Merging priorities #1026
Comments
|
I agree with this. As Martin alludes, the server has de facto power to do whatever it wants. It's not necessary to spec anything beyond that. Further, I think the specific proposal is a mistake at a technical level. Expanding on that: IIUC, the design is largely motivated by the work behind this blog post, which argues that current browsers either don't use H2 priorities or use suboptimal priorities, therefore CloudFlare gets benefit from server-driven priorities. But as that blog post observes, Chrome's priorities are almost optimal. The only problem is that images are serialized, rather than concurrent, and this happens because H2 does not allow constructing the optimal schedule with concurrent images. This is fixed by the new priority scheme. I fully expect that Chrome and other browsers will use the optimal schedule for H3 ... at which point, what is the server going to do? Here's a more concrete problem. Suppose a web site uses the same image in two contexts: as the main image of an article, and as a thumbnail image in a list of related articles. In the first context, the image is prominently above-the-fold and should have high priority. In the second context, the image is below the main content and should have low priority. The browser knows this and can prioritize the image accordingly. But how will the server know this? The server sees one request at a time. Given a request for the image, in isolation, it cannot distinguish these two cases. There are other examples like this, such a script that is sync in one context and async/defer in another context, or a stylesheet that is used by the main frame in one context and an iframe in another context. In general, it appears that the client has strictly more information than the server and thus can do a strictly better job generating priorities. Mixing client and server-generated priorities might be a good idea, but it appears to be a research problem. IMO, even setting aside Martin's concern, this idea is not mature enough to be accepted by this working group. |
|
I think there are two aspects to Martin's issue:
@tombergan thanks for the examples. Similar edge cases have come up in design team discussions. Some possible ways to address these are:
Furthermore, we have examples where the server has strictly more information than the client (e.g. progressive images) and can provide information that a gateway can use to improve performance. Writing that as an extension is possible with today's model. I think it is important to agree whether the WG believes in keeping the model of collaboration in scope, even if we can't solve all problems in the initial document. Removal of collaboration would push us closer to the HTTP/2 client-only priorities, which has impact on the headers vs frames discussion. |
Fetch metadata is shipping in Chrome (and likely to be the same for many Chromium browsers). The
Beyond destination and in/out of viewport info, there are other considerations that the server may or may not be aware of. And both clients and servers can use e.g. RUM data to deduce long blocking dependency chains, and upgrade relevant resources' priority, beyond the simple rules of "a blocking script has priority X". All that to say that when servers are merging priorities, they need to take caution when overriding the client's prioritization, and need to do that only when certain that they know better. |
TIL. thanks!
I think we can all agree there are many variables that can play into prioritization. That is maybe part of the answer as to @tombergan's question on #1023 (comment)
Describing the client's usage intent and environment with a richer vocabulary, rather than an integer space, makes it possible for a server to make better prioritization decisions - independent of any origin that adds more information (i.e. the problems are tangential). So Yoav's suggestion is sound advice for a server that makes any active choice about prioritization. |
I strongly believe that client/server collaboration should be out-of-scope:
I don't believe that client/server collaboration is a bad idea, only that the idea is too complex and too immature to justify its inclusion at this time. Also, there may be better ways to encourage client/server collaboration. One idea is to invert the relationship: send context from server -> client, instead of client -> server. For example, the server might communicate extra priority hints via new attributes in |
We (Cloudflare) have experience with using response headers to adjust resource sending of progressive images in order to improve performance. This is detailed in the blog post https://blog.cloudflare.com/parallel-streaming-of-progressive-images/. The
Sending information to the client might allow it to then reprioritize the request based on new information. The problem is that the extra RTT's imposed on that interaction can negate the benefits of doing it. |
I like this idea but I believe it can be implemented without any of the machinery to merge priorities. The client can send priorities however it wants. Suppose the priorities are: urgency=1, incremental=false: a.css Suppose also that the server knows that each image can be rendered progressively. The server SHOULD deliver Since the CloudFlare frontend doesn't know how to split those images into parts, you still need a way to learn the splitting from the backend, but that communication is outside the scope of this spec IMO.
