plataforma Platzi
📁Un módulo es cualquier archivo de Python. Generalmente, contiene código que puedes reutilizar.
🗄 Un paquete es un conjunto de módulos. Siempre posee el archivo __init__.py.
Una ejemplo de organizar los archivos de 🐍Python es de la siguiente manera.

un paquete es una carpeta que contiene módulos. siempre posee el archivo .init.py
Si están usando WSL o una terminal Unix, pueden instalar con sudo apt-get install tree para ver un árbol de sus carpetas.
Luego puedo ingresar a la carpeta de mi proyecto y ejecutar el comando tree.
Se vería algo así:

Yo pongo tree -I venv para ignorar la carpeta venv que esta llena de cosas. Si no lo pongo verás todos los directorios de tu proyecto.

Mini resumen:
Estático →→ Detectan los errores en tiempo de compilación. No se ejecuta hasta corregir. Por ej, Java
Dinámico →→ Detectan el error en tiempo de ejecución. Nos dice el error cuando llega a la línea del código. Por ej, Python
Strong →→ Más severidad con los tipos de datos. Sumar un número + una letra arrojará error.
Weak →→ Menos severidad con los tipos de datos. Si quiero sumar número y letra, las concatenaría como strings. Castea tipos de datos automáticamente. Por ej, PHP
Documentación oficial del tipado estático en Python
El tipado estático nos hará evitar errores de tipado antes de que el programa se ejecute.
a: int = 5
print(a) # 5
b: str = 'Hola'
print(b) # Hola
c: bool = True
print(c) # TrueEsta sintaxís está disponible desde la versión 3.6 de Python.
def suma(a: int, b: int) -> int:
return a + b
print(suma(1,2)) # 3def suma(a: int, b: int) -> int:
return a + b
print(suma('1','2')) # 12 😅Usando tipado en estructuras de datos. Desde la versión 3.6 debemos importar librerias.
from typing import Dict, List
positives: List[int] = [1,2,3,4,5]
users: Dict[str, int] = {
'argentina': 1,
'mexico': 34,
'colombia': 45,
}
countries: List[Dict[str,str]] = [
{
'name': 'Argentina',
'people': '450000', # Cuatrocientos cincuenta mil
},
{
'name': 'México',
'people': '90000000', # Noventa millones
},
{
'name': 'Colombia',
'people': '99999999999', #novecientos noventa y nueve mil millones novecientos mil novecientos noventa y nueve
}
]from typing import Tuple
numbers: Tuple[int, float, int] = (1, 0.5, 1)from typing import Tuple, Dict, List
CoordinatesType = List[Dict[str, Tuple[int, int]]]
#Una variable que es de tipo CoordinatesType 🤯
coordinates: CoordinatesType = [
{
'coord1': (1,2),
'coord2': (3,5),
},
{
'coord1': (0,1),
'coord2': (2,5),
},
]Ventajas de esto: claridad del código.
El modulo mypy se complementa con el modulo typing ya que permitirá mostrar los errores de tipado débil en Python.
pip install mypy
Para revisar si algún archivo contiene errores de tipado ejecutamos en la línea de comandos lo siguiente:
mypy archivo.py --check-untyped-defs
Como resultado nos mostrará si existe algún error de compatibilidad de tipos.
El scope es el alcance que tienen las variables. Depende de donde declares o inicialices una variable para saber si tienes acceso. Regla de oro:
una variable solo esta disponible dentro de la region donde fue creada
Es la región que corresponde el ámbito de una función, donde podremos tener una o mas variables, las variables van a ser accesibles únicamente en esta region y no serán visibles para otras regiones
Al escribir una o mas variables en esta region, estas podrán ser accesibles desde cualquier parte del código.
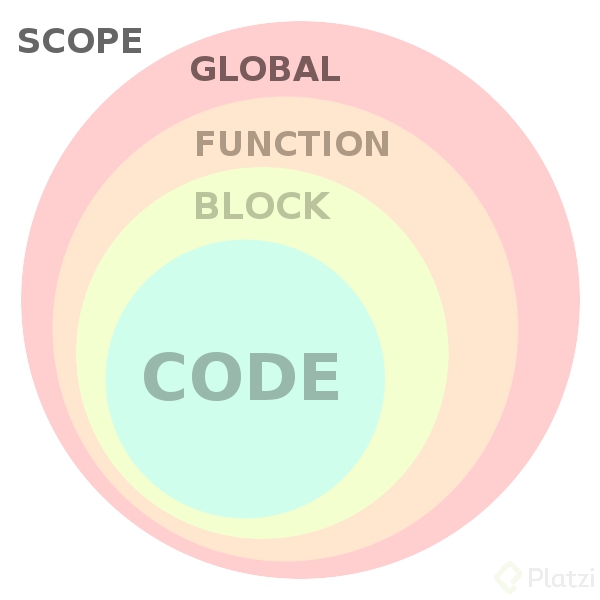
Para visualizar el ámbito local y global de las variables:

def main():
a = 1
def nested():
print(a)
nested() # 1
main()closure:
def main():
a = 1
def nested():
print(a)
return nested
my_func = main()
my_func() # 1Quiere decir que una variable que está en un scope superior, es recordada por una función de scope inferior.
def main():
a = 1
def nested():
print(a)
return nested
my_func = main()
my_func() # 1
del(main) # borramos la función
my_func() # 1 🤯 debido a la nested functionReglas para encontrar un closure:
- Debemos tener una nested function.
- La nested function debe referenciar un valor de un scope superior.
- La función que envuelve a la nested function debe retornarla también.
def make_multiplier(x):
def multiplier(n):
return x * n
return multiplier
times10 = make_multiplier(10)
times4 = make_multiplier(4)
print(times10(3)) # => 10 * 3 = 30
print(times4(5)) # => 4 * 5 = 20
print(times10(times4(2))) # => 4 * 2 * 10 = 80¿Dónde aparecen los closures?
- Clase con solo 1 método
- Cuando trabajamos con decoradores
def make_repeater_of(n):
def repeater(string):
assert type(string) == str,"solo puedes usar string"
return string * n
return repeater
def main():
repeat_5 = make_repeater_of(5)
print(repeat_5('hola'))
if __name__ == '__main__':
main()
Función que recibe como parametro otra función, le añade nuevas funcionalidades y retorna una función diferente.
Una función que le añade super poderes a otra función.
Ejemplo:
def decorador(func):
def envoltura():
print("Esto se añade a mi función original")
func()
return envoltura
def saludo():
print("Hola")
saludo() # output: Hola
saludo = decorador(saludo)
saludo =
# output:
# Esto se añade a mi función original
# HolaDe forma más estetica:
def decorador(func):
def envoltura():
print("Esto se añade a mi función original")
func()
return envoltura
@decorador
def saludo()
print("Hola")
saludo()
# output:
# Esto se añade a mi función original
# HolaOtro ejemplo:
def mayusculas(func):
def envoltura(texto):
return func(texto).upper()
return envoltura
@mayusculas
def mensaje(nombre):
return f'{nombre}, recibiste un mensaje'
print(mensaje('Felipe'))
#output
FELIPE, RECIBISTE UN MENSAJEfrom datetime import datetime
def execution_time(func):
def wrapper(*args, **kwargs):
initial_time = datetime.now()
func(*args, **kwargs)
final_time = datetime.now()
time_elapsed = final_time - initial_time
print(f'Pasaron {time_elapsed.total_seconds()} segundos')
return wrapper
@execution_time
def random_func():
for _ in range(1, 10000000):
pass
random_func()
Antes de entender qué son los iteradores, primero debemos entender a los iterables.
Son todos aquellos objetos que podemos recorrer en un ciclo. Son aquellas estructuras de datos divisibles en elementos únicos que yo puedo recorrer en un ciclo.
Pero en Python las cosas no son así. Los iterables se convierten en iteradores.
