- Python Version: 3.5.1
- Use the config.ini (see ConfigParser)
- For a good Python style guide see Google Python Style Guide
- cython: C-Extensions for Python
- numpy: Optimized and powerful N-dimensional array object
- scipy: Fundamental library for scientific computing
- scikit-image: Collection of algorithms for image processing
- sklearn: Machine Learning in Python
- sklearn.svm: Support vector machines (SVMs)
- sklearn.neural_network.multilayer_perceptron: Generic multi layer perceptron (Github pull request recently merged), see also here
- svg.path: SVG path objects and parser
- bob.learn.mlp: Bob's Multi-layer Perceptron (MLP).
- dtwextension: Dynamic time warping (C implementation)
See here for Windows binaries.
Info: Since the multilayer_perceptron classes from scikit-learn are not yet included in the latest release (0.17.1), they have been copied. As soon as they are released, the code in the folder mlp can be removed.
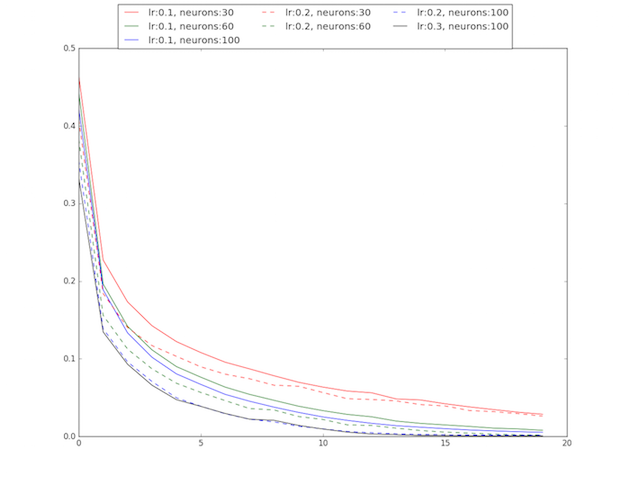
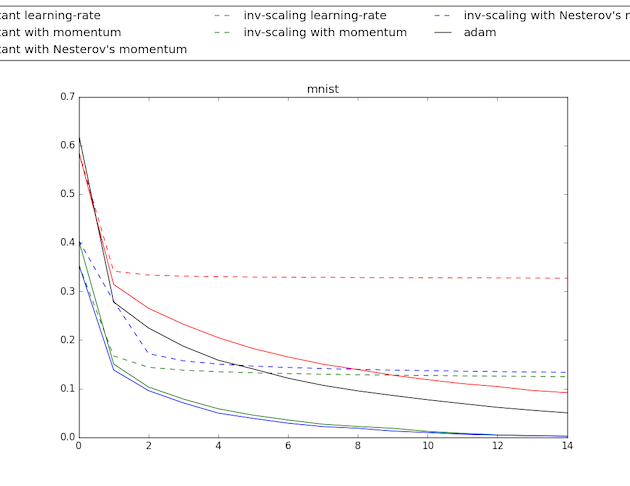
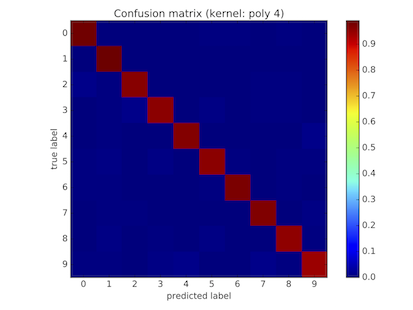
Scores for different kernels and confusion matrices
| Kernel | Training score | Training cross validation | Test score | Test cross validation |
|---|---|---|---|---|
| Linear | 1 | 0.910 | 0.908 | 0.913 |
| Poly1 | 1 | 0.910 | 0.908 | 0.958 |
| Poly4 | 1 | 0.955 | 0.966 | 0.946 |
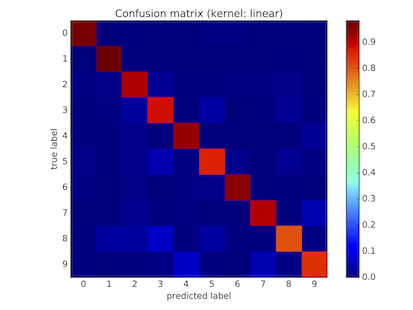
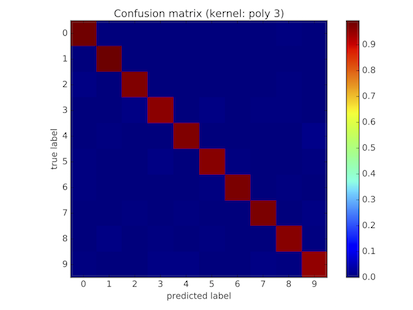
The main project of the course is about implementing a solution for key word search in historical documents. Most of the methology is inspired by the work of Rath et al. 1
Before extracting features, each word is pre-processed:
- Remove clutter (small objects)
- Find a word mask
- Normalize the pixel intensities
- Position all the words in a frame with uniform height (centering and scaling)
During this procedure the main assumption is, that the central part of the handwriting (i.e. small letters like a, e, i, ...) will be the predominant peak on the vertical projection of the pixels.
Sliding window approach. Local descriptor includes:
- Black-white transitions
- Foreground fractions
- Relative positions (top, bottom, centroid, center of mass)
- Gray-scale moments
Once the features are computed for each word, dynamic time warping (DTW) is used to compute the string edit distance between a given pair of words.
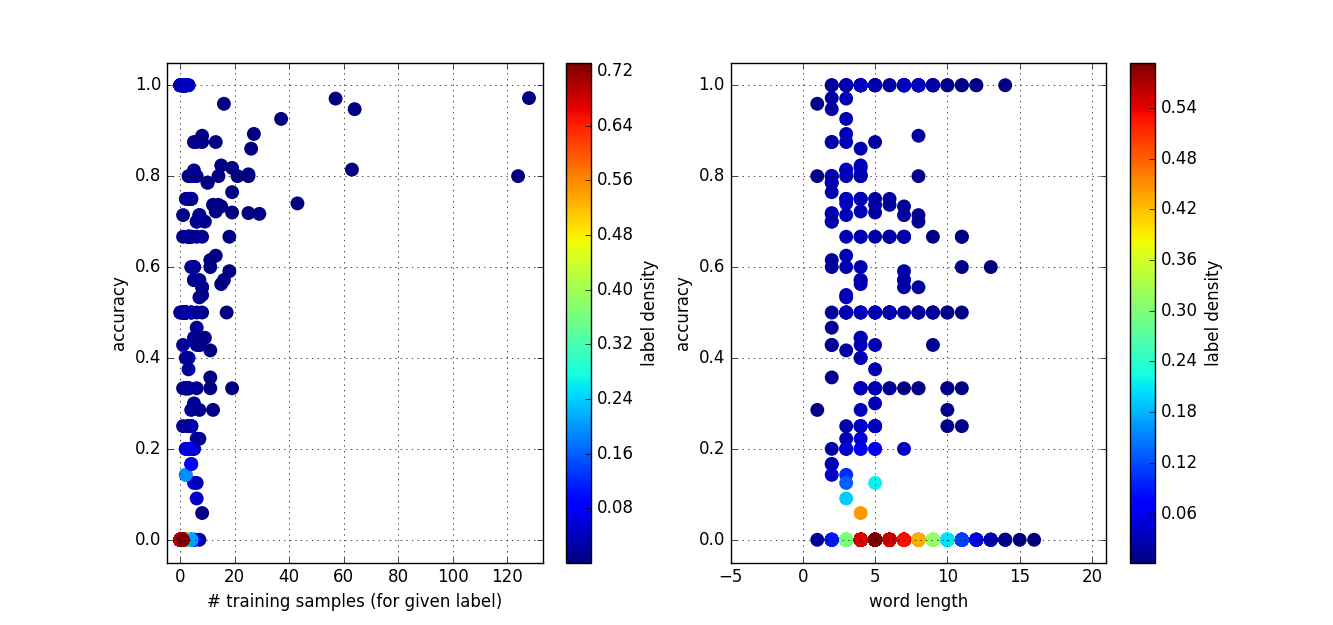
For word classification a KNN algorithm is used.
| Dataset | Overall accuracy | Accuracy with training samples | CPU time |
|---|---|---|---|
| Training | 0.48 | 0.48 | 7.25 min |
| Validation | 0.36 | 0.57 | 4.15 min |
| Everything | 0.44 | 0.50 | 11.40 min |
1: Tony M. Rath and R. Manmatha. 2006. Word spotting for historical documents. IJDAR 9, 2–4 (August 2006), 139–152. DOI: http://dx.doi.org/10.1007/s10032-006-0027-8