If the information is sent in the HTML or DOM, as it would be with |
The design as it stands reserves urgency 2 for the server, so lets shift them for the purpose of discussion. I'm assuming urgency=1, incremental=false: a.css
A different approach that a server could take would be to promote the urgency of
I appreciate the point. However, I think that while we are considering new semantics for prioritization, there is value in creating a common format for the signals. The alternative IMO is that server-to-frontend signals become bespoke (e.g.
I don't follow sorry. In the case of the blog, the frontend prioritizes byte ranges of different responses. The bytes depends on the selected representation (i.e. content-encoding etc) so I don't know how one would be able to encapsulate that information in HTML or DOM. |
Why would the server do that? The client has expressed that b is more important than both c and d. Perhaps c and d are below-the-fold. If the server understands the optimal priorities that much better than the client, then the server should ignore what the client says (and therefore ignore this spec entirely) and do whatever it wants.
Sorry for the confusion. I agree the client doesn't know how the images are encoded and would have trouble communicating exactly how image bytes should be scheduled. However, I believe the progressive image optimization can be implemented without any cooperation from the client, except that the client should request images with incremental=true. Once the server is given those incremental buckets, all of the progressive image scheduling magic is contained on the server, within those buckets. In the example above, the server would send the entire response for image b before sending any bytes for c or d. (After all, this is what the client asked for.) After sending b, the server would send the image headers for c and d, then the initial previews, then the final bytes. When I said "if the information is sent in the HTML or DOM", I was referring to scheduling decisions like "image A is more important than image B". I had assumed that you wanted the server to make decisions like that. I think that's a fine thing to do -- maybe the browser has a difficult time finding above-the-fold images, whereas for some web site, the server knows exactly which images are above-the-fold. My point was: that kind of priority information can be communicated in the HTML, perhaps using markup like [1] not a serious proposal |
The client only has a partial world view, which it is basing it's initial priority signal on. Once the request is received and the server selects the representation, this new information might lead to a change of mind. In my strawman example, there could be benefit in sending some or all requested image headers, even images below-the-fold. Or perhaps that's an awful thing to do. The point is that today it's hard to test tuning the effect of priorities. H2's prioritization scheduling is a bit of a black box in many implementations. Server-side applications get limited knowledge of what the client signalled, and limited input into the scheduling of response bytes. They do get some control-by-proxy via starving or feeding response data into the scheduler, but that's nasty. Or perhaps there is some proprietary API. I see merit in defining a more standardised priority scheme that can be used for the purpose of providing input to the scheduler from the requestor's and respondor's perspective. Others might disagree, or might disagree with peers being able to see what priority hands were played. While your proposal might not be serious, it does closely resemble the Priority Hints API which defines high, low and auto. [1] @yoavweiss can talk more to both the spec and the experimental data. 1 - https://github.com/WICG/priority-hints Edited: to remove copy editing artefacts. Apologies to your inbox. |
This is the core of my disagreement. AFAICT, we don't have evidence that merging client and server priorities is required for optimal performance. We have some intuition that it may be useful in some cases, and that's about it. This reminds me of old H2 conversations in the ietf-http-wg archives, where people expressed an intuition that we needed priority groups or trees to support proxies, so we ended up with trees, but no one ran any large scale tests first to verify that trees were a good idea, and now H2 has a prioritization scheme that no one likes. I would like to avoid making that mistake again. I fully support experimentation, but I don't support adding experimental features to this spec. I also support browser-side experimentation, and by using fixed and inflexible semantics for each priority level, this spec potentially limits browser-side experimentation (see #1023). I believe it's sufficient to say: there are N urgency levels, of unspecified meaning, that the server is free to ignore client priorities if it chooses. Even with this simple specification, it is possible to test merging client and server priorities. For any given User-Agent, such as Chrome/79, the meaning of any urgency level X is baked into the binary. The server can run any experiment it likes, with the caveat that it may need to adjust the experiment based on User-Agent, which seems reasonable? |
