A collection of sources of documentation, and field best practices, to build and run a SOC (including CSIRT).
Those are my view, based on my own experience as SOC/CSIRT analyst and team manager, as well as well-known papers. Focus is more on SOC than on CERT/CSIRT.
NB: Generally speaking, SOC here refers to detection activity, and CERT/CSIRT to incident response activity. CERT is a well-known (formerly) US trademark, run by CERT-CC, but I prefer the term CSIRT.
- Must read
- Fundamental concepts
- Mission-critical means (tools/sensors)
- SOAR
- IT/security Watch
- Detection engineering
- Threat intelligence
- Management
- HR and training
- IT achitecture
- To go further (next steps)
- Appendix
- LetsDefend SOC analyst interview questions
- NIST, Cybersecurity framework
- FIRST, Building a SOC
- NCSC, Building a SOC
- MITRE, 11 strategies for a world-class SOC (or use local file): part 0 (Fundamentals).
- FIRST, CERT-in-a-box
- FIRST, CSIRT Services Framework
- ENISA, Good practice for incident management
- NIST, SP800-86, integration forensics techniques into IR
- ENISA, How to set-up a CSIRT and SOC
- NIST, SP800-61 rev2, incident handling guide
- MITRE, ATT&CK: Getting started
- Purp1eW0lf, Blue Team Notes
- ThreatConnect, SIRP / SOA / TIP benefits
- Gartner, Market Guide for Security Orchestration, Automation and Response Solutions
- Orange Cyberdefense, Feedback regarding experience with SOAR in 2020 (in French)
- Soufiane Tahiri, Playbook for ransomware incident response (in French)
- FIRST, CVSS v3.1 specs
- OASIS Open, STIX
- FIRST, TLP (intelligence sharing and confidentiality)
- CIS, 8 critical security controls
- Gartner, Cybersecurity business value benchmark
See: SOC/CSIRT Basic and fundamental concepts.
Quoted from this article:

Following the arrows, we go from log data sources to data management layer, to then data enrichment layer (where detection happens), to end-up in behavior analytics or at user interaction layer (alerts, threat hunting...). All of that being enabled and supported by automation.
As per CYRAIL's paper here is an example of architecture of detection (SIEM, SIRP, TIP interconnections) and workflow:

- Tier 1 & 2 do not mean anything in particular, in the context of this GitHub repo.
- Tier 1 sources are likely to be: audit logs, security sensors (antimalware, FW, NIDS, proxies, EDR, NDR, CASB, honeypot...).
- SIEM:
- See Gartner magic quadrant
- My recommendations: Splunk, Elastic
- SIRP:
- e.g.: IBM Resilient, TheHive, SwimLane
- SOA:
- My recommendations: IBM Resilient, SwimLane, TheHive, PAN Cortex XSOAR
- TIP:
- Antimalware:
- See Gartner magic quadrant
- My recommendations: Microsoft Defender, ESET Nod32, BitDefender.
- Endpoint Detection and Response:
- See Gartner magic quadrant
- My recommendations: SentinelOne, Microsoft Defender for Endpoint, Harfanglab, ESET XDR, CrowdStrike Falcon EDR, Tanium.
- Secure Email Gateway (SEG):
- See Gartner reviews and ratings
- My recommendations: Microsoft Defender for Office365, ProofPoint, Mimecast
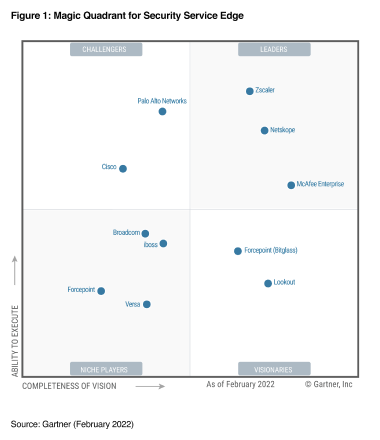
- Secure Web Gateway (SWG) / Security Service Edge:
- see Gartner magic quadrant
- My recommendations: BlueCoat, CISCO, Zscaler, Netskope.
- AD security (audit logs, or specific security monitoring solutions):
- My recommendations: Semperis or PingCastle
- ASM: Asset Security Monitoring / Attack Surface Management:
- My recommendations: Intrinsec (in French), Mandiant
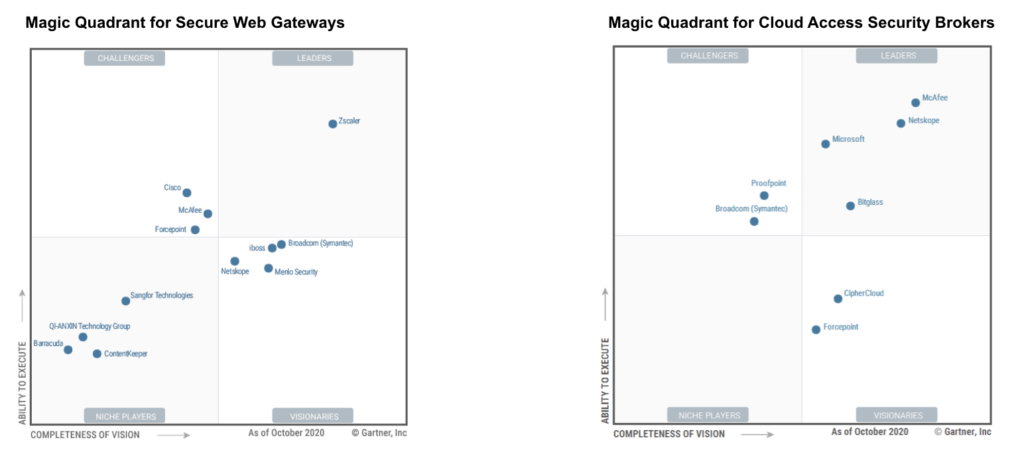
- CASB: Cloud Access Security Broker, if company's IT environment uses a lot of external services like SaaS/IaaS:
- See Gartner magic quadrant
- My recommendations: Microsoft MCAS, Zscaler, Netskope.
- Deceptive technology:
- My recomendation: implement AD decoy acounts
{kind=link}
{kind=link}
{kind=link}
- On-demand volatile data collection tool:
- My recommendations: VARC, DFIR-ORC, FireEye Redline, ESET Sysinspector.
- Remote action capable tools (ie.: remote shell or equivalent):
- My recommendations: CIMSweep, Velociraptor, CrowdStrike Falcon Toolkit but it relies on CrowdStrike EDR, GRR but it needs an agent to be installed.
- On-demand sandbox:
- My recommendations for online ones: Joe's sandbox, Hybrid Analysis, etc;
- My recommendation for local one: Windows 10 native Sandbox, with automation.
- Forensics and reverse-engineering tools suite:
- My recommendations: SIFT Workstation, or Tsurugi
- My recommendation for reverse engineering and malware analysis, under Windows: FireEye Flare-VM
- My recommendation for pure malware analysis, under Linux: Remnux
- Incident tracker:
- My recommendation: Timesketch
- Scanners:
- IOC scanners:
- Offline antimalware scanners:
- My recommendation: Windows Defender Offline, ESET SysRecue
- IOC repos for scanners:
- Google CTI's repo: Yara rules for Cobalt Strike and others.
- Yara-rules GitHub repo: multiple Yara rules types.
- Spectre Yara rules repo
- Neo23x0 Community Yara rules
- and those listed here, Awesome threat intel
- Internal ticketing system (NB: not SIRP, not for incident response!):
- My recommendation: GitLab
- Knowledge sharing and management tool:
- My recommendations: Microsoft SharePoint, Wiki (choose the one you prefer, or use GitLab as a Wiki).
As per Gartner definition:

Hence 3 critical tools (see above): SIRP, TIP, SOA, on top of SIEM.
And in my view, SOAR is more an approach, a vision, based on technology and processes, than a technology or tool per say.
-
Online automated hash checker (script):
-
Online URL automated analysis:
- my recommendation: CyberGordon, URLScan.io
-
Online automated sample analyzer:
- my recommendation, via script and without sample submission: Malwoverview;
- my recommendations for online dynamic analysis: Hybrid-Analysis, Joe's sandbox
-
(pure) Windows tasks automation:
- My recommendations: AutoIT, Chocolatey
-
SaaS-based (and partly free, for basic stuff) SOA:
Try to implement at least the following automations, leveraging the SOA/SIRP/TIP/SIEM capabilities:
- Make sure all the context from any alert is being automatically transfered to the SIRP ticket, with a link to the SIEM alert(s) in case of.
- Leverage API (through SOA) if needed to retrieve the missing context info, when using built-in integrations.
- Automatically query the TIP for any artefacts or even IOC that is associated to a SIRP ticket.
- Automatically retrieve the history of antimalware detections for an user and/or endpoint, that is associated to a SIRP ticket.
- Automatically retrieve the history of SIEM detections for an user and/or endpoint, that is associated to a SIRP ticket.
- Automatically retrieve the history of SIRP tickets for an user and/or endpoint, that is associated to a new SIRP ticket.
- Automatically query AD or the assets management solution, for artefact anrichment (user, endpoint, IP, application, etc.).
- Block an IP on all firewalls (including VPN), SWG and CASB.
- Block an URL on SWG.
- Block an email address (sender) on SEG.
- Block an exe file (by hash) on endpoints (leveraging antimalware/EDR or AppLocker).
- Block an exe file (by hash) on gateways and CASB: SWG, SEG, CASB.
- Reset an AD account password.
- Disable an AD account (both user and computer, since computer account disabling will block authentication with any AD account on the endpoint, thus preventing from lateral movement or priv escalation).
- Report a (undetected) sample to security vendors, via email. Here are a few addresses, in case of:
- Files samples (to be attached in a password-protected Zip file, with 'infected' as password): samples@eset.com, newvirus@kaspersky.com, report@sentinelone.com, virus_submission@bitdefender.com, vsamples@f-secure.com, virus_malware@avira.com, submitvirus@fortinet.com, virus_research@avertlabs.com, virus_doctor@trendmicro.com
- URL/IP samples: samples@eset.com, samples@kaspersky.com, report@sentinelone.com, virus_submission@bitdefender.com, vsamples@f-secure.com, phish@office365.microsoft.com, report@openphish.com, reportphishing@apple.com, abuse@clean-mx.de, datasubmission@mcafee.com
- Report a false positive to security vendors, via email;
- You may want to have a look at this page to know the required email address.
- Report a malicious URL (for instance, phishing) to a security vendor for takedown steps
- My recommendation: Netcraft via API, or PhishReport.
- SIEM rules publications:
- Known exploited vulnerabilities:
- LinkedIn / Twitter:
- RSS reader/portal:
- e.g.: Netvibes
- Government CERT, industry sector related CERT...
- Other interesting websites:
- e.g.: ISC, ENISA, ThreatPost ...
Cf. detection engineering page.
Cf. management page.
- BlueTeamLabs (level 1 & 2)
- SANS 555: SIEM with tactical analytics
- SANS SEC450: Blue Team Fundamentals: Security Operations and Analysis
- OSDA SOC-200
- SOC & SIEM Security program: L1, L2, L3
- Splunk Core User
- Microsoft Cybersecurity Architect
- AWS Security Fundamentals
- CEH
- ENISA trainings
- FIRST trainings
- Malware Traffic Analysis
- Become a Microsoft Sentinel Ninja
- A. Borges, MAS series
- Hack The Box
- SANS FOR572: Advanced Network Forensics: Threat Hunting, Analysis, and Incident Response
- Splunk Core User
- GCIH
- SANS FOR508: Advanced Incident Response, Threat Hunting, and Digital Forensics
- SANS 555: SIEM with tactical analytics
As per NCSC website:
Indications of an attack will rarely be isolated events on a single system component or system. So, where possible, having a single platform where analysts have the ability to see and query log data from all of your onboarded systems is invaluable. Having access to the log data from multiple (or all) components, will enable analysts to look for evidence of attack across an estate and create detection use-cases that utilise a multitude of sources. By creating temporal (actions over a period of time) and spatial (actions across the estate) use-cases, an organisation is better prepared to address cyber security attacks that occur system wide.
The goal is to prevent an attacker from achieving lateral movement from a compromised monitored zone, to the SOC/CSIRT work zone.
-
Implement SOC enclave (with network isolation), as per MITRE paper drawing:

-
Only log collectors and WEF should be authorized to send data to the SOC/CSIRT enclave. Whenever possible, the SOC tools pull the data from the monitored environment, and not the contrary.
SOC’s assets should be part of a separate restricted AD forest, to allow AD isolation with the rest of the monitored AD domains.
- SOC/CSIRT's endpoints should be hardened with relevant guidelines;
- My recommendations: CIS benchmarks, Microsoft Security Compliance Toolkit
- MITRE, 11 strategies for a world-class SOC (remaining of PDF)
- CISA, Cyber Defense Incident Responder role
- FireEye, Purple Team Assessment
- Kaspersky, AV / EP / EPP / EDR / XDR
- Wavestone, Security bastion (PAM) and Active Directory tiering mode: how to reconcile the two paradigms?
- MalAPI, list of Windows API and their potential use in offensive security
- FireEye, OpenIOC format
- Herman Slatman, Awesome Threat Intel
- Microsoft, SOC/IR hierarchy of needs
- Betaalvereniging, TaHiTI (threat hunting methodology)
- ANSSI (FR), EBIOS RM methodology
- GMU, Improving Social Maturity of Cybersecurity Incident Response Teams
- J0hnbX, RedTeam resources
- Fabacab, Awesome CyberSecurity BlueTeam.
- Microsoft, Windows 10 and Windows Server 2016 security auditing and monitoring reference.
- iDNA, how to mange FP in a SOC?, in FR.
- NIST, SP800-53 rev5 (Security and Privacy Controls for Information Systems and Organizations)
- Amazon, AWS Security Fundamentals
- Microsoft, PAW Microsoft
- CIS, Business Impact Assessment
- Abdessabour Boukari, RACI template (in French)
- Trellix, XDR Gartner market guide
- Elastic, BEATS agents
- V1D1AN's Drawing: architecture of detection,
- RFC2350 (CERT description)
- Awesome Security Resources
- Incident Response & Computer Forensics, 3rd ed
- GDPR cybersecurity implications (in French)
- SANS SOC survey 2022
- Soufiane Tahiri, Digital Forensocs Incident Response Git
- Austin Songer
- (full featured) Honeypot:
- My recommendation: Canary.tools
- Phishing and brand infringement protection (domain names):
- NDR:
- My recommendation: Gatewatcher
- MDM:
- My recommendation: Microsoft Intune
- DLP:
- Network TAP:
- My recommendation: Gigamon
-
Define SOC priorities, with feared events and offensive scenarios (TTP) to be monitored, as per risk analysis results.
- My recommendation: leverage EBIOS RM methodology (see above).
-
Leverage machine learning, wherever it can be relevant in terms of good ratio false positives / real positives.
- My recommendation: be careful, try not to saturate SOC consoles with FP.
-
Make sure to follow the 11 strategies for a (world class) SOC, as per MITRE paper (see Must Read).
-
Publish your RFC2350, declaring what your CERT is (see "Nice to read" above)
- Implement hardening measures on SOC workstations, servers, and IT services that are used (if possible).
- Put the SOC assets in a separate AD forest, as forest is the AD security boundary, for isolation purposes, in case of a global enterprise's IT compromise
- Create/provide a disaster recovery plan for the SOC assets and resources.
- Implement admin bastions and silo to administrate the SOC env (equipments, servers, endpoints):
- My advice: consider the SOC environment as to be administrated by Tier 1, if possible with a dedicated admin bastion. Here is a generic drawing from Wavestone's article (see Must read references):

- Recommended technology choices: Wallix PAM
- My advice: consider the SOC environment as to be administrated by Tier 1, if possible with a dedicated admin bastion. Here is a generic drawing from Wavestone's article (see Must read references):
Yann F., Wojtek S., Nicolas R., Clément G., Alexandre C., Jean B., Frédérique B., Pierre d'H., Julien C., Hamdi C., Fabien L., Michel de C., Gilles B., Olivier R., Jean-François L., Fabrice M., Pascal R., Florian S., Maxime P., Pascal L., Jérémy d'A., Olivier C. x2, David G., Guillaume D., Patrick C., Lesley K., Gérald G., Jean-Baptiste V., Antoine C. ...