2. 软件界面和概念
Hawk采用类似Visual Studio和Eclipse的Dock风格,所有的组件都可以悬停和切换。包括以下核心组件:
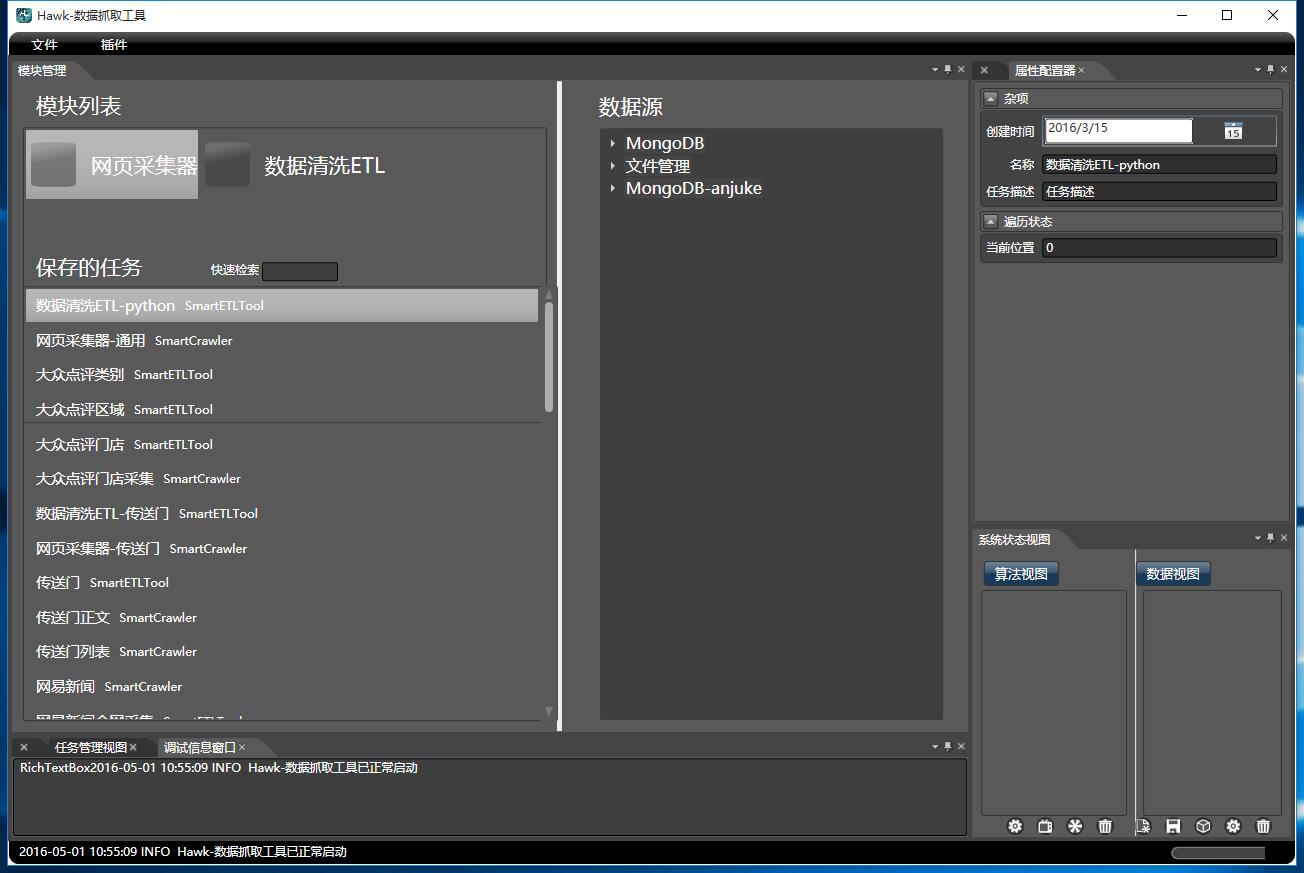
- 左上角区域:主要工作区,任务管理。
- 下方: 输出调试信息,和任务管理,监控一项任务完成的百分比。
- 右上方区域: 属性管理器,能对不同的模块设置属性。
- 右下方区域: 显示当前已经加载的所有数据表和模块。
下面介绍几个关键概念:
- 任务: 系统仅仅提供了两种任务: 网页采集器和数据清洗,任务可以被新建,保存和加载。
- 模块: 一个任务会包含多个模块,例如数据清洗中会有
从文本生成,从爬虫转换等 - 工程: 多个任务组成一个工程,工程可以以xml方式保存和加载
- 数据表:在内存中存储的数据表,速度快,但是容量有限,存储小型数据时使用
- 数据库(连接器): Hawk通过连接器连接不同的数据库,如MongoDB,sqlite等。
- 列: 数据清洗里的列,可参考像Excel里的列,在网页采集器里,一个属性对应一个列
- 文档: 可理解为数据清洗里的一行,它是键值对构成的字典,如
key1:value,key2:value2 - 单元格 : 文档中的一个列,就像Excel那样
- 流: 多个文档的序列,可能是有限或无穷的,在早期版本的Hawk中,这个概念大量使用。
- 线程: 任务在启动时,会有一个(串行)或多个(并行)线程,可以在
工作线程视图中对其进行暂停和删除管理
本文档会大量使用这些概念,并不会再对其作出详细的解释。
在数据视图的右侧,包含了目前所有的连接器。能够添加来自不同数据源的连接器, 并对数据进行加载和管理:
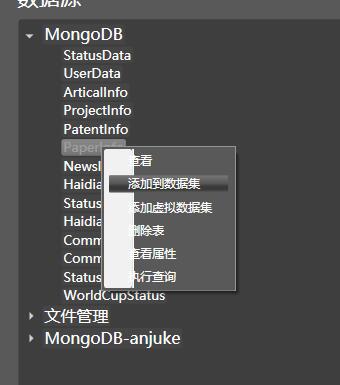
在空白处,点击右键,可增加新的连接器。在连接器的数据表上,双击可查看样例,点击右键,可以将数据加载到内存中。
目前支持的连接器包括:
- MongoDB
- sqlite
- 文件读写
- MySql(测试不完全)
使用sqlite非常简单,新建sqlite连接器后,点击新建,即可创建sqlite的db文件,即可直接使用。
在安装MongoDB之后,在空白位置点右键,即可选择插入一个MongoDB连接器,在服务器地址,用户名和密码,数据库名称上填写所需的字段,然后点击连接数据库即可。
如果你是小白用户,用上面的方法安装了MongoDB,则数据库地址填写127.0.0.1(代表本地),用户名和密码为空,数据库名称填写你想要的任何名字皆可。
这样我们就可以用Hawk将数据写入数据库啦!
目前系统仅仅提供了两个任务: 网页采集器和数据清洗, 双击即可加载一个新的模块。
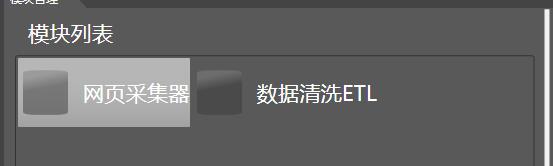
之前配置好的模块,可以保存为任务, 双击或点击右键可加载一个已有任务:
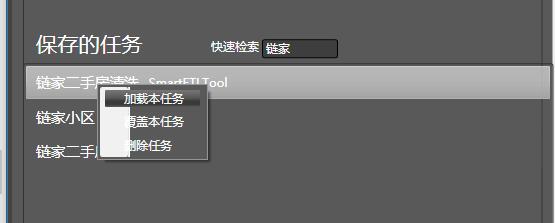
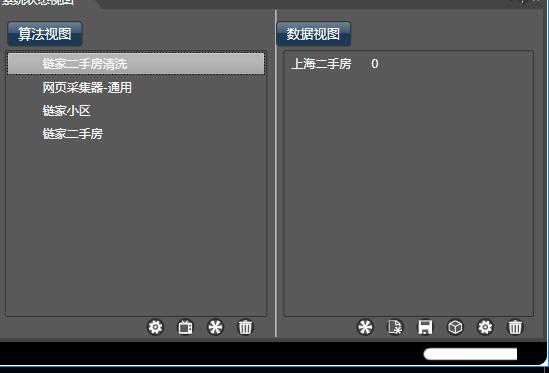
本部分学习了Photoshop的设计。当加载了数据集或模块时,在本视图中,就可对其查看和编辑:
- 点击右键,可以对数据集进行删除,修改名称等
- 将数据集拖拽到下方的图标上,如拖到回收站,即可删除该模块。
双击数据集或模块,可查看模块的内容。 将数据集拖拽到数据清洗( 数据视图的下方第一个图标),可直接对本数据集做数据清洗。