|
I agree with some of you points around evidence. However, one difference this time around are that we have wider experience with client and server implementations of multiplexed prioritised requests. And the ways that servers succeeded or failed to implement response data schedules. We maybe agree that the ability to experiment was hampered by the complexity of the tree-scheme. A simpler scheme could allow for data gathering without introducing normative text in the spec. One way to answer the merging question is as MT suggested in his OP. And that could be taken further by So not reserving urgency levels that the client cannot use. I would push back against the idea of a wide range of free form priority values. It makes the servers job incredibly difficult, especially if it introduces requirements (normative or not) to user agent sniff. Kazuho and I have experience with the fragility of sniffing for the tree-based scheme today. |
|
What @LPardue said, mostly. My experience from other areas suggests that 4 levels is something of an optimum for signaling priorities. For instance, in WebRTC we had a taxonomy that roughly equated to "audio, video, chat, files". Implementing even that few levels can be interesting, but it is workable. Double that and it probably isn't much worse. Iterating over 8 queues is workable, for instance. But multiply too much and you will have to find ways to reduce it to something you can manage. Once everyone has performed similar (but likely different) reductions, the additional bits you spent on signaling aren't helping. Obviously, any expectation we might have about consistent treatment from servers is a fantasy. Once we allow for the server to have any input, we leave this open to non-determinism. But the advantage of a header field is that you see what contributed to that. If you have a gateway that follows server overrides, then the client will be able to observe those unless the gateway erases them (it shouldn't). Then at least we have hope of identifying the source of performance bugs. |
|
There are three relevant issues:
I think @martinthomson's last message focused on (1). Let's ignore that for a moment and assume we've agreed on a fixed number N. On (2) and (3), my opinion is:
Is there any disagreement on those points? |
|
For the record, I agree with @tombergan on all 3 points if that weren't already clear. Thanks for trying to bring this back to something more concrete. |
|
@tombergan Thank you for summarizing the points. It's good to know that we are converging on 8 urgency levels (or something minimum). At the same time, I still think that we should have semantics, and that we should allow servers to merge priorities. In #1023 (comment), @martinthomson has laid down the reasons why he does not favor that. Quote:
I do not fully agree with the observation, and I disagree with the rationale. My observation is that, as stated in #1023 (comment), status quo provides enough freedom to the clients. We have three supplementary levels that can be utilized. We also allow the client to promote (or demote) urgency between prerequisite / document / supplementary / background. While it is true that having the semantics reduces the amount of freedom the client has, I'd assume that it would be enough. But moreover, I would argue against placing the ability "to apply a different strategy" above allowing servers to tweak priorities. As @LPardue points out, multiple servers already tweak priorities because doing so has benefits, and the headache is that it's difficult to do so in a stable and cross-browser manner due to lack of semantics in H2 priorities. It's a real problem. Compared to that, as nice as it would be to provide freedom for applying different strategies, it's just a possibility. That's not a problem that we have now. Based on our experience in H2, I am also doubtful if we would ever come up with something very different for the web browsing case. I would very much prefer fixing the issues we have now, rather than prioritizing something that we might do. |
I addressed this in my first comment in the thread, and again in this comment about progressive images. I agree that browsers are doing a suboptimal job with H2 priorities, but that happens due to problems in H2 that are fixed by this spec. I have not seen any evidence that servers will need to tweak priorities after this spec is widely implemented. There are guesses that servers might want to tweak priorities in some cases, but IMO that's not a strong enough argument to support the complexity this adds to the spec. And further, I believe there are better ways for servers to tweak priorities that don't require any spec support here.
I completely agree with this. |
|
I'm happy with saying less in the spec but want to ensure it doesn't inadvertently prevent the ability for non-client actors to provide their signals into a server that is scheduling the responses. |
I think this is what we disagree. The limitation of browser-driven prioritization is that it cannot be specific to websites, while server-driven prioritization is mostly an attempt to provide further optimization based on knowledge specific to the website (e.g., promote urgency of hero images, tweak priority based on the knowledge of the file type). Therefore, we would continue to see benefit in having a server-sent signal, and using it. There are two ways of implementing such signal. One is by associating priority to the initiators of the requests (e.g., priority hints) as you correctly point out, and the other is by sending signal from the server (most likely as a response header). I would not go into the details, but there are pros and cons in these two approaches. That said, for both of these two approaches, it is beneficial to have semantics. Otherwise, you cannot use either of them, unless you specify the priority of all the resources that are used. To summarize, server-sent signal will continue be useful, and for that to be useful, we need semantics. |
|
Can you share a link to a study showing that (a) server-driven prioritization will be useful with this new priority spec, and (b) server priorities will need to be merged with client priorities as described in this proposed spec? Over in #1023, I hypothesized that more than 8 priority levels will be useful because some optimizations, like deprioritizing iframes and background tabs, might benefit from 2x as many levels. I admit this is a pretty weak argument. I don't have any data to support this idea, and specifically I don't have any data which shows that 2x as many levels are necessary. Thus it seems safer to stick with 8 levels since that makes O(1) implementations easier. We're in the same situation here. I haven't seen an argument for why we need all of this complexity, besides a hypothesis that it might be useful someday. |
|
Are you able to elaborate on where you see the complexity if we were to adopt Martin's suggestions? Since H2 priorites were only ever a hint into the process, I presume you don't see complexity in servers having unilateral override. So is this concern about having to define rules about carriage of a prioirty signal on the non-client-facing side? Or something else? |
Can you clarify which suggestions you're referring to: are they these, which Martin agreed with, or something else?
That's correct.
If you're referring to Section 6, then yes, that is half of it. The other half is: in order to spec how servers merge priorities, we need to carefully define how browsers will attach priorities to requests. This is Section 3. It is essentially saying: for all time, browsers should use 3 for ATF images, 4 for BTF images, 5 for async JS, etc. If clients ignore Section 3, then Section 6 is broken. If clients follow Section 3 religiously, then client-side experimentation is effectively disallowed, and any problems in Section 3 must necessarily be fixed at the server, even if it would be more efficient to fix those problems on the client. Also see Martin's comment here. I still propose deleting Sections 3 and 6. Can you share any data that would convince me otherwise? |
Removing section 6 is tenable but I would be inclined to write some short prose to make it clear that signals can come from both client and server roles (local or remote), and that no requirements are made on how implementations consume and act on those signals. Adding extension parameters to either signal is compatible with the above. Although they may find, with evidence, that defining additional requirements is desirable or necessary. I would like to gather data with respect to the progressive image loading extension we have in mind, but can not share timelines on when that would be available.
It is my view that having a common understanding of semantics empowers a priority scheduler to make trade-offs. Having abstract weight levels might give more freedom to browsers (although arguably they never exercised this freedom with H2) but reduces the server to being just a dumb ordered-list processor. Therefore to address your proposal, I don't think deleting section 3 entirely is advisable; but iterating on section 3.1 is something we should do. Since deletion would be a design change of the adopted document, I don't agree there is a burden of evidence to validate its existence. Client experimentation away from the urgency/progressive scheme here implies some alternate strategies are desired - which may simply be incompatible with the model of prioritisation in this document. That seems an ideal opportunity for extension or substitution i.e. don't reuse urgency parameters, define new ones. |
That's not accurate. You could examine the WebKit's resource prioritization vs. Chromium's for an example to the contrary. Chromium's resource priorities started out very similar to WebKit's, but over the years evolved to have more complex priorities:
All that is before we're talking about low-bandwidth interventions, and applying different priorities to main frame and subframe resources... So, browsers have experimented with resource priorities, and are likely to continue to do so in the future. |
|
Interesting. Does that apply to the values sent on the wire to H2 endpoints and solely the transfer of response payload, or does it play into client implementation detail too? Is there data on the effectiveness of evolving prioritisation instanciation in a world of servers that vary in priority implementation quality? |
|
It can definitely apply to both. @tarunban may have more details on data from past changes |
|
I talked with @tarunban. Here's a summary: In Chromium, each request is assigned a priority (see Yoav's link) which is respected by task schedulers throughout the browser (well, not every task scheduler, but at least conceptually that is the goal). When a request hits the network stack, it gets throttled if it has a relatively "low" priority. This is necessary on H1 where there's no response prioritization on the server, but it also happens on H2/H3 for a variety of reasons, such as the fact that pages often load third-party resources over different connections which can't share H2/H3 priorities. On H2, just before the request is sent out, its Chromium priority is translated to an H2 priority. The same happens for H3/QUIC. Requests may be reprioritized. For example, when the user scrolls an image into the viewport, that image's priority is increased. When a request's priority changes, we send an updated H2 PRIORITY frame. Note that Section 3 will force browsers to use the same resource priority assignments for all time. @tarunban echoed concerns from myself and others that this is a bad idea for browsers over the long term. As Yoav alluded, we are actively investigating new ideas, such as deprioritizing resources in iframes.
We have lots of data on prioritization changes generally speaking, but we can't give a concrete answer to this question. We have data which shows that throttling H2 requests at the browser speeds up page loads. While this is likely a sign of poor H2 priority implementations in servers, we can't say how much that contributes. We also have data which shows that H2 priorities have zero effect in the wild due to kernel bufferbloat on the server (even with TCP_NOTSENT_LOWAT). Fortunately, bufferbloat is less of a problem with H3/QUIC, where we've seen moderate speedups with priorities -- see "Experimental measurements" in these slides. |
|
The comment above from @tombergan looks good to me. I also wanted to add that browsers may change priority of a resource based on the context. e.g., if two different tabs are loading resources from the same server, then it might make sense to lower the priority of requests from the tabs that are currently in the background. I think it's also preferable for browsers to use the priority consistently throughout the loading lifetime. e.g., resources with low H2/H3 priority should also have a low priority when they hit the cache look-up queue (bug). |
|
Thanks for writing that up, and sharing. I'm getting a better impression of what works for Chrome. But I'm still unsure of a few things, perhaps we can try to distill down some desired requirements. What does experimenting entail for the priority signal, is it just giving some fetches different weights in H2's available space? We've talked about 8 levels as an acceptable compromise for number of priority values. If they had no semantic is that enough? If levels had semantic, and you wanted to try loading a class of resource at "prerequisite" instead of "supplementary" what is the concern? That the server would ignore you? |
|
@tarunban the intent of the H2 priorization tree was to allow grouping for tabs such as you describe. In the discussions we've had through 2019 nobody provided any examples of clients ever having used it that way. Dies chrome do such prioritisation without using trees today? It's foreseeable that this scheme could be extended with a parameter that expresses something like "view=in-focus". Its also feasible that a server could combine the Priority signal with information from Fetch metadata. |
|
@yoavweiss @tombergan @tarunban Thank you for sharing the internals of the client side, as well as describing the potential changes.
I think the paper by @rmarx et.al on https://h3.edm.uhasselt.be and https://blog.cloudflare.com/parallel-streaming-of-progressive-images/ would provide answers. Quoting from the paper, "no single scheme performs well for all types of web pages." The paper then alludes that adopting different schemes based on each website might be a good solution, though we know that that's going to make things complicated. In the mean time, what the server developers are doing is to "refine" client-driven signal using server-side knowledge. The blogpost linked above talks about that, including an automated approach that serves different parts of JPEG images at different priority levels improves user experience. However, to promote (or demote) priority, the server needs to know the semantics. Because otherwise it cannot change the priority to the correct value. Consider the case of promoting a hero image above any other images. How do you tell the correct priority without having the semantics? I continue to think that status-quo likely provides enough freedom for browsers to evolve. It has four semantic levels (prerequisite, document, supplementary, background), with a loosely-defined sub-levels at supplementary. Is it the case that some of the (potential) client-side experiments would not work well with these urgency levels? I'd also argue that we would always be possible to extend the vocabulary, as @LPardue points out in the comment right above. |
I do not think we ever did that experiment. We already do reprioritization of image resources (based on viewport location). We are also actively looking at reprioritization of resources within iframes.
I think the priority hints API might be the right fit here for the server to give a signal to the client on the relative importance of the resource? |
|
Thanks @kazuho for mentioning our paper. I've many thoughts on this, but not a lot of time atm. The main point to me is that users need -some- way of manipulating browser-set priorities, whether it be on the client end (e.g., priority hints, preload) or at the server side (e.g., the current proposal, Cloudflare). Both options are currently not well supported... I asked @yoavweiss and Dom Farolino earlier about priority hints and, despite being around for years and running origin trials, they haven't been activated nor is it clear if they help (at least not outside of google) (https://twitter.com/domfarolino/status/1221803122638508032?s=20). There is, IIUC, also no indication from other browsers to support this (to which I would like to note that a lot of this current discussion is highly Google-driven from the browser side). Even then, they would not allow giving a hard priority, but mainly manipulating the browser's estimate. Other options like preload have had their own problems in the past (e.g., https://andydavies.me/blog/2019/02/12/preloading-fonts-and-the-puzzle-of-priorities/, no FF support). On the server-side then, it's notoriously difficult to inject a resource there due to the instable nature of the trees and because all browsers/clients build different trees. The only real option is to sniff the UA (explicitly or implicitly https://twitter.com/patmeenan/status/1222559418434408450?s=20) and have custom behaviour per-browser. This is for example what Cloudflare is doing for their setup and they are (rightly?) keeping it proprietary, since it represents a significant engineering investment to get that to work. This is not something a typical developer can solve using nginx/apache. So, I believe the current approach is motivated by the fact that it's (currently?) difficult to manipulate resources on the browser end, so let's at least make it simple on the server-side. The counter-argument seems to be: but the browsers will get there -eventually- (the references to priority hints, better preload support, etc. ). So it comes down to if you believe that or not. Similarly to how you claim to have seen no proof that server-side re-prioritization works, I have seen no proof that client-side options will become commonplace soon. As such, my opinion would be: we're now in a place to address this problem in a browser-agnostic way, we should do that. If priority hints ends up supported everywhere: great, more flexibility. With regards to not locking browsers into too rigid a structure and allowing experimentation: I would say something about this, but it would devolve into a rant on how things like the "deprioritizing background tabs" idea was proposed in 2014 (2013? https://tools.ietf.org/html/draft-chan-http2-stream-dependencies-00), influenced the dependency tree complexity, and was subsequently never actually implemented. So I'd rather refrain. |
|
And yet experimentation has happened, even if that particular usage didn't. Perhaps a compromise would be to have the eight priority levels without specified meanings, but provide the mappings as an example a hypothetical browser might employ? Noting, of course, that browsers might find occasion to increase or decrease priority based on other factors, as might servers. |
Abstractly, yes, but H2/H3 are red herrings. Chromium has an internal notion of priority. This internal notion happens to be similar to what is being proposed for H3, but I believe that's an intentional aspect of H3's design more than anything. Developers can (and do) change how Chromium's internal priorities are assigned without directly thinking about the impact on H2/H3. The translation from internal priority to H2/H3 is a separate concern. Internal browser priorities can look completely different. At one time there was a proposal to replace Chromium's priority enum with a dependency graph. This never happened (it turns out DAG-based APIs are hard) but it's a natural thing to try, especially as new features like JS modules make the DAG-based nature of page loads more explicit.
Yes.
My concern is that "prerequisite" and "supplementary" are meaningless terms in isolation. Look at the history of the code in Yoav's link -- Chrome has used 6 levels for a while, but the assignment of requests to levels has changed over time, i.e., the meaning of "prerequisite", "supplementary", etc. has changed. In order for this idea to work, you need to guarantee that every browser will generate the exact same set of priorities for a given page load, otherwise the server might be mistaken about what priority level X means and its priority edits will be wrong. You need to define how requests map to priority levels and browsers must agree to implement that mapping. IMO this will never happen. First, recall that browser-internal priorities are separate from H2/H3 priorities. In order to implement fixed priorities for H3, browsers need to either (a) adopt H3 priorities for their internal representation and add "thou shalt not change this" comments to the methods that assign priorities to requests, or (b) embed enough information into their internal priorities so the net stack can translate to the appropriate H3 priority (in practice the amount of information needed might be large). Note that both options impose implementation constraints across the entire browser, not just the H3 stack. Second, we have at least three main browsers to deal with: Chromium (and Edgium, etc), Firefox, and Safari. I don't know how Firefox's internal priorities work exactly, but you can see from this enum that it's not a simple list of 6 levels (this older figure suggests 5 levels). I don't know what Safari does either. It's based on WebKit, so it probably uses 6 levels like Chromium, but I'm sure it uses those levels differently from Chromium. How will you convince browsers to agree on the same implementation? Third, what happens when a new web feature adds a new flavor of request? Do we need a process for browsers to agree on how to prioritize these new requests? Fourth, recall that the true dependencies form a DAG. The flattening of a DAG into N levels is a heuristic. Like any other heuristic, it might be wrong. It seems short-sighted to enshrine this heuristic into browsers for all time. Fifth, HTTP is not a browser-only protocol. All of these problems can reappear in non-browser contexts.
