GridGain Community Edition (GCE) is a hardened, high performance, open source in-memory computing platform. Built on Apache® Ignite™, it includes additional functionality, tuning and patches developed by GridGain to deliver optimal performance.
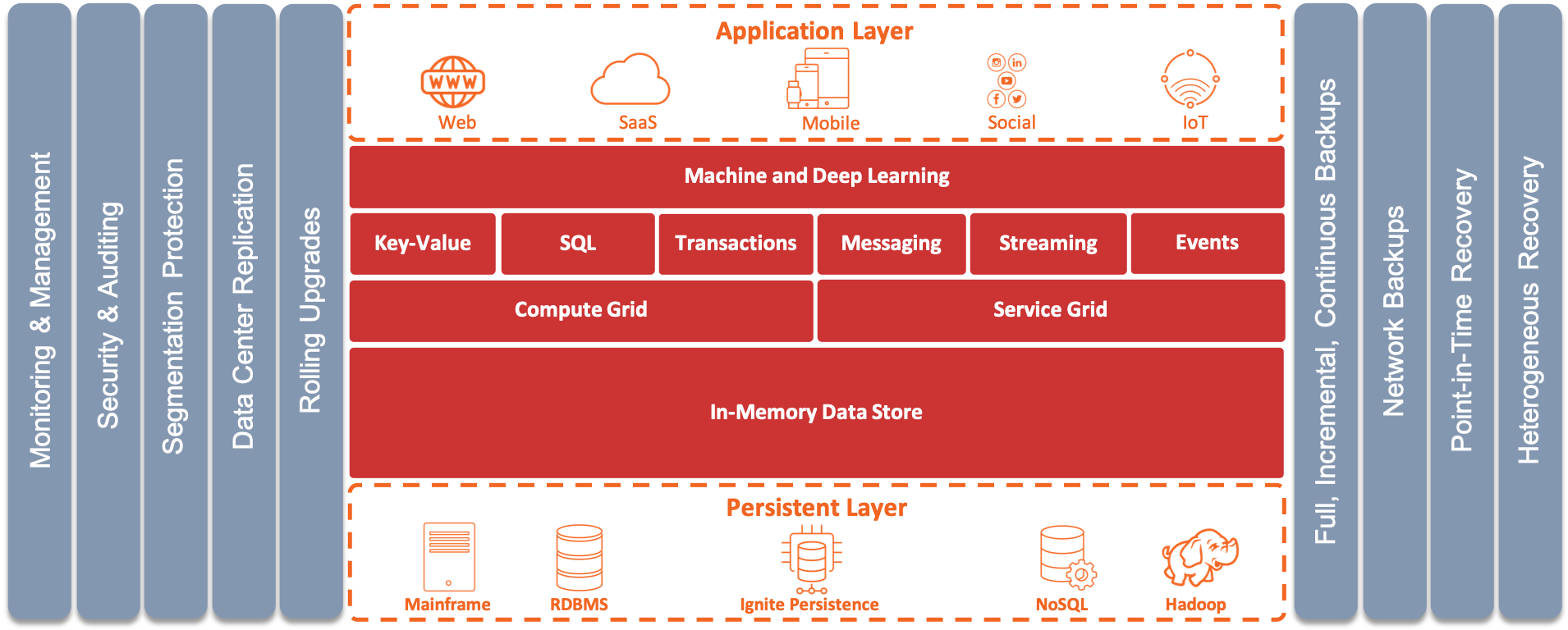
For information on how to get started with GridGain CE, please visit: Getting Started.