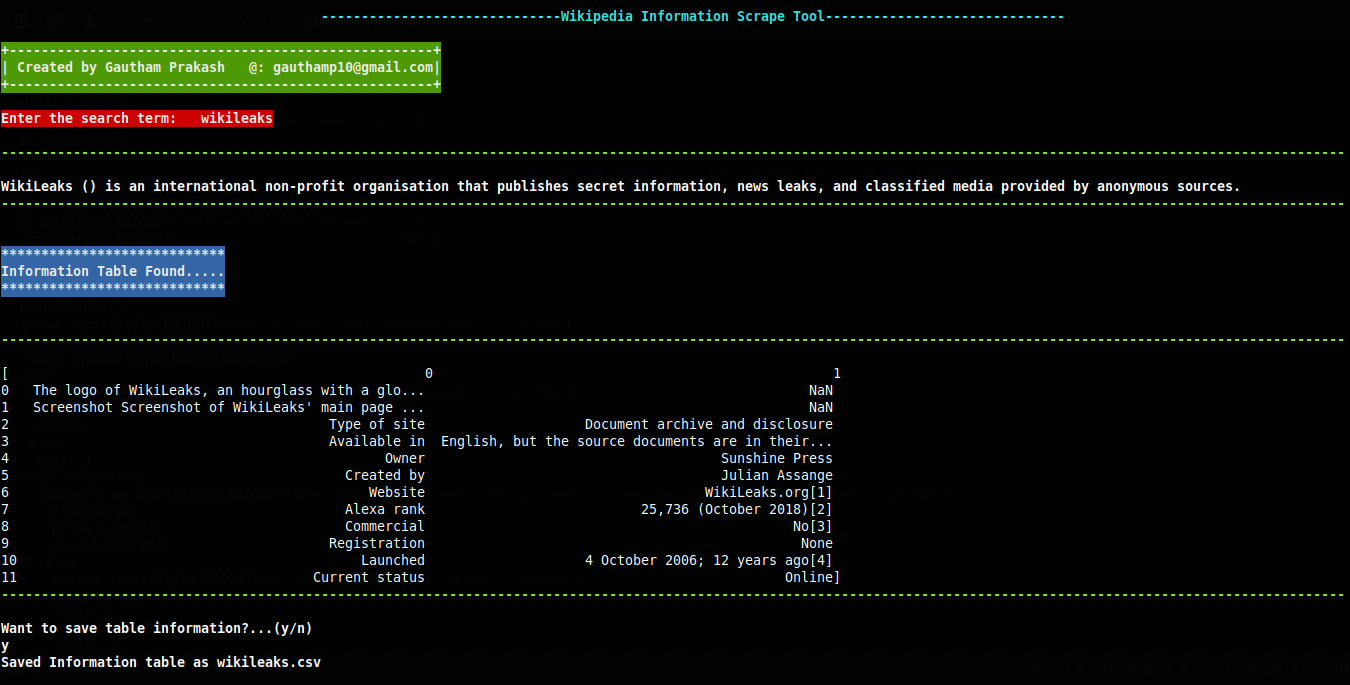
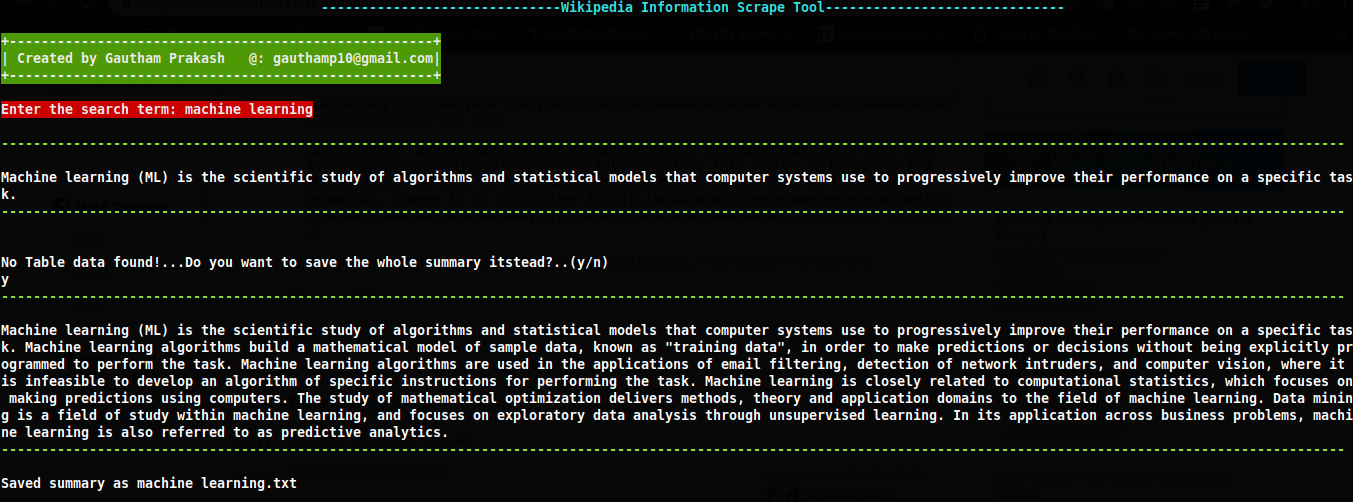
This is a python tool which can be made effective in fetching raw table information for any specific query from any wikipedia pages.It can also be used to fetch summary of any wiki page.The final output of the script can either be saved as a csv or txt file according to the type of data that wiki page contain.
python3
Install the following three python modules before executing wikipedia_info_scraper
- colorama
- pandas
- wikipedia
pip install colorama
pip install pandas
pip install wikipedia
python main.py
📝 Please note pip installable python package will be avialable soon after further testing.

Gautham Prakash
My other projects:github.com/gauthamp10
This project is licensed under the MIT License - see the LICENSE.md file for details