I think you have misunderstood my comments. This is what I asked:
I want to see evidence of both (a) and (b) together. I already believe servers can have more knowledge than clients in some situations. See Klotski, Polaris, and other academic work. All of this work has a similar flavor: the server takes over the entire loading process for a page and ignores what the browser would have done. My suggested edits to the spec are sufficient to support this use case. This proposal is different: it wants browsers to set priorities in a fixed way so that servers can edit priorities of individual requests. I believe this is a bad idea because servers don't have enough context for individual requests and because getting all browsers to agree on how to set priorities is not going to work (see above). AFAICT, neither of @kazuho's citations address my question. I addressed progressive images in an earlier comment -- I don't see why merging of client and server priorities is necessary to implement progressive image optimizations. I haven't had a chance to read Robin's paper in detail, however, it doesn't seem to be evaluating client/server priority merging; it's evaluating either different priority schemes a browser could use, or something more like Klotski, where the server takes over the entire loading process. |
{kind=link}
|
What I find interesting in this thread is that we are debating about the merits of conveying information about the request intent - specific semantics vs more generic levels. Meanwhile the Fetch Metadata spec is attempting to introduce an HTTP header-based signal that conveys information about the way a request was made and the context in which it will be usedl; all for the purpose of empowering a server to make decisions on how it handles that request. The conjecture about how to handle new web features applies equally to Fetch Metadata. The proprosed semantic is an approximate model that provides a pretty good analogy of how a client uses resources. Some may disagree with that. A server that understands "prerequisite" blocks "supplementary" is empowered to make a judgement call on the tradeoffs when it comes to sheduling resources. If we convert that to levels "0" and "1" with no semantic, then a server can only make a value judgement based on the relative weight. Chrome's internal mappings are an implementation detail, but the outcome is visible to all and is effectively an opaque API. We saw this with other H2 clients, producing different trees with similar goals. Reverse engineering this is possible but it is fragile - there is no contract, and no interoperability forum and no in-band mechanism to describe the intenr. Servers have unilateral control of priority but effectively have no real way to influence that process. Even if priority information is exposed to a server operator, meaningfully using this is a bit of a crapshoot. So typicall server operators leave things up to the server implmentation to handle everything. However, this leads into benfits for clients; a server with deterministic priority scheduling is a control that allows iterative performance improvent. IIUC one concern is that removal of the control factor could reduce this opportunity. The above works pretty well for a lot of web resources. The counter example we keep coming back to is progressive images. In Cloudflare's work, we have shown that not all bytes of a response have equal priority. We can build a delivery schedule based on a set of priority checkpoints on byte boundaries, which serves different regions at different priorities. We can use the client's indicated priority to align these checkpoints to the relative priority of the resource in the connection context - merging. The schedule is carried in a format that the priority scheduler can consume and enact. There has been a suggestion that priority checkpoints could be passed through to the client somehow, but given that the information is representation-specific I see several barriers and think this would fail to be realized. (Aside: I'm remembering a recent discussion about security consideration for ranges that may or may not be a problem here). I think controlling server prioritization behaviour from a non-client signal is possible even if the specification doesn't say anything about merging. Having a constrained number of levels certainly helps this case. If I could have my cake and eat it, I would suggest two modes:
|
|
IIUC, FetchMetadata is intended to improve security and privacy and as such it exposes fairly limited information. A lot of contextual information that will be useful for prioritization will be privacy-sensitive. One example: if the origin does not have scripting permissions, it can't observe scrolling behavior, but scrolling behavior would be leaked by a hypothetical
I'm sorry, I thought I addressed all of these things in detail in my last comment.
In an earlier comment you mentioned that CloudFlare splits images into three parts -- headers, preview, and the rest of the data -- and uses a higher priority for the headers (say 2) compared to the preview and the rest of the image (say 3). It's not clear why you can't do this within one priority level. Say the client requests a few images with priority 3. You can push the headers to the front of the queue within priority 3, then the