[Proposal] Introduce "var?" for nullable type inference #3591
Comments
|
This will no longer produce a warning in C# 9.0 as the language team has decided to always treat |
|
If the selected branch is "master" then it should be using the C# 9.0 bits. I do not see the warnings there, but I do see the warning if I change the branch back to "Default".
The flow analysis of NRTs is pretty good at determining when it's safe to dereference the variable and it's already a core aspect of the experience. The behavior of the variable will remain the same. If the method returns a non-nullable, the compiler will consider the variable to not be null and will not warn on dereferencing. If you assign string SomeMethod() => "";
var s = SomeMethod();
var length = s.Length; // does not warn
s = null; // does not warn
length = s.Length; // warns
if (s != null) {
length = s.Length; // does not warn
}The nullability annotations aren't that important on locals, the compiler will infer from usage. It's at the boundary where the annotations are much more important because the compiler can't know the expected state of the value crossing that boundary.
That is what the language team thought, too. But the experience and feedback from that decision is that the behavior is suboptimal, especially around existing code, so the team decided to reverse that decision. The warning on assignment isn't particularly helpful if that variable isn't dereferenced again without checking for nullability. Anyway, here's the meeting notes from when the language team already considered the addition of https://github.com/dotnet/csharplang/blob/master/meetings/2019/LDM-2019-12-18.md#var |
|
@HaloFour the behavior you link to is enabled for C# 8 as well, provided the compiler version is new enough. |
Unlike documented by the nullable-reference-types proposal, these variables do not infer their nullability based on their initializer. Instead, they are always declared as nullable, and the initializer's nullability only matters for the flow-state. See also: dotnet/csharplang#3591 (comment)
|
I'd rather opt into being pedantic about forcing you to express what you wanted by using Thanks a lot for the link though. |
You can always write an analyzer yourself to find and report thsi if you want that extra restriction :)
We looked into this, and it was effectively awful. So much code that was null safe and was written in idiomatic C# was then flagged as needing additional work. This violates my own goal for the feature which is that good, existing, coding practices should not feel like something that is now punishing you. |
Not every programmer has the skill or time to write custom analyzers to mitigate shortcomings of the native compiler. ;)
I understand your point and see where you're coming from. But quite honestly - with this behavior for If If it bothers me that I must write And maybe, after killing |
|
The goal of NRTs is to avoid NREs, not nulls. A null assigned to a local that is never dereferenced is innocuous. You can argue that this makes annotating locals with their nullability is pointless if flow analysis can make this determination, and I agree with you. The annotation makes sense at the boundary where flow analysis can't track what happens. But I disagree that this decision somehow weakens NRTs or makes them irrelevant. NRTs were never intended to be a change to the type system, they're meant to be guardrails, and they need to be a very pragmatic solution so that can be practically applied to tons and tons of existing code. |
No, that is not how the design works. You must, at minimum, turn on the flow analysis with |
Question 1: What is the point of having a wrong warning "Dereference of a possibly null reference." in line 2 instead of a correct warning "Expression is always false." in line 1 with In other words: if NRT are meant to be "guardrails", then why are those rails installed in a way that it is easy to make them ineffective (by adding a useless null-check), and if we deemed them sensible nevertheless, why would I have to explicitly ask for the guardrails to be installed? |
|
The guardrails exist to steer you away from NREs. That may warn spuriously, but it won't NRE. More interesting would be non-pathological cases where the compiler doesn't warn and can result in an NRE. |
|
Consider instead a public API: It's annotated as not accepting null, but of course someone could be calling you from a nullable disabled context or they could put a |
I disagree. The cost to doing something like this is extremely small. So either this is a significant issue for you, in which case writing hte analyzer is a cheap and easy way to solve the problem. Or it isn't an significant issue, in which case it doesn't really matter if it solved :)
This was never the point. The point was to diminish the quantity of null reference exceptions, and to introduce a system that had a low amount of false positives and false negatives.
