Memory leak when reloading model #11863
-
|
Hello, we have three models trained and provided with FAST API and we are currently suffering from memory leak due to spacy.vocab accumulating with every request. (more about here:#10015). The solution proposed was to reload the model with a certain criteria but all the time we reload it the models are incrementing the usage of memory. The memory profiller used. -> memory-profiler Every reloading we were deleting all content from our models dict created as a model caching and collecting it with gc. This cleans around 30% of all memory usage. After reloading, we noticed that every loading is increasing a dict type data within spacy.load Model graph -> built with objgraph
We added a temporary API to test the reloading and find the issue: The managar build all models and saves it within a dict attribute When reloading, the model checks if there is something within the dict and erase it API code Model build and manager Model |
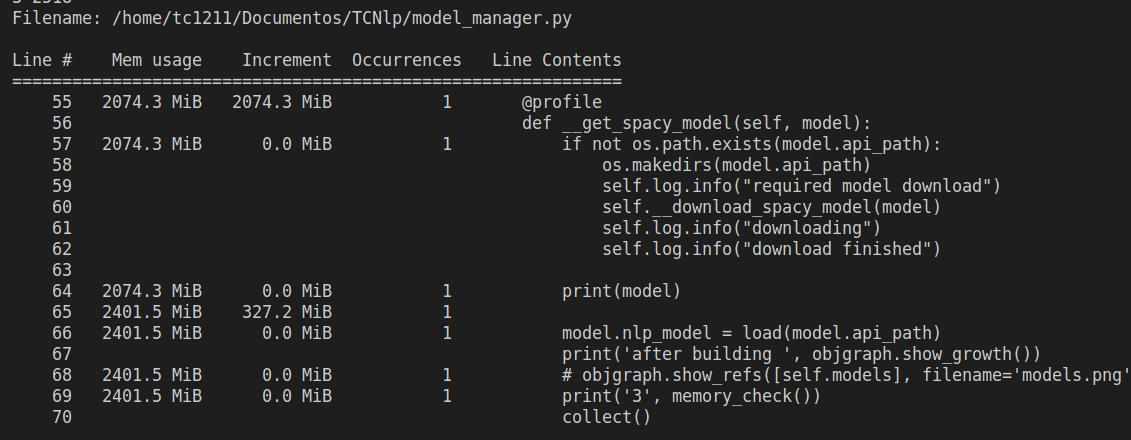
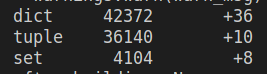

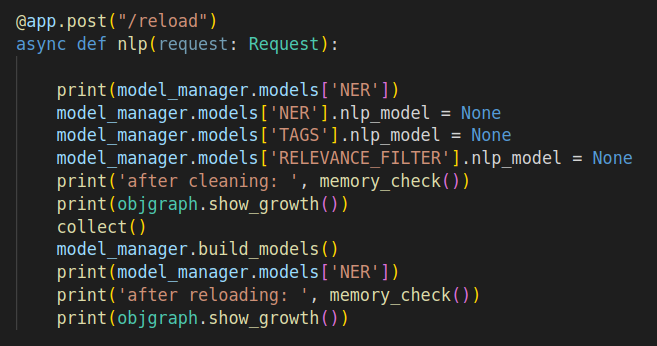

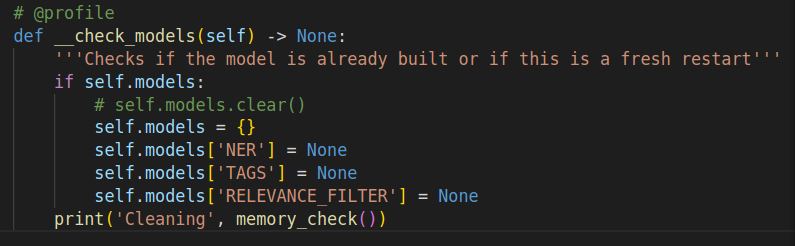
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 4 replies
-
|
It's really hard for us to follow what might be going on here. Could you please provide code and text output as markdown code blocks rather than screenshots? See: https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks In general we're happy to try and help debug cases like this because we would definitely want to address memory leaks, but it's easiest for us to get started if there's a single script we can copy and run to reproduce the problem, like a minimal FastAPI example that does the model reloading. |
Beta Was this translation helpful? Give feedback.
-
|
Good morning, sure here it goes. Model_manager.py # pylint: disable=C0116, C0115, C0114, C0103, R0903
import os
import logging
from model import Model
from memory_profiler import profile
from spacy import load
class ModelManager:
BUCKET_NAME = "nlp_hml"
models = {}
@profile
def __init__(self, logger: logging.Logger):
self.log = logger
@profile
def __download_spacy_model(self, model: Model):
pass
# @profile
def build_models(self):
self.__check_models()
models = [Model(api_path='./models/tags/tags_v2', model_name='TAGS', nlp_model=None, storage_path="pt_core_news_lg"), Model(api_path='./models/relevance_filter/relevance_v2', model_name='RELEVANCE_FILTER', nlp_model=None, storage_path="pt_core_news_lg"), Model(api_path='./models/ner/ner_v3', model_name='NER', nlp_model=None, storage_path="pt_core_news_lg")]
# this is a simulation of the 3 loading models using spacy package pt_core_news_lg
for model in models:
self.models[model.model_name] = model
self.__get_spacy_model(self.models[model.model_name])
self.log.info(self.models)
@profile
def __get_spacy_model(self, model):
if not os.path.exists(model.api_path):
os.makedirs(model.api_path)
self.log.info("required model download")
self.__download_spacy_model(model)
self.log.info("downloading")
self.log.info("download finished")
model.nlp_model = load(model.api_path)
# @profile
def __check_models(self) -> None:
'''Checks if the model is already built or if this is a fresh restart'''
if self.models:
self.models = {}
self.models['NER'] = None
self.models['TAGS'] = None
self.models['RELEVANCE_FILTER'] = NoneModel.py # pylint: disable=C0115, C0114, C0103
from dataclasses import dataclass
import spacy
@dataclass
class Model:
api_path: str
model_name: str
nlp_model: spacy.language
storage_path: strapi.py # pylint: disable=C0114, C0116, W0703, W0707
import logging
import uvicorn
from fastapi.responses import JSONResponse
from fastapi import FastAPI, HTTPException, Request, status
from model_manager import ModelManager
from app.utils.memory_checker import memory_check
from gc import collect
app = FastAPI()
logger = logging.getLogger("Financial NLP")
model_manager = ModelManager(logger)
@app.middleware('http')
async def exception_handling(request: Request, call_next):
try:
return await call_next(request)
except KeyError:
return JSONResponse(
status_code=status.HTTP_400_BAD_REQUEST,
content={"messages": "Received data is not a valid JSON"}
)
except Exception:
return JSONResponse(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
content={'message': 'Unexpected error occurred...'}
)
@app.post("/reload")
async def nlp(request: Request):
print(model_manager.models['NER'])
model_manager.models['NER'].nlp_model = None
model_manager.models['TAGS'].nlp_model = None
model_manager.models['RELEVANCE_FILTER'].nlp_model = None
print('after cleaning: ', memory_check())
collect()
model_manager.build_models()
print(model_manager.models['NER'])
print('after reloading: ', memory_check())
if __name__ == "__main__":
model_manager.build_models()
uvicorn.run(app, host="0.0.0.0", port=8000)memory_checker.py from psutil import Process
from os import getpid
def memory_check():
process = int(Process(getpid()).memory_info().rss/1000000)
return process |
Beta Was this translation helpful? Give feedback.
-
|
Thanks, the details are helpful! I think inspecting Try this script to see: #10015 (reply in thread) A more detailed explanation in a related thread: #11086 (comment) |
Beta Was this translation helpful? Give feedback.
-
|
Thank you, we noticed the same. We thought about it in two ways:
Are there any other options you could help us with please? |
Beta Was this translation helpful? Give feedback.
-
|
@adrianeboyd The following avoided any complications:
With this two modifications we achieved:
For those in similar need, here is a code sample for what we did: gunicorn.conf.py -> basic config file wsgi_app = "api:app"
bind = "0.0.0.0:8000"
worker_class = "uvicorn.workers.UvicornWorker"
#"sync"
workers = 3
threads = 5
max_requests=100
max_requests_jitter=10
graceful_timeout = 30
preload_app = Truemain.py -> running the api from (remenber to setup your api routing!) import subprocess
subprocess.run(["gunicorn"])spacy.load sample from spacy import load
from torch import set_num_threads
set_num_threads(1) # THIS IS VITAL for running your api as preload with slave workers forking the master
model.nlp_model = load(model.api_path) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for reporting back with your solution! |
Beta Was this translation helpful? Give feedback.
-
What was the effect of this issue? Also I assume the |
Beta Was this translation helpful? Give feedback.
@adrianeboyd The following avoided any complications:
With this two modifications we achieved: