-
-
Notifications
You must be signed in to change notification settings - Fork 140
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
888dad6
commit edbd98d
Showing
18 changed files
with
609 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,37 @@ | ||
| --- | ||
| slug: / | ||
| --- | ||
|
|
||
| # Introduction | ||
|
|
||
| Hoarder is an open source "Bookmark Everything" app that uses AI for automatically tagging the content you throw at it. The app is built with self-hosting as a first class citizen. | ||
|
|
||
| 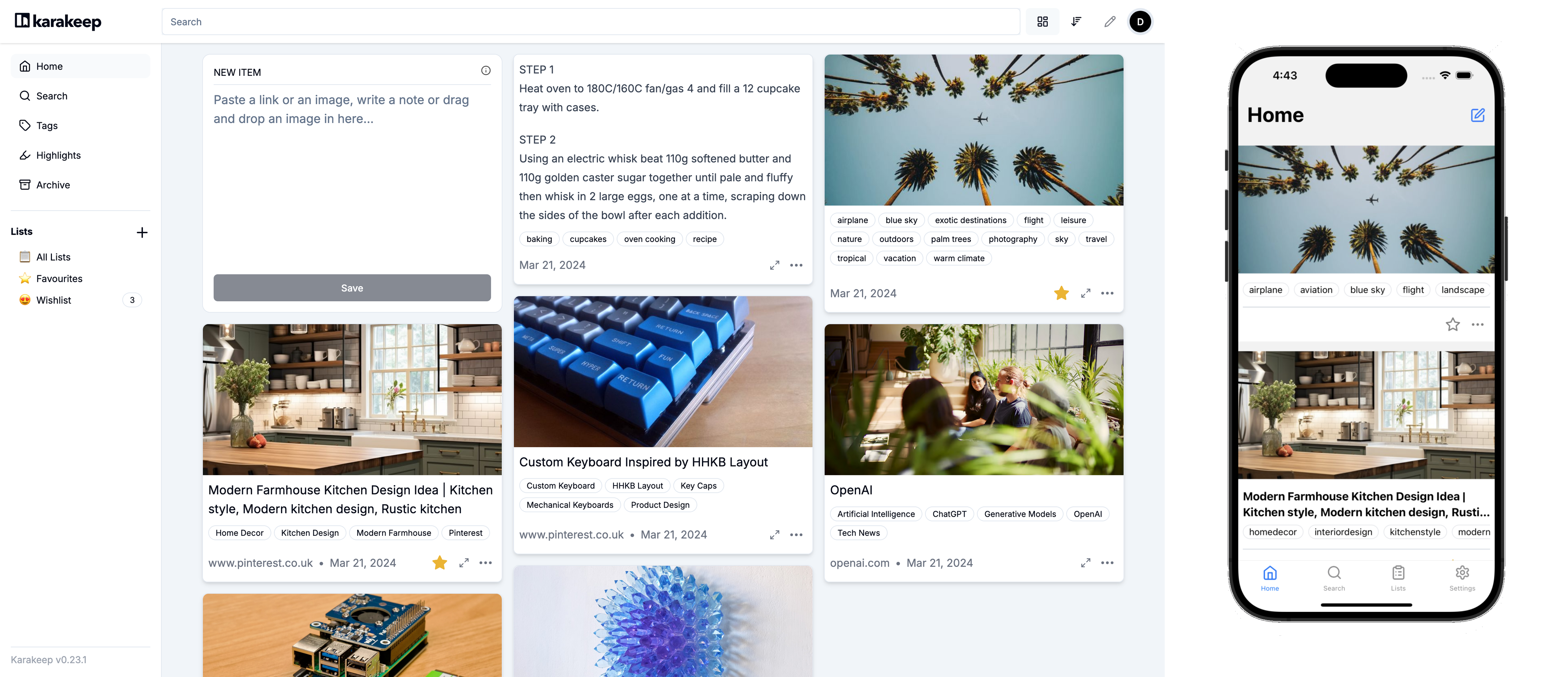 | ||
|
|
||
|
|
||
| ## Features | ||
|
|
||
| - 🔗 Bookmark links, take simple notes and store images. | ||
| - ⬇️ Automatic fetching for link titles, descriptions and images. | ||
| - 📋 Sort your bookmarks into lists. | ||
| - 🔎 Full text search of all the content stored. | ||
| - ✨ AI-based (aka chatgpt) automatic tagging. With supports for local models using ollama! | ||
| - 🔖 [Chrome plugin](https://chromewebstore.google.com/detail/hoarder/kgcjekpmcjjogibpjebkhaanilehneje) and [Firefox addon](https://addons.mozilla.org/en-US/firefox/addon/hoarder/) for quick bookmarking. | ||
| - 📱 An [iOS app](https://apps.apple.com/us/app/hoarder-app/id6479258022), and an [Android app](https://play.google.com/store/apps/details?id=app.hoarder.hoardermobile&pcampaignid=web_share). | ||
| - 🌙 Dark mode support. | ||
| - 💾 Self-hosting first. | ||
| - [Planned] Downloading the content for offline reading. | ||
|
|
||
| **⚠️ This app is under heavy development and it's far from stable.** | ||
|
|
||
|
|
||
| ## Demo | ||
|
|
||
| You can access the demo at [https://try.hoarder.app](https://try.hoarder.app). Login with the following creds: | ||
|
|
||
| ``` | ||
| email: demo@hoarder.app | ||
| password: demodemo | ||
| ``` | ||
|
|
||
| The demo is seeded with some content, but it's in read-only mode to prevent abuse. |
86 changes: 86 additions & 0 deletions
86
docs/versioned_docs/version-v0.15.0/02-Installation/01-docker.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,86 @@ | ||
| # Docker Compose [Recommended] | ||
|
|
||
| ### Requirements | ||
|
|
||
| - Docker | ||
| - Docker Compose | ||
|
|
||
| ### 1. Create a new directory | ||
|
|
||
| Create a new directory to host the compose file and env variables. | ||
|
|
||
| ### 2. Download the compose file | ||
|
|
||
| Download the docker compose file provided [here](https://github.com/hoarder-app/hoarder/blob/main/docker/docker-compose.yml). | ||
|
|
||
| ``` | ||
| wget https://raw.githubusercontent.com/hoarder-app/hoarder/main/docker/docker-compose.yml | ||
| ``` | ||
|
|
||
| ### 3. Populate the environment variables | ||
|
|
||
| To configure the app, create a `.env` file in the directory and add this minimal env file: | ||
|
|
||
| ``` | ||
| HOARDER_VERSION=release | ||
| NEXTAUTH_SECRET=super_random_string | ||
| MEILI_MASTER_KEY=another_random_string | ||
| NEXTAUTH_URL=http://localhost:3000 | ||
| ``` | ||
|
|
||
| You **should** change the random strings. You can use `openssl rand -base64 36` to generate the random strings. You should also change the `NEXTAUTH_URL` variable to point to your server address. | ||
|
|
||
| Using `HOARDER_VERSION=release` will pull the latest stable version. You might want to pin the version instead to control the upgrades (e.g. `HOARDER_VERSION=0.10.0`). Check the latest versions [here](https://github.com/hoarder-app/hoarder/pkgs/container/hoarder-web). | ||
|
|
||
| Persistent storage and the wiring between the different services is already taken care of in the docker compose file. | ||
|
|
||
| Keep in mind that every time you change the `.env` file, you'll need to re-run `docker compose up`. | ||
|
|
||
| If you want more config params, check the config documentation [here](/configuration). | ||
|
|
||
| ### 4. Setup OpenAI | ||
|
|
||
| To enable automatic tagging, you'll need to configure OpenAI. This is optional though but hightly recommended. | ||
|
|
||
| - Follow [OpenAI's help](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key) to get an API key. | ||
| - Add the OpenAI API key to the env file: | ||
|
|
||
| ``` | ||
| OPENAI_API_KEY=<key> | ||
| ``` | ||
|
|
||
| Learn more about the costs of using openai [here](/openai). | ||
|
|
||
| <details> | ||
| <summary>[EXPERIMENTAL] If you want to use Ollama (https://ollama.com/) instead for local inference.</summary> | ||
|
|
||
| **Note:** The quality of the tags you'll get will depend on the quality of the model you choose. Running local models is a recent addition and not as battle tested as using openai, so proceed with care (and potentially expect a bunch of inference failures). | ||
|
|
||
| - Make sure ollama is running. | ||
| - Set the `OLLAMA_BASE_URL` env variable to the address of the ollama API. | ||
| - Set `INFERENCE_TEXT_MODEL` to the model you want to use for text inference in ollama (for example: `mistral`) | ||
| - Set `INFERENCE_IMAGE_MODEL` to the model you want to use for image inference in ollama (for example: `llava`) | ||
| - Make sure that you `ollama pull`-ed the models that you want to use. | ||
|
|
||
|
|
||
| </details> | ||
|
|
||
| ### 5. Start the service | ||
|
|
||
| Start the service by running: | ||
|
|
||
| ``` | ||
| docker compose up -d | ||
| ``` | ||
|
|
||
| Then visit `http://localhost:3000` and you should be greated with the Sign In page. | ||
|
|
||
| ### [Optional] 6. Setup quick sharing extensions | ||
|
|
||
| Go to the [quick sharing page](/quick-sharing) to install the mobile apps and the browser extensions. Those will help you hoard things faster! | ||
|
|
||
| ## Updating | ||
|
|
||
| Updating hoarder will depend on what you used for the `HOARDER_VERSION` env variable. | ||
| - If you pinned the app to a specific version, bump the version and re-run `docker compose up -d`. This should pull the new version for you. | ||
| - If you used `HOARDER_VERSION=release`, you'll need to force docker to pull the latest version by running `docker compose up --pull always -d`. |
21 changes: 21 additions & 0 deletions
21
docs/versioned_docs/version-v0.15.0/02-Installation/02-unraid.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| # Unraid | ||
|
|
||
| ## Docker Compose Manager Plugin (Recommended) | ||
|
|
||
| You can use [Docker Compose Manager](https://forums.unraid.net/topic/114415-plugin-docker-compose-manager/) plugin to deploy Hoarder using the official docker compose file provided [here](https://github.com/hoarder-app/hoarder/blob/main/docker/docker-compose.yml). After creating the stack, you'll need to setup some env variables similar to that from the docker compose installation docs [here](/Installation/docker#3-populate-the-environment-variables). | ||
|
|
||
| ## Community Apps | ||
|
|
||
| :::info | ||
| The community application template is maintained by the community. | ||
| ::: | ||
|
|
||
| Hoarder can be installed on Unraid using the community application plugins. Hoarder is a multi-container service, and because unraid doesn't natively support that, you'll have to install the different pieces as separate applications and wire them manually together. | ||
|
|
||
| Here's a high level overview of the services you'll need: | ||
|
|
||
| - **Hoarder** ([Support post](https://forums.unraid.net/topic/165108-support-collectathon-hoarder/)): Hoarder's main web app. | ||
| - **hoarder-worker** ([Support post](https://forums.unraid.net/topic/165108-support-collectathon-hoarder/)): Hoarder's background workers (for running the AI tagging, fetching the content, etc). | ||
| - **Redis**: Currently used for communication between the web app and the background workers. | ||
| - **Browserless** ([Support post](https://forums.unraid.net/topic/130163-support-template-masterwishxbrowserless/)): The chrome headless service used for fetching the content. Hoarder's official docker compose doesn't use browserless, but it's currently the only headless chrome service available on unraid, so you'll have to use it. | ||
| - **MeiliSearch** ([Support post](https://forums.unraid.net/topic/164847-support-collectathon-meilisearch/)): The search engine used by Hoarder. It's optional but highly recommended. If you don't have it set up, search will be disabled. |
48 changes: 48 additions & 0 deletions
48
docs/versioned_docs/version-v0.15.0/02-Installation/03-archlinux.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,48 @@ | ||
| # Arch Linux | ||
|
|
||
| ## Installation | ||
|
|
||
| > [Hoarder on AUR](https://aur.archlinux.org/packages/hoarder) is not maintained by the hoarder official. | ||
| 1. Install hoarder | ||
|
|
||
| ```shell | ||
| paru -S hoarder | ||
| ``` | ||
|
|
||
| 2. (**Optional**) Install optional dependencies | ||
|
|
||
| ```shell | ||
| # meilisearch: for full text search | ||
| paru -S meilisearch | ||
| # ollama: for automatic tagging | ||
| paru -S ollama | ||
| # hoarder-cli: hoarder cli tool | ||
| paru -S hoarder-cli | ||
| ``` | ||
|
|
||
| You can use Open-AI instead of `ollama`. If you use `ollama`, you need to download the ollama model. Please refer to: [https://ollama.com/library](https://ollama.com/library). | ||
|
|
||
| 3. Set up | ||
|
|
||
| Environment variables can be set in `/etc/hoarder/hoarder.env` according to [configuration page](/configuration). **The environment variables that are not specified in `/etc/hoarder/hoarder.env` need to be added by yourself.** | ||
|
|
||
| 4. Enable service | ||
|
|
||
| ```shell | ||
| sudo systemctl enable --now hoarder.target | ||
| ``` | ||
|
|
||
| Then visit `http://localhost:3000` and you should be greated with the Sign In page. | ||
|
|
||
| ## Services and Ports | ||
|
|
||
| `hoarder.target` include 3 services: `hoarder-web.service`, `hoarder-works.service`, `hoarder-browser.service`. | ||
|
|
||
| - `hoarder-web.service`: Provide hoarder WebUI service, use `3000` port default. | ||
|
|
||
| - `hoarder-works.service`: Provide hoarder works service, no port. | ||
|
|
||
| - `hoarder-browser.service`: Provide browser headless service, use `9222` port default. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,52 @@ | ||
| # Configuration | ||
|
|
||
| The app is mainly configured by environment variables. All the used environment variables are listed in [packages/shared/config.ts](https://github.com/hoarder-app/hoarder/blob/main/packages/shared/config.ts). The most important ones are: | ||
|
|
||
| | Name | Required | Default | Description | | ||
| | ------------------------- | ------------------------------------- | --------- | ---------------------------------------------------------------------------------------------------------------------------------------------- | | ||
| | DATA_DIR | Yes | Not set | The path for the persistent data directory. This is where the db and the uploaded assets live. | | ||
| | NEXTAUTH_URL | Yes | Not set | Should point to the address of your server. The app will function without it, but will redirect you to wrong addresses on signout for example. | | ||
| | NEXTAUTH_SECRET | Yes | Not set | Random string used to sign the JWT tokens. Generate one with `openssl rand -base64 36`. | | ||
| | REDIS_HOST | Yes | localhost | The address of redis used by background jobs | | ||
| | REDIS_PORT | Yes | 6379 | The port of redis used by background jobs | | ||
| | REDIS_DB_IDX | No | Not set | The db idx to use with redis. It defaults to 0 (in the client) so you don't usually need to set it unless you explicitly want another db. | | ||
| | REDIS_PASSWORD | No | Not set | The password used for redis authentication. It's not required if your redis instance doesn't require AUTH. | | ||
| | MEILI_ADDR | No | Not set | The address of meilisearch. If not set, Search will be disabled. E.g. (`http://meilisearch:7700`) | | ||
| | MEILI_MASTER_KEY | Only in Prod and if search is enabled | Not set | The master key configured for meilisearch. Not needed in development environment. Generate one with `openssl rand -base64 36` | | ||
| | DISABLE_SIGNUPS | No | false | If enabled, no new signups will be allowed and the signup button will be disabled in the UI | | ||
| | MAX_ASSET_SIZE_MB | No | 4 | Sets the maximum allowed asset size (in MB) to be uploaded | | ||
| | DISABLE_NEW_RELEASE_CHECK | No | false | If set to true, latest release check will be disabled in the admin panel. | | ||
|
|
||
| ## Inference Configs (For automatic tagging) | ||
|
|
||
| Either `OPENAI_API_KEY` or `OLLAMA_BASE_URL` need to be set for automatic tagging to be enabled. Otherwise, automatic tagging will be skipped. | ||
|
|
||
| :::warning | ||
|
|
||
| - The quality of the tags you'll get will depend on the quality of the model you choose. | ||
| - Running local models is a recent addition and not as battle tested as using OpenAI, so proceed with care (and potentially expect a bunch of inference failures). | ||
| ::: | ||
|
|
||
| | Name | Required | Default | Description | | ||
| | --------------------- | -------- | ------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | ||
| | OPENAI_API_KEY | No | Not set | The OpenAI key used for automatic tagging. More on that in [here](/openai). | | ||
| | OPENAI_BASE_URL | No | Not set | If you just want to use OpenAI you don't need to pass this variable. If, however, you want to use some other openai compatible API (e.g. azure openai service), set this to the url of the API. | | ||
| | OLLAMA_BASE_URL | No | Not set | If you want to use ollama for local inference, set the address of ollama API here. | | ||
| | INFERENCE_TEXT_MODEL | No | gpt-3.5-turbo-0125 | The model to use for text inference. You'll need to change this to some other model if you're using ollama. | | ||
| | INFERENCE_IMAGE_MODEL | No | gpt-4o-2024-05-13 | The model to use for image inference. You'll need to change this to some other model if you're using ollama and that model needs to support vision APIs (e.g. llava). | | ||
| | INFERENCE_LANG | No | english | The language in which the tags will be generated. | | ||
|
|
||
| ## Crawler Configs | ||
|
|
||
| | Name | Required | Default | Description | | ||
| | ----------------------------- | -------- | ------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | ||
| | CRAWLER_NUM_WORKERS | No | 1 | Number of allowed concurrent crawling jobs. By default, we're only doing one crawling request at a time to avoid consuming a lot of resources. | | ||
| | BROWSER_WEB_URL | No | Not set | The browser's http debugging address. The worker will talk to this endpoint to resolve the debugging console's websocket address. If you already have the websocket address, use `BROWSER_WEBSOCKET_URL` instead. If neither `BROWSER_WEB_URL` nor `BROWSER_WEBSOCKET_URL` are set, the worker will launch its own browser instance (assuming it has access to the chrome binary). | | ||
| | BROWSER_WEBSOCKET_URL | No | Not set | The websocket address of browser's debugging console. If you want to use [browserless](https://browserless.io), use their websocket address here. If neither `BROWSER_WEB_URL` nor `BROWSER_WEBSOCKET_URL` are set, the worker will launch its own browser instance (assuming it has access to the chrome binary). | | ||
| | BROWSER_CONNECT_ONDEMAND | No | false | If set to false, the crawler will proactively connect to the browser instance and always maintain an active connection. If set to true, the browser will be launched on demand only whenever a crawling is requested. Set to true if you're using a service that provides you with browser instances on demand. | | ||
| | CRAWLER_DOWNLOAD_BANNER_IMAGE | No | true | Whether to cache the banner image used in the cards locally or fetch it each time directly from the website. Caching it consumes more storage space, but is more resilient against link rot and rate limits from websites. | | ||
| | CRAWLER_STORE_SCREENSHOT | No | true | Whether to store a screenshot from the crawled website or not. Screenshots act as a fallback for when we fail to extract an image from a website. You can also view the stored screenshots for any link. | | ||
| | CRAWLER_FULL_PAGE_SCREENSHOT | No | false | Whether to store a screenshot of the full page or not. Disabled by default, as it can lead to much higher disk usage. If disabled, the screenshot will only include the visible part of the page | | ||
| | CRAWLER_FULL_PAGE_ARCHIVE | No | false | Whether to store a full local copy of the page or not. Disabled by default, as it can lead to much higher disk usage. If disabled, only the readable text of the page is archived. | | ||
| | CRAWLER_JOB_TIMEOUT_SEC | No | 60 | How long to wait for the crawler job to finish before timing out. If you have a slow internet connection or a low powered device, you might want to bump this up a bit | | ||
| | CRAWLER_NAVIGATE_TIMEOUT_SEC | No | 30 | How long to spend navigating to the page (along with its redirects). Increase this if you have a slow internet connection | |
Oops, something went wrong.