It would be fine to introduce an analyzer to give such a warning. No one is stopping that. |
If that is so, this is the root cause of my problems with that behavior, and apparently some others. Because everything that has been named, said, documented or marketed about this feature promises exactly what you say "was never the point". Just read the introduction of the official documentation:
What's even worse, the documentation continues to compare it to the "earlier" behavior:
Comparing this to the current behavior:
Statements about when a reference "can be null":
Statement about when a refereces "is assumed to be not null" (in fact, the feature was marketed to get rid of "assume" and introduce "declare", which is stronger):
I hope you can see what a gigantic let down this feature appears to have become, compared to what was promised. I want you to take a step back and not look at why a decision was made, but look at the bigger picture of what the feature now brings to the table in comparison of what is said it brings to the table. Optimizing the behavior under the premise of "show as few warnings as possible" and "signal 'everything is fine, you don't have to change a thing' as long as possible" is creating a meaningless tool. NRT/NNRT promised and is marketed to allow me to get rid of vague assumptions and replace those with rigid declarations. But everything that has been done ever since were softening those "declarations" back to "assumptions". These new assumptions may be smarter than before, which is a fine thing in itself, but why even introduce "better algorithms" as a new feature, not as improvement of the already existing feature. I'm genuinely disappointed. It was announced as "Declare if a reference can be |
|
In short:
|
|
I can really not stress enough how much of a logical break in compiler behavior this is. Consider this code: In the first line, the compiler infers the type of Now watch what happens when I declare the type of As you can see, the compiler will treat my explicit type declaration as given, and therefore say "line 2 is wrong". Now look at what the compiler does with my declared non-nullability: If in my example from above the compiler behaved in the same way like NRTs are implemented, then this would be the result: The idea of some analysis checking "What you do with that variable only makes sense if the variable is treated differently from what was declared", which then does not lead to the conclusion "you should not do this with that variable" but instead to "I assume a different type than what is stated at the declaration"... that's insane! |
|
You're comparing inference of type to inference of nullability, which aren't the same. NRTs aren't a part of the type system, they are only a linter. |
|
I am aware that NNRTs vs their respective NRTs are not two different types, like VTs vs belonging NVTs are. I know they are realized with annotations in order to maintain backwards compatibility, and thus make the behavior a question of individual annotation analysis opposed to existing type logic. But that doesn't mean that to-be-introduced analysis may not strive to produce a behavior for NNRTs that is consistent with the compiler behavior for VTs. The decision to treat a null-check as more declarative of a variable's nullability than the actual declaration is just that - a decision. It's not a necessity introduced by the way nullability had to be implemented under the hood. It may be clear to you why nullability for reference types is not implemented the same way like for value types, but there is no reason why it may not be treated the same way. The written code provides all necessary information to accurately infer nullability and then treat the variable identically to how it is done for value types. The decision to treat |
|
The decisions made around NRTs were made giving priority to making them easy to adopt with minimal code changes. Generating a ton of warnings around common existing code patterns that are not at risk for producing NREs is not a good experience. The patterns for dealing with nullability in reference types have been established over 18 years, whereas nullability in value types wasn't at all possible until NVTs were added to the runtime and language. NRTs are a giant pile of compromises optimized around pragmatism and a low barrier to entry to adoption and ecosystem penetration. I view NRTs like I do generics in Java, which were designed with similar considerations to the existing language and ecosystem. Both can be pretty trivially intentionally defeated by the developer, but for non-pathological code they effectively guard against incorrect usage of the values the vast majority of the time. |
|
Thanos travelled the whole universe to collect all Inifinity stones. He created the most powerful tool one can imagine. And then he used it to cure the symptoms, not the cause. They created a tool that had the power to abolish the cause (reference type variables might be null), and they chose to cure the symptom (NPEs). The result is giant pile, but that pile is a mess, with behavior that is unexpected, unnecessary, and inconsistent with everything you know about nullability and C#. There is no reason why There is no reason why There is no reason why the fourth line should issue a helpful warning, but not the sixth. Feel free to implement this bunch of mildly-useful helpers, but name them "better reference type nullability annotations" which "hint" something and don't waste/abuse the What is implemented and planned is certainly not introducing anything close to the concept of "non-nullable-reference-types" which "enforce" something. If it must be so convenient and frictionless to adopt the feature, then why even give users a choice? If the ruleset and logic has to be softened so much that basically 99% of the code stays warning-free when enabled, then why make it an opt-in feature at all? |
The cause of an NRE is dereferencing
Everything you knew about nullability was that every reference variable could be
Your pathological code is giving the compiler reason to doubt its flow analysis. It assumes you know better. I'd suggest not writing pathological code. You know how easy it is to get a
There absolutely is. Issuing a new warning is a breaking change. I'm sorry that you don't like NRTs. I don't like everything about them either. But they are the culmination of more than six years of public discourse on the subject and comparison of a very wide range of options. |
We've found literally dozens of cases in our own product where unintentional null refs could occur. We've been able to find and fix them because of nrt. Furthermore, the design has allowed us to gradually adopt net (generally on a per file basis, but sometimes when more granularly than that). That adoption had been reasonably painless due to the amount of false negatives and positives being quite low. You say this is a meaningless tool. However, based on the results alone in our codebase I would say that is absolutely not the case. |
|
Let me be clear. What has been done was good and fruitful and is certainly a good thing. I do not at all question that. But I don't see why this is treated as the whole solution for NRT. As I said, if the design is chosen as is, under the premise of avoiding to show any warning that is not most likely valid and definetely show a warning where there is a mistake, then this analysis should be its own separate opt-in feature or not being opt-in at all (depends on the C# definition of "breaking" change; to me a compile- or runtime error is a breaking change, but not a design time warning). But the other opt-in feature that actually introduces what is called "non-nullable reference types" and the syntax of |
It has not been treated as the whole solution for NRT. We've already done more work in the NRT space, and i expect that we will continue to do so for many more versions of the language. |
Your premise is incorrect. There has never been a design that would "definitely show a warning where tehre is a mistake". The designs have all been around a balance of getting lots of true positives/negatives and minimizing false positives/negatives. There has never been a design of where a warning is always shown when there is a mistake. |
This is fine to have as a personal opinion on your part. However, you need to recognize that it is not shared by other people (including myself). The goal is to take pragmatic and not dogmatic approaches here to maximize the utility of this for the vast majority of the user base. Strict adherence to rules that would just provide more pain to users, while providing no additional benefit in terms of correctness is seen as a net negative. Look, i totally get your views and why you want it to be this way :) Indeed, your views on this are how we initially implemented this feature, thinking that would be the right way to go. However, immediately we could see across the board how bad an experience this was causing for users. Simply ignoring that and sticking with the position of "that should be what it says" would have done nothing good for this feature. It would have made it much harder for people to adopt, and it wouldn't have produced any less null-refs for hte people that did adopt it. It was, objectively, a strictly worse outcome for the entire ecosystem. |
And htere's the rub. That's your assessment of the pros/cons. But they apply to you. We have to holistically look at the entire ecosystem out there. Thousands of companies, millions of devs, and tons of sources of feedback indicating a wide variety of views on this topic. Your pros/cons tell you that you would prefer the more strict view of things. And trust me, you're not alone. However, you're not a majority or plurality. In language design, this is the norm. Every decision we make always has some group left out or feeling like their own personal weighting has gone negative with our decision. That's simply part of hte process, and can feel sucky when you're in that group. Trust me, i'm on the LDM and i've been in that group likely at least once per language revision. However, i recognize that just because the decision made then might not be the best decision for my personal needs, that it's still likely the best one for the ecosystem as a whole. |
But it has the disadvantage of requiring more usings, plus if the type is more complex, e. g. a return type from a complex LINQ statement, it gets really wordy. I really hope at some point in the future "var" will be "dumb" again, i. e. simply take the right hand side, without any assumptions or pseudo-clever guesswork. Return type of my method is |
Can you link me to such an analyzer, i. e. one where declaring |
Chris, obviously I was also disappointed about However in terms of the future I wonder if a more realistic and in some ways more useful improvement might be a new non-nullable var with a new keyword (say |
|
Here's another way use of What if the IDE used different syntax highlighting for the That way any unwanted nullable assignments would change the colour of the variable's Something changing colour is not as good as a warning but this would not involve language change and seems feasible. Edit: Or, dare I suggest it, instead of colour change maybe the IDE could suffix |
|
Here's another option for improving Why not make the Then the IDE could indicate when the This would remove the completely un-necessary confusion of "flow engine nullability" differing from "static nullability" in the case of (Optionally, we could also consider e.g. |
|
It's important to note that with NRTs that it's not the type of the variable that is nullable or not, it's the state of the variable at that point in the flow. A If you want to make the language stricter and warn/error in cases that would not otherwise throw an NRE, that sounds like a good place to use an analyzer. As for visualization of the nullability flow, I'd suggest that's possible, at least in Visual Studio where I believe you can still write extensions that affect the view. I imagine one would have to be written for every IDE. I can certainly see value in better visualizations here, although that's not really a C#/Roslyn concern. |
@HaloFour Could you kindly point me to a resource where I can get such an analyzer? As I said, I have never done anything with compilers/syntax trees/nodes etc., and after reading about it for an hour, I figured getting into this stuff would take way more time than I can spend right now to learn how to code analyzers let alone the one that is needed to introduce "true NRTs". Yet I'd really like to have those strict checks rather sooner than later. Has anybody ever done this? When I try to Google for it, all I can find is people either proposing Roslyn should do it, or people complaining that Roslyn's doing what it does now and not what was promised. |
I'm sorry, we did not promise this. If there are docs saying such a promise exists, we will need to change them as they are not accurate. |
The idea is: if there is enough interest by someone, they could write this themselves. It's a non-goal of the NRT initiative to address every request and need of all developers. Where there are gaps, analyzers can be written by those interested in filling them.
Not that i know of. It seems like something that isn't really that compelling at the end of the day for most people. |
|
For interest of those on this thread, JetBrains state here they are in the near future planning to support a bulk quick fix which removes unnecessary I do think a useful next step for NRT could be the introduction of |
Yes, yes you did. Read my comment from earlier. Unfortunately, it's impossible to highlight text with font or background-color, so I had to edit a screenshot.
So I think "it wasn't supposed to be that" may be true because the developers implemented something utterly different than what the announcement said. The announcement said "we're going to build a seven story plaza" and the developers said "We aimed for a small bungalow, it was never supposed to be a plaza".
These statements alone in conjunction clearly rule out that To be clear, what was done is good, but the only difference is that the warning that were already there are now hopefully more accurate. This is miles off from phrases like "enforces" or "can never". |

|
As noted, the behavior with I think you're reading the behavior that you want out of that document. The compiler enforcing the rules does not mean that this code is no longer legal. It's long been a goal of this feature to be as non-disruptive to the billions of existing lines of perfectly fine C# code as possible as trying to make it stricter would guarantee that it would not be adopted. |
|
@LWChris Can you clarify what in that document makes you think we promised this? |
No, it describes exactly how reference types used to be treated, not how they are currently treated. When nullable is enabled, and you've declared that a variable should not be null, you get a warning if you attempt to assign null to it. When you attempt to dereference something that we know could be null, you get a warning that it could be null. Neither of these behaviors appear when nullable is turned off, and that's what that green paragraph describes.
Yes, and that code is indeed not valid. I don't really know what the point of this sentence was. I think a key point here is that you are inferring a different meaning for |
I also think this is a key point. I've accepted So I no longer think * Another way to say the same thing is that |
|
@333fred I am not talking about the This whole thread in a nutshell: It was my initial understanding that
I argued that 1, 2, and 3 are inconsistent with the behavior for value types, and that it'd be much less confusing if the compiler tried to match the value type behavior for reference types at compile time. People keep explaining I knew about a). I understand b). But I'm one of the not-actually-so-few persons who don't mind if our projects don't compile if the benefit is having compile-time safety against NREs. Therefore, I made an argument that the current implementation of I don't see c). How could anyone believe that the announcement and documentation matches the current behavior? The statements I quoted earlier do very clearly state that
The current compiler however compiles