Ejemplo:
# Creando un iterador
my_list = [1,2,3,4,5]
my_iter = iter(my_list)
# Iterando un iterador
print(next(my_iter))
# Cuando no quedan datos, la excepción StopIteration es elevada# Creando un iterador
my_list = [1,2,3,4,5]
my_iter = iter(my_list)
# Iterando un iterador
while True: #ciclo infinito
try:
element = next(my_iter)
print(element)
except StopIteration:
breakMomento impactante: El ciclo “for” dentro de Python, no existe. Es un while con StopIteration. 🤯🤯🤯
my_list = [1,2,3,4,5]
for element in my_list:
print(element)evenNumbers.py:
class EvenNumbers:
"""Clase que implementa un iterador de todos los números pares,
o los números pares hasta un máximo
"""
#* Constructor de la clase
def __init__(self, max = None): #self hace referencia al objeto futuro que voy a crear con esta clase
self.max = max
# Método para tener elementos o atributos que voy a necesitar para que el iterador funcione
def __iter__(self):
self.num = 0 #Primer número par
#* Convertir un iterable en un iterador
return self
# Método para tener la función "next" de Python
def __next__(self):
if not self.max or self.num <= self.max:
result = self.num
self.num += 2
return result
else:
raise StopIterationVentajas de usar iteradores:
- Nos ahorra recursos.
- Ocupan poca memoria.
from time import sleep
class FiboIter():
def __init__(self, max_number:int):
self.max_number = max_number
def __iter__(self):
self.n1 = 0
self.n2 = 1
self.counter = 0
return self
def __next__(self):
if self.counter == 0:
self.counter += 1
return self.n1
elif self.counter == 1:
self.counter += 1
return self.n2
else:
self.aux = self.n1 + self.n2
if self.aux >= self.max_number:
raise StopIteration
self.n1, self.n2 = self.n2, self.aux
self.counter += 1
return self.aux
if __name__ == "__main__":
for element in FiboIter(39):
print(element)
sleep(0.1)
Los generadores son azúcar sintáctica para los Iteradores. Son básicamente funciones que guardan un estado, a diferencia de los iteradores, que son clases.
Ejemplo:
def my_gen():
"""Un ejemplo de generadores"""
print("Hello world")
n = 0
yield n
print("Hello heaven")
n = 1
yield n
print("Hello hell")
n = 2
yield n
a = my_gen()
print(next(a))
print(next(a))
print(next(a))
print(next(a)) StopIterationYield es lo mismo que return, con la diferencia de que yield, en lugar de terminar la función solo pausa la función hasta donde estaba ese yield. Es decir, que si después se vuelve a llamar a la función no va a comenzar desde el principio, sino desde donde se quedó el último yield.
Son lo mismo que un list o dictionary comprehension pero para un generador.
my_secong_gen = (x*2 for x in my_list)Un pequeño resumen:
Los sets son una estructura de datos muy similares a las listas en cuanto a su forma, pero presentan ciertas características particulares:
-
Los sets son inmutables
-
Cada elemento del set es único, esto es que no se admiten duplicados, aun si durante la definición del set se agregan elementos repetidos pyhton solo guarda un elemento
-
los sets guardan los elementos en desorden
Para declararlos se utilizan los {} parecido a los diccionarios solo que carece de la composición de conjunto {a:b, c:d}
# set de enteros
my_set = {1, 3, 5}
print(my_set)
# set de diferentes tipos de datos
my_set = {1.0, "Hi", (1, 4, 7)}
print(my_set)Los sets no pueden ser leídos como las listas o recorridos a través de slices, esto debido a que no tienen un criterio de orden. Sin embargo si podemos agregar o eliminar items de los sets utilizando métodos:
- add(): nos permite agregar elementos al set, si se intenta agregar un elemento existente simplemente python los ignorara
- update(): nos permite agregar múltiples elementos al set
- remove(): permite eliminar un elemento del set, en el caso en que no se encuentre presente dicho elemento, Python elevará un error
- discard(): permite eliminar un elemento del set, en el caso en que no se encuentre presente dicho elemento, Python dejará el set intacto, sin elevar ningún error.
- pop(): permite eliminar un elemento del set, pero lo hará de forma aleatoria.
- clear(): Limpia completamente el set, dejándolo vació.
#ejemplo de operaciones sobre sets
my_set = {1, 2, 3}
print(my_set) #Output {1, 2, 3}
#añadiendo un elemento al set
my_set.add(4)
print(my_set) #Output {1, 2, 3, 4}
#añadiendo varios elementos al set, python ignorará elementos repetidos
my_set.update([1, 5, 6])
print(my_set) #Output {1, 2, 3, 4, 5, 6}
# eliminado elementos del set
my_set.discard(1)
print(my_set) #Output {2, 3, 4, 5, 6}
# borrando un elemento aleatorio
my_set.pop()
print(my_set) #Output el set menos un elemento aleatorio
#limpiar el set
my_set.clear()
print(my_set) # Output set() Podemos utilizar estructuras de datos existentes para transformarlas a sets utilizando el método set:
#usando listas para crear sets
my_list = [1, 2, 3, 3, 4, 5]
my_set = set(my_list)
print(my_set) #output {1, 2, 3, 4, 5}
#usando tuplas para crear sets
my_tuple: ('hola', 'hola', 1, 2)
my_set2: set(my_tuple)
print(my_set2) #Output {'hola', 1}El código
def union(set_one, set_two):
# Combinacion de sets
return set_one | set_two
def interseccion(set_one, set_two):
# Interseccion; el resultado de combinar ambos sets, pero solo nos quedamos
# con los elementos en comun.
return set_one & set_two
def diferencias(set_one, set_two):
# Diferencia; el resultado de tomar dos sets, y remover todo lo que contenga
# el segundo set, se arrojan todos los datos del primer set sin los repetidos
# con el segundo.
return set_one - set_two
def diferencia_simetrica(set_one, set_two):
# Diferencia simetrica; es lo contrario de la interseccion, excepto lo que se
# comparte.
return set_one ^ set_two
def main():
set_one = {1,2,3}
set_two = {4,2,5,6}
print()
print("Union: ", union(set_one, set_two))
print("Diferencias: ", diferencias(set_one, set_two))
print("Diferencia simetrica: ", diferencia_simetrica(set_one, set_two))
print("Interseccion: ", interseccion(set_one, set_two))
if __name__ == '__main__':
main()
es mas largo, pero se lee perfectamente.
datetime es un módulo de manejo de fechas.
import datetime
my_time = datetime.datetime.now() # hora local de mi PC u hora universal
my_date = datetime.date.today() # fecha actual
my_day = datetime.date.today()
print(my_time)
print(my_date)
print(f'Year: {my_day.year}')
print(f'Month: {my_day.month}')
print(f'Day: {my_day.day}')Tabla de códigos de formato para fechas y horas(los más importantes):
Formato
| Format | Date |
|---|---|
| %Y | Year |
| %m | Month |
| %d | Day |
| %H | Hour |
| %M | Minute |
| %S | Second |
from datetime import datetime
my_datetime = datetime.now()
print(my_datetime)
latam = my_datetime.strftime('%d/%m/%Y')
print(f'Formato LATAM: {latam}')
usa = my_datetime.strftime('%m/%d/%Y')
print(f'Formato USA: {usa}')
random_format = my_datetime.strftime('año %Y mes %m día %d')
print(f'Formato random: {random_format}')
formato_utc = datetime.utcnow()
print(f'Formato UTC: {formato_utc}')instalar modulo para trabajar con zona horarias
pip install pytz
codigo
from datetime import datetime
import pytz
def time_zone(zone):
bogota_timezone = pytz.timezone(zone)
bogota_date = datetime.now(bogota_timezone)
return(zone, bogota_date.strftime('%d/%m/%Y , %H:%M:%S'))
my_zone = ('America/Bogota','America/Mexico_City','America/Caracas','Europe/Lisbon','Europe/Berlin')
res = [time_zone(zone) for zone in my_zone]
print(res)fin del curso de python avazando