With the explosion of eCommerce, there is a growing need for personalized online shopping experiences. Specifically, in the fashion industry, there is a growing number of styles and clothing-types, along with a growing number of people interested in buying clothes online. It is crucial for the fashion industry to provide a personalized experience for each shopper, such that each shopper's personal tastes are accounted for. Concretely, each shopper should be able to describe their preferences and the styles they are looking for, and a list of matching clothing items should be returned. The only way to achieve this goal at scale is through the help of machine learning. In this project, we describe and tackle the novel task of going from fashion styles and attributes to newly generated images. The goal is to synthesize new clothing items based on the user's inputted style and attributes, which can serve multiple purposes downstream: 1) users can experiment with different styles and attributes and see visually what is most appealing to them 2) the newly synthesized images can be used for image retrieval from an eCommerce store's internal database, to return the most visually similar products. While there is existing literature which goes from input images to predicted attributes, we are proposing to build an architecture that goes in the opposite direction: we are attempting to synthesize images from given attributes; this a challenging, novel task which requires the use of generative deep learning models as opposed to classification models.
The DeepFashion dataset contains 289,222 clothing images, annotated with with 1,000 clothing attributes across five attribute and three clothing categories. The text data attributes are modified, removing semantically equivalent attributes, expanding the number of clothing categories into more specific descriptors, and removing the style attribute type (see this code for more details). The final attribute embeddings consist of 486 distinct identifiers, separated into category, shape, texture, fabric, and part bins. The structure is outlined below, where each field, with the exception of category, can have multiple associated attribute identifiers.

The images are grouped broadly into directories based on 2-3 shared attributes to facilitate the CPGGAN LSE loss. These high-level classes are formed from the clothing category and primary common attributes; while all images in a given class will have the shared attributes, there are additional modifying attributes that further distinguish the clothing but are not prevalent enough to form distinct classes. We experiment with forming attribute embeddings comprised solely of the features captured in the class labels, and use this as a baseline when introducing further Generator loss penalties in the CDPGGAN model.
The raw images vary in quality, level of noise, and obfuscation. The GrabCut algorithm is used to standardize the images - first creating a mask based on the bounding box, then honing the model with the convex polygon created by the landmark annotations (implemented here). The final data consists of 108,822 focused images, which are normalized and scaled for input into the stages of the CPGGAN.
All preprocessed data can be found in the google drive.
The baseline dataset that we used is called "Fashion MNIST". It is a publicly available dataset used for benchmarking purposes and contains 60,000 images of clothing items in 10 different categories. All of the images are 28x28 and are grayscale. Preprocessing was generally not required for this dataset except for pixel normalization.
We also trained several models on the Fashion Product Images dataset which contains 44,000 images of fashion products scraped from various e-commerce websites.
The images are labeled by features such as gender, category, base color, season, usage, etc. We utilized two variations of the dataset, with one containing low-resolution images (60px by 80px) and another contained higher-resolution images (1800px x 2400px). Below is a breakdown of the dataset, based on master category of fashion item, subcategory, and base color of the item.

For preprocessing, all images were resized to squares, 64x64 px for the low-resolution images and 256x256 px for the high-resolutions, and normalized.

Generative Adversarial Networks (GAN) are a popular deep learning architecture for training deep generative models. GANs, there is a discriminator network and a generator network. The generator is responsible for generating new samples that are ideally indistinguishable from real samples in the dataset. The discriminator is responsible for distinguishing between real samples and samples created by the generator. The discriminator and generator are trained at the same time in an adversarial manner: improvements to the discriminator will hurt the performance of the generator and vice versa. One drawback of vanilla GANs is that it will generate random images from the domain. In tasks where we have class or attribute labels available, such as ours, it is desirable to be able to control what the GAN generates. Thus, we utilize the Conditional Generative Adversarial Network (CGAN), which was introduced in 2014 ([https://arxiv.org/abs/1411.1784). The CGAN allows one to introduce labels to the discriminator and generator such that one can generate samples conditioned on specific class-labels. Although there are several methods to condition GANs on class labels, the most often-used method by CGANs is to introduce an embedding layer on the class labels, followed by a fully connected layer which scales the embedding layer to the size of the input image, such that it can be concatenated as an additional channel. CGANs can of course be used with any architecture, such as deep convolutional GANs (DCGANs

Variational autoencoders (VAE) are powerful generative autoencoders that learn a latent representation for the input data. Utilizing variational inference and regularization techniques, VAEs learn latent representations with desirable properties, which allow for generating new data points. Vanilla VAEs suffer from the same drawback as vanilla GANs--random images are generated without any knowledge of class-information. This is where Conditional VAEs (CVAE) come into play. The implementation behind CVAEs is very simple: simply concatenate the class labels to the input, and run the encoder-decoder architecture as normal. During training time, the encoder and decoder both have the extra input (the class labels). To generate an image belonging to a particular class, simply feed that class label into the decoder along with the random point in latent space sampled from a normal distribution.

Conditional GANs (cGAN) uses a traditional GAN architecture except with an extra class label for both the generator and the discriminator in order to "condition" the GAN to conform to that label. This is usually done through taking the class label as an extra input and concatenating it with the latent vector of the GAN.
In our multi-conditional variation of the cGAN, we incorporated attribute conditioning in two main ways. The Fashion Product Images dataset provided attributes in the form of multiple classes, so we added extra layers corresponding to each category of attributes in the GAN, and concatenated them all together with the latent dimension so that the model could take in multiple attributes as conditioning while training.

We also attempted encoding the label into an embedding layer and multiplying the input with the latent dimension but produced negligible differences. After preprocessing the DeepFashion dataset, we were able to one-hot-encode the attributes instead, and used that for attribute conditioning the cGAN. Sampling the model's performance was done through giving the model every combination of attributes to generate.
PGGANs increase image resolution through subsequent layers during training, allowing the network to begin by learning a fuzzy concept of the input, and progress to focusing on more specific image features. This is ideal for the DeepFashion dataset, given the high variability of the supplied images, and the goal of controlling across the five attribute fields in generating images.
We define the goal of the Generator: given a noise vector conditioned on attribute embeddings e that corresponds to image class c, create images x that appear real, and will be classified with label c. The Discriminator D(x,e) then needs to critique if the image x is real and in the correct class, in the wrong class, or is fake.
The Generator attempts to push D -> 0 over the generated images & attribute embeddings, while the Discriminator learns toward D -> -1. The Discriminator loss function gives further penalty for moving away from D ->1 on the real & correctly classified images, and rewards recognizing incorrectly classified images equal to finding fake images. For more detail on model parameters and architecture, see cpggan.py.
In this model, the goal of the Discriminator stays the same, while the Generator is given additional feedback targeted toward specific fields. The general idea for disentangling loss:
We start by baselining on attribute embeddings that only contain the features encompassed in the class label. An additional consistency check for clothing category is added in the form:
Where
The Inception network examines clothing images, X, produced by the Generator during testing, in relation to the image class test labels, ![$Y$]. The goal is to optimize the score:
with respect to the two random variables. KL measures the deviation of the distribution P{Y |X} - the probability of labeling an image with a given class - with respect to the reference distribution P Y (y) - the probability of a given class label. The class labels are diverse - high entropy - forcing the entropy of P to be minimized in order to increase the KL divergence. As the entropy of P{Y |X} is minimized when the images in X are labeled with high certainty, this provides a measure for Generator performance.
The inception score is computed over 20,000 images split into five groups, the results of which are averaged. For implementation details, see inception.py.
Inception scores were generated for the CPGGAN and CDPGGAN over the two forms of DeepFashion attribute encodings. Results trend better on the simpler attribute encodings, however the improvement in performance when conditional disentangling on the category field is added indicates that there are further improvements possible when focusing on individual attribute classes.
 )
)
Generated over the limited attribute embedding data on CPGGAN and CDPGGAN models.
CGAN Class-Conditional Generation Results

CVAE Class-Conditional Generation Results

In both grids above, each column represents a specific class label. Clearly, both the CGAN and CVAE are successfully able to generate class-specific images when conditioned on a particular class. The CGAN results are a bit better than the CVAE since the generated images are crisper/less blurry. VAEs are known to generate blurry images in general. Overall, the Fashion MNIST dataset served as a proof-of-concept, showing the effectiveness of class-conditional generative models. However, one limitation of this dataset is that, each image has only one class-label associated with it. In real world applications, each clothing item will have multiple attributes, which motivates the need for Multi-Conditional GANs.
We first trained a standard conditional GAN on the Fashion Products dataset, and generated different images of clothing conditioned on clothing subtype, such as boxers, jeans, t-shirts, etc.

Sample images of multi-conditional GAN trained after 80 epochs
Our next step was to test the multi-conditional aspect of the GAN. By conditioning it on attributes for color and clothing attributes instead of a single fashion type feature, we were able to train the GAN to distinguish different colors, but the modifying the subtype of clothing as well was a challenge for the model.

Images generated from one sample of multi-conditional GAN after training for 30 epochs. The GAN was conditioned on color and type attributes.
After observing the trouble that the GAN had with differentiating with different types of clothing, we experimented with replacing that condition with different fashion types instead. Our intuition was that the visual difference between features like a shirt and a shoe would be greater than simply variations of clothing styles, so the GAN would have an easier time differentiating the conditions while training. After training, our multi-conditional GAN was able to reliably generate the different color and fashion type combinations. However, there were still inconsistencies in generation between different samples.

Images generated by multi-conditional GAN trained for 300 epochs, conditioned on color and fashion type, aggregated from different samples
Stacked Generative Adversarial Networks (StackGAN) were first introduced in the domain of natural text to image generation. The intuition behind the model is analogous to that of a human painter: the artist begins by sketching a rough outline of an image before completing the refined, high-quality artwork. The architecture involves two GANs stacked upon each other, with the first GAN generating a low-resolution image from text embeddings. The low-resolution image generated by the first GAN is used as a “sketch” for input to the second GAN, and provides a frame of reference for the second GAN to generate a high resolution image. This helps avoid common problems with GANs such as mode collapse.
During this project, we adapted the original StackGAN architecture to take attributes as input instead of natural text. This methodology was tested on the Fashion Product Images dataset. In the case of the Fashion Product Images dataset, we used the multi-conditional GAN mentioned before as the first stage in the StackGAN.
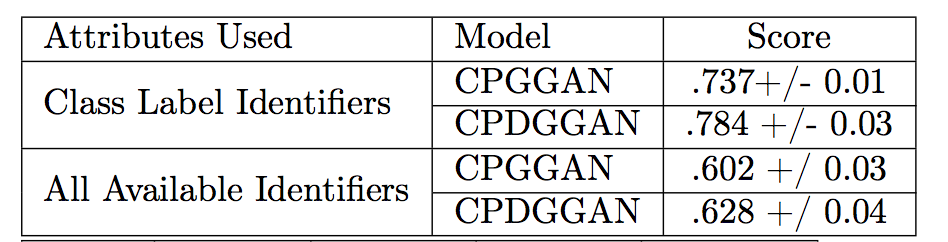
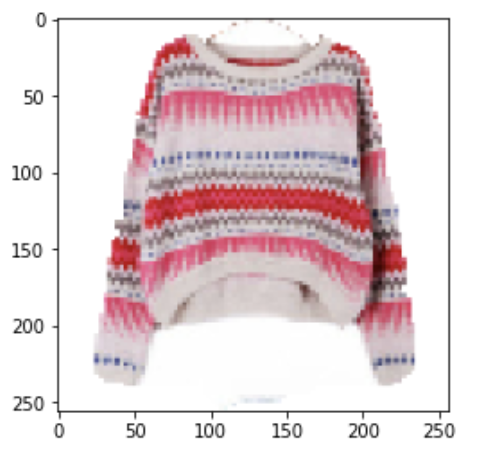
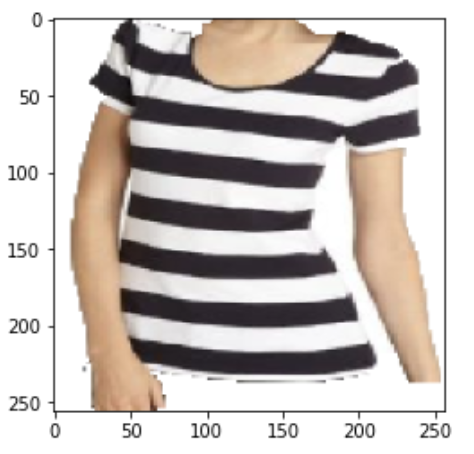
Generated Images using Multi-Conditional GAN + StackGAN Stage2 (5 epochs)

Could be a shirt??

Maybe a shoe??
The above images are high-resolution (256x256 px) images generated when fed data from Multi-Conditional GAN trained on Fashion Product Images dataset. Perhaps with more training time and more refined architecture, we could achieve better results for StackGAN. The model definitely seems to be capturing some structure from the multi-conditional GAN.