"enforcing" - You keep using that word. I don't think it means what you think it means. 😅
[YES] The compiler enforces that a class implementing an interface is either abstract or implements all interface members with suitable accessible members. |
I dunno, when the police are "enforcing" speeding rules more often than not I end up with a warning. 😁 |
|
@HaloFour To me, that means they are apparently not enforcing them 😁 |
Or you can make those warnings into errors. |
The compiler enforces this by telling you about the issue. You can choose to have that be blocking or not. But we leave that choice to you, we do not want to enforce that on an astronomically large ecosystem with thousands and thousands of groups and projects all with varying needs in terms of how they can adopt this concept. |
|

I think you're confusing "blocking" with "enforcing". Our goal of NRT was to be non-blocking for users. Any reasonable sized project will take a fair amount of effort to move to NRT. In roslyn, we've been continuing to NRTify our whole codebase, and it's been taking months and months and months. It's imperative that people be able to make this sort of progress in an enforced, but non-blocking, fashion. That's what we provided and it was very intentional and necessary to be viable. OUr defaults seem to not be what you want. However, you can change the defaults here to better suit you if you want. |
|
I am satisfied with this result, there are some quirks and it still sucks that However I really honestly do recommend to change the documentation to not use the phrase "enforce a rule". I'm convinced the majority of all readers will completey misunderstand that. Ask 100 C# programmers who aren't involved in compiler development:
I bet at least 90 will answer "A". 🙂 |
|
I have to agree with @LWChris completely on this one. I didn't have a particularly strong opinion on the introduction of non-nullable types, but if you're going to do it, why make something as fundamental as the |
NRT is opt-in specifically because it involves a migration for any existing codebase. The goal is to eventually get to 100% adoption where NRT is the default behavior, but that will take time. Given the vast impact NRTs has on existing codebases compromises had to be made so that it would be easier to adopt. When someone is evaluating opting-into NRTs for their codebase if they see thousands of warnings they will be less likely to consider the effort necessary to carry out the migration, so it's desirable to ensure that those warnings only appear in cases where NREs are more likely to occur. The feedback from the first release is that inferring the nullability based on the RHS resulted in way too many extraneous warnings. While warning on assignment may help you identify where a The perfect is the enemy of the good.
Flow analysis only really works well within the body of a method. It becomes infinitely more complicated across the boundaries between methods. Sure, the compiler could have inferred the metadata on the boundary based on use, but at that point the nullability becomes a part of the contract of that method, and the team is pretty consistent on the belief that said contract should be explicitly defined. As for locals, I agree, having to explicitly notate which are nullable has a lot less value and could have been driven entirely by flow analysis. |
|
I hope one day we get a v2 of non-nullable reference types with with real non-nullable types at runtime level. That would solve a host of confusions and complexities that arise because flow-analysis nullability is different from underlying nullability. It would also remove the need for run-time null checks of non-nullables and mean |
|
@HaloFour Of course turning on nullable reference types for existing codebases is likely to create a bunch of warnings. But it's opt-in. I guess I misunderstood the purpose of this, because I assumed it would be for new code. Why not turn non-nullables on for new code, and use flow analysis on existing code? |
The goal is to make it work across all codebases and to make it relatively easy to adopt for maintainers of existing projects. Avoiding spurious warnings is intentional, especially if they arise in common cases. |
Problem
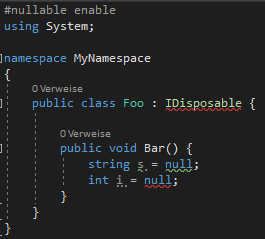
Consider this code:
With
#nullable enable, the lineref1 = nullcauses a warning, because the type ofref1was inferred fromGetOrCreatewhose return type isn't nullable. The lineval1 = nullwould obviously not even compile.In order to have all variables nullable, I'd either have to change the return type of
GetOrCreateandCountto nullable types (which is bad because both will never returnnull, so why declare otherwise), or I have to use explicit type, which can range fromint? val1 = p.Count;to
TheTypeThatRequiresAnImport<WithGenerics, WhichRequire, EvenMoreImports>? ref1 = p.GetOrCreate(1);Proposal
If
var ref1can be resolved toTheType ref1, thenvar? ref1could be resolved toTheType? ref1.Considerations
This syntax can theoretically be allowed for reference types and value types. For both cases,
var?will ensure that the declared variable is nullable, regardless of the right-hand side's nullablity (for value types) respectively nullable annotation (for reference types).For value types, the behavior will be:
which is equivalent to
For reference types, the question mark behaves the same like the one in
TheType? obj:The text was updated successfully, but these errors were encountered: