Import machine-learning detected labels (dog, llama etc) from Apple Photos #16
Comments
|
I filed an issue with |
|
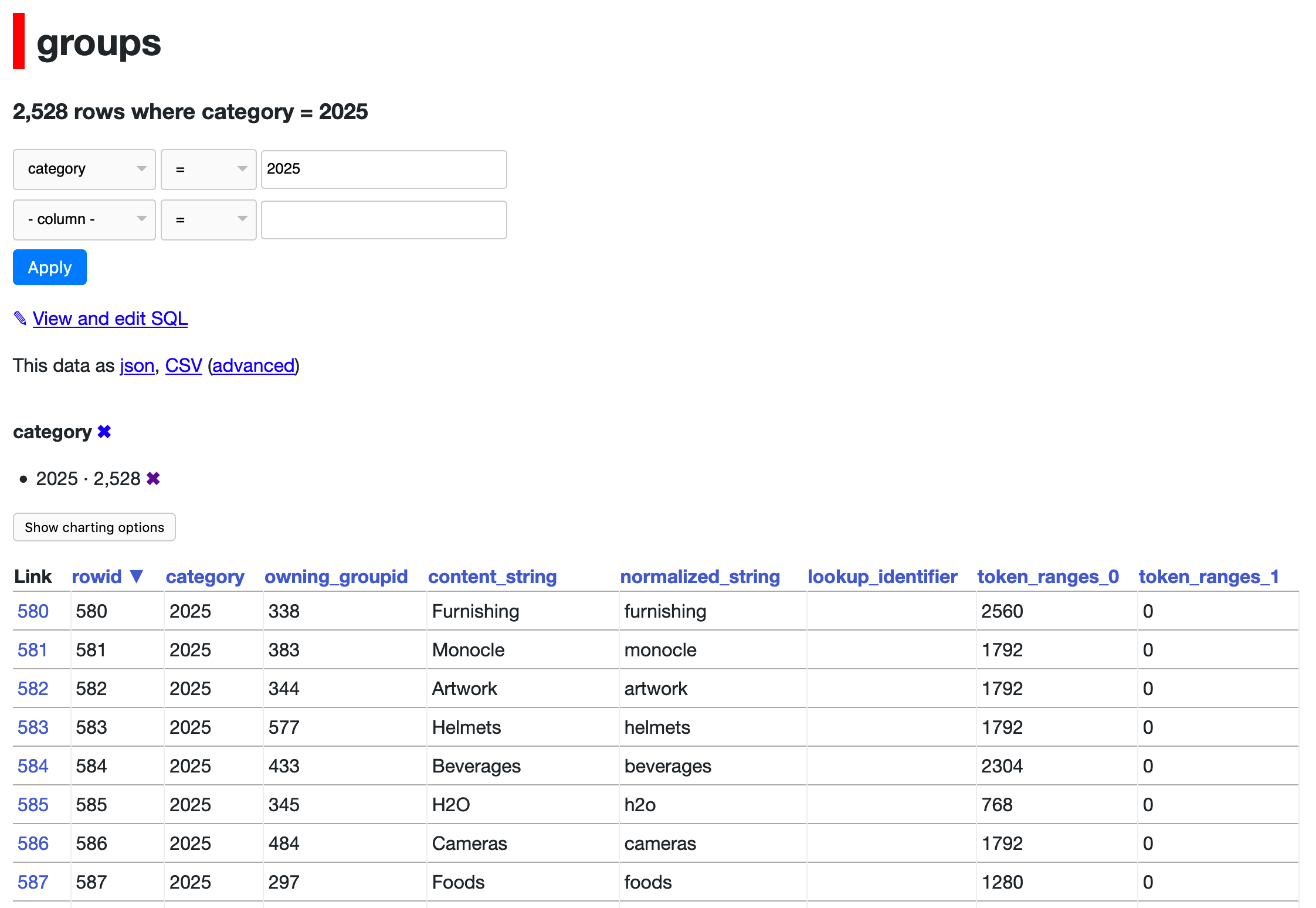
In RhetTbull/osxphotos#121 (comment) Rhet Turnbull spotted a table called I love the look of those confidence scores, but what do the numbers mean? |
|
I figured there must be a separate database that Photos uses to store the text of the identified labels. I used "Open Files and Ports" in Activity Monitor against the Photos app to try and spot candidates... and found
Here's the schema of that file: |

|
Running datasette against it directly doesn't work: Instead, I created a new SQLite database with a copy of some of the key tables, like this: |
|
I'm pretty sure this is what I'm after. The
Then there's a
And an
One major challenge: these UUIDs are split into two integer numbers,
I need to figure out how to match up these two different UUID representations. I asked on Twitter if anyone has any ideas: https://twitter.com/simonw/status/1257500689019703296 |



|
Here's how to convert two integers unto a UUID using Java. Not sure if it's the solution I need though (or how to do the same thing in Python): https://repl.it/repls/EuphoricSomberClasslibrary
import java.util.UUID;
class Main {
public static void main(String[] args) {
java.util.UUID uuid = new java.util.UUID(
2544182952487526660L,
-3640314103732024685L
);
System.out.println(
uuid
);
}
} |

|
I'm traveling w/o access to my Mac so can't help with any code right now. I suspected ZSCENEIDENTIFIER was a foreign key into one of these psi.sqlite tables. But looks like you're on to something connecting groups to assets. As for the UUID, I think there's two ints because each is 64-bits but UUIDs are 128-bits. Thus they need to be combined to get the 128 bit UUID. You might be able to use Apple's NSUUID, for example, by wrapping with pyObjC. Here's one example of using this in PyObjC's test suite. Interesting it's stored this way instead of a UUIDString as in Photos.sqlite. Perhaps it for faster indexing. |
|
This function seems to convert them into UUIDs that match my photos: def to_uuid(uuid_0, uuid_1):
b = uuid_0.to_bytes(8, 'little', signed=True) + uuid_1.to_bytes(8, 'little', signed=True)
return str(uuid.UUID(bytes=b)).upper() |
|
Things were not matching up for me correctly:
I think that's because my import script didn't correctly import the existing |

|
Trying this import mechanism instead: |
|
Even that didn't work - it didn't copy across the rowid values. I'm pretty sure that's what's wrong here: |
|
Yes! Turning those import sqlite3
import sqlite_utils
conn = sqlite3.connect(
"/Users/simon/Pictures/Photos Library.photoslibrary/database/search/psi.sqlite"
)
def all_rows(table):
result = conn.execute("select rowid as id, * from {}".format(table))
cols = [c[0] for c in result.description]
for row in result.fetchall():
yield dict(zip(cols, row))
if __name__ == "__main__":
db = sqlite_utils.Database("psi_copy.db")
for table in ("assets", "collections", "ga", "gc", "groups"):
db[table].upsert_all(all_rows(table), pk="id", alter=True)Then I ran this query: select
json_object('img_src', 'https://photos.simonwillison.net/i/' || photos.sha256 || '.' || photos.ext || '?w=400') as photo,
group_concat(strip_null_chars(groups.content_string), ' ') as words, assets.uuid_0, assets.uuid_1, to_uuid(assets.uuid_0, assets.uuid_1) as uuid
from assets join ga on assets.id = ga.assetid
join groups on ga.groupid = groups.id
join photos on photos.uuid = to_uuid(assets.uuid_0, assets.uuid_1)
where groups.category = 2024
group by assets.id
order by random() limit 10And got these results! |
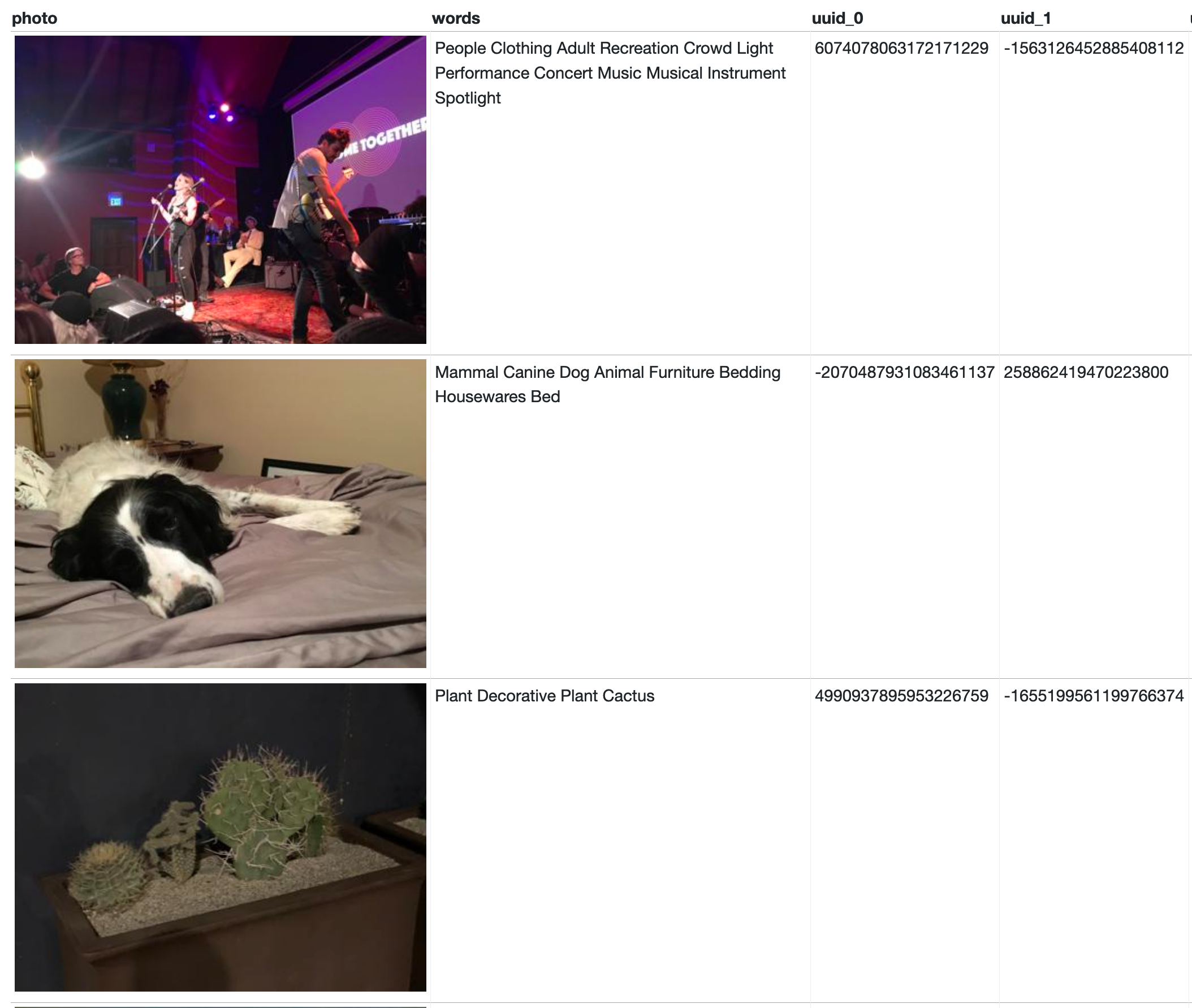
|
It looks like |
Follow-on from #1. Apple Photos runs some very sophisticated machine learning on-device to figure out if photos are of dogs, llamas and so on. I really want to extract those labels out into my own database.
The text was updated successfully, but these errors were encountered: