL. Those guys seemingly build a transpiler as suggested before. |
|
It's interesting to see how neo4j is handling graphql support. In addition, their neo4j-graphql-js library provides a way for grpahql servers to delegate graphql resolver resolution to neo4j while still allowing query flexibility on a field-by-field basis with Cypher directives, defined directly in the schema. Some options for dgraph:
|
|
I'm building this, which will address lots of the GraphQL points for Dgraph. |
|
@MichaelJCompton awesome work, a bit too bad its in #C instead of Go. Any chance you could lock this in a docker container so we can try this launched into docker/kubernetes as a side container? |
|
What is the status of this issue ? Also, would it be relevant to support opencrud for a first version ? |
|
Hey everyone! We're excited to announce that we have a beta release for Dgraph GraphQL. Give it a try and let us know what do you think about it. You can read all about the challenges we faced, our learning's and the future at https://blog.dgraph.io/post/building-native-graphql-database-dgraph/. |
|
@pawanrawal I just read through the docs, and I can't wait to start playing around with this! I was pleasantly surprised to see that interfaces made the cut for the initial version. You mentioned here that:
This could resolve several of the initial limitations that I see for my use case (e.g. aggregations). Will this functionality be exposed through a custom directive? How would this work? Also, are there plans to support facets (and filtering / sorting on facets)? Finally, has any thought gone into Relay Cursor Connections for pagination? |
|
I'll preface this, since it turned into a big wishlist and I know this feature is still really early on: I'm loving this so far and it may have won me back to DGraph for graph databases. It's been so surprisingly hard to marry graph databases and GraphQL APIs, and it's wonderful to see progress being made! So thank you, and this initial release is already looking excellent! My comments below are mainly related to where I would hope the roadmap is going; mainly making sure that pagination is not overlooked. I will add my interest in Relay-style Connections for pagination. You could move forward with the current plain lists, and add entirely new fields with a Like many other developers I think, I initially resisted the 'complexity' of Relay's guidelines, but nowadays I wouldn't start a project without them. Client-side pagination is simply too complicated to implement for anything less at the moment. Everything seems nice with plain lists, until you start thinking about how to do an infinite feed, and add new items to the list with mutations, delete them... things are just far easier when there's a I think if you want to use GraphQL at such a low layer, that kind of expressiveness is a must. I want to at least know if there's a next page to my data, and if at all possible to do cursor-based paging. It won't be possible to provide this kind of API to the frontend without it already being present at the database level. And while we're at it, a I'm very interested in defining fields with arbitrary Oh, one last edit: returning intermediate response types for mutations is also a big deal. Doing that now will free up a lot more flexibility in the future. |
|
As of 20.03.0 Dgraph has support for spec compliant GraphQL. We are committed to further enhancing that support in future releases (watch out for things like subscriptions, custom logic and auth int 20.07.0, we'll also be adding a roadmap for the future) and in showing how to use Dgraph with other parts of the GraphQL ecosystem. This has been one of Dgraph's most popular issues, so thank you to everyone who has added comments over the years. If there are features in our GraphQL support you'd like to see, please add those as individual issues and we'll consider each one. |
I've read #114 and understand why you've chosen not to follow the graphql spec. However, graphql clients like Relay and Apollo provide some very useful features out of the box such as client side caching, optimistic updates, combining queries, etc.
I ended up creating a graphql server to map some basic graphql queries to graphql+-. However, I'm struggling with how to do this efficiently within the graphql server resolve functions without creating a lot of query-specific logic.
Can you please provide an example of the recommended way to interact with graphql clients like Relay and Apollo (either directly or via a graphql server)?
The text was updated successfully, but these errors were encountered: