Implement std.math.{atan[2],tan,exp[2],expm1} for single- and double-precision #6272
Conversation
|
Thanks for your pull request and interest in making D better, @kinke! We are looking forward to reviewing it, and you should be hearing from a maintainer soon.
Please see CONTRIBUTING.md for more information. If you have addressed all reviews or aren't sure how to proceed, don't hesitate to ping us with a simple comment. Bugzilla referencesYour PR doesn't reference any Bugzilla issue. If your PR contains non-trivial changes, please reference a Bugzilla issue or create a manual changelog. Testing this PR locallyIf you don't have a local development environment setup, you can use Digger to test this PR: dub fetch digger
dub run digger -- build "master + phobos#6272" |
|
There are unittest failures due to I'll need an okay to proceed though, I don't want to waste any more time on this if this doesn't have a chance to be merged (backwards compatibility concerns). |
859cad1
to
cedc96c
Compare
|
No unittest failures anymore [well, test coverage is minimal at the moment]. x86_64 timings are quite interesting. Linux, Intel i5-3550 @4GHz, dmd master with import std.datetime.stopwatch;
import std.stdio;
version (C)
{
pragma(msg, "Using core.stdc.tgmath");
import math = core.stdc.tgmath;
}
else
{
pragma(msg, "Using std.math");
import math = std.math;
}
T atan(T)() { return math.atan(cast(T) 0.43685); }
T atan2(T)() { return math.atan2(cast(T) 0.43685, cast(T) 0.06912); }
T tan(T)() { return math.tan(cast(T) 0.43685); }
T exp(T)() { return math.exp(cast(T) 0.43685); }
T exp2(T)() { return math.exp2(cast(T) 0.43685); }
T expm1(T)() { return math.expm1(cast(T) 0.43685); }
version (C) {} else
T poly(T)()
{
static immutable T[6] coeffs = [ 0.1, 0.2, 0.3, 0.4, 0.5, 0.6 ];
return math.poly(cast(T) 0.43685, coeffs);
}
void bench(alias Func, T...)()
{
enum numRounds = 5; // best-of
enum N = 10_000_000;
writeln(".: ", Func.stringof);
Duration[T.length][numRounds] durations;
foreach (i; 0 .. numRounds)
foreach (j, F; T)
durations[i][j] = benchmark!(Func!F)(N)[0];
foreach (j, F; T)
{
Duration bestOf = durations[0][j];
foreach (i; 1 .. numRounds)
{
if (durations[i][j] < bestOf)
bestOf = durations[i][j];
}
writeln(F.stringof, ":\t", bestOf);
}
}
void main()
{
bench!(atan, real, double, float);
bench!(atan2, real, double, float);
bench!(tan, real, double, float);
bench!(exp, real, double, float);
bench!(exp2, real, double, float);
bench!(expm1, real, double);
version (C) {} else
bench!(poly, real, double, float);
}=> The |
Is that unexpected, though? One would expect the "software" implementations to do worse. |
|
Well I for one didn't expect such inconsistent results, or a ~4x slow-down of software-double-tan vs. software-float-tan etc. |
|
Here are the corresponding |
|
Rough runtimes comparison for the single/double precision overloads: |
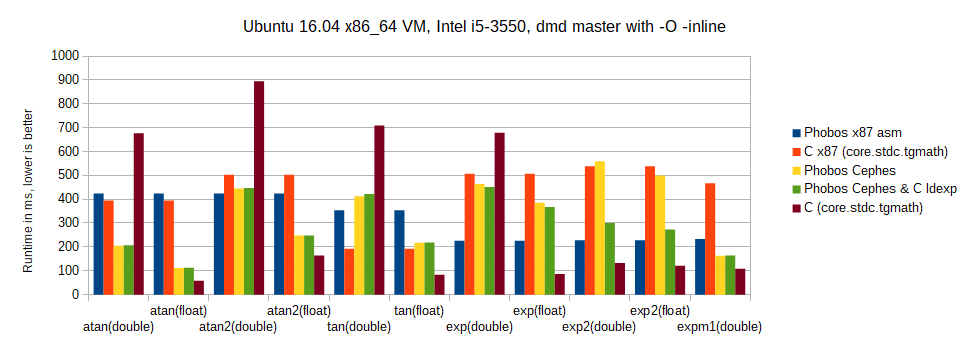
|
Regarding the project tester failure: that's because the flex algorithm is quite sensitive to the floating point behavior and the tests use a special https://github.com/libmir/mir-random/blob/master/source/mir/random/flex/internal/area.d |
... which (only) for DMD and x86_64 is defined as exact equality (== operator). The failing test there seems to depend on |
|
Statically unrolled |
|
How do the timings look on LDC? |
|
I'm afraid I don't have any LDC timings. This patch cannot be simply cherry-picked due to existing mods in the touched parts; the main problem though is that the timings wouldn't be easily comparable, as e.g. the currently real-only |
|
Experimentally using |
|
[Chart and benchmark code updated.] |
|
Chart updated once more after getting rid of a few [Note that |
|
So on my machine and using the purely arbitrary input data above:
|
|
I ported this to LDC (with LLVM 6.0.0 and using C ldexp), and the results are way better than expected: overall speed-up factor of >3 for the new double/float versions compared to the old ones, only beaten by the C runtime in 2 cases ( |
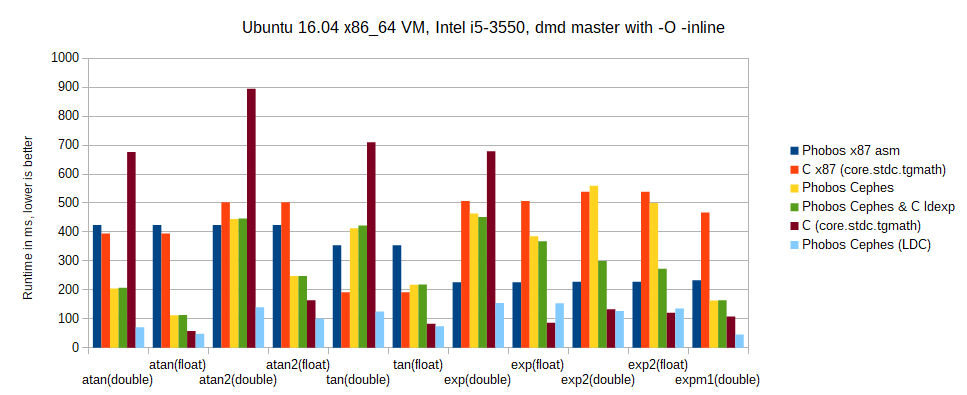
da5e35f
to
b101b0d
Compare
|
Time to squash and merge? |
|
#Ah nice, I forgot to check whether it got green now with new mir-random. Edit: Oh, no project tester in CI anymore?
Do you really prefer a single 1.7k lines patch? |
|
When you put it that way, perhaps not (EDIT: I mean the squash). |
|
std/math.d is getting way too large. The next PR should split this into a package. |
|
@WalterBright indeed, we touched the subject earlier here #6272 (comment) |
And make the x87 `real` version CTFE-able.
And make the x87 `real` version CTFE-able.
And make the x87 `real` version CTFE-able.
And make the x87 `real` version CTFE-able. I couldn't find the single-precision version in Cephes.
Add a statically unrolled version for 1..10 coefficients. Results on Linux x86_64 and with an Intel i5-3550 for: static immutable T[6] coeffs = [ 0.1, 0.2, 0.3, 0.4, 0.5, 0.6 ]; std.math.poly(cast(T) 0.43685, coeffs); => real: ~1.2x faster => double: ~3.2x faster => float: ~3.0x faster
Prefer an arithmetic multiply by the according power-of-two constant, as that's much faster. E.g., this makes tan(double) run 2.05x faster on an Intel i5-3550.
I.e., use poly() as for the other precisions (unlike the C source). With enabled compiler optimizations, it should be inlined anyway.
|
Rebased... |
|
Let's see how this goes… At this point, I believe due diligence has been done, even though more performance comparisons are always nice to have (I still didn't get around to writing that microbenchmarking thing…). |
|
@kinke We got the surprising bug report that |
|
I fixed that for LDC, as we do test it, but forgot to upstream it. If someone gets to it before I do, see ldc-developers/ldc@95af69e (and add a test here). IIRC, the problem is that the statically unrolled |
And make the x87
realversion CTFE-able.Based on Cephes like the existing quadruple and x87 implementations,
https://github.com/jeremybarnes/cephes/blob/master/cmath/atan.c &
https://github.com/jeremybarnes/cephes/blob/master/single/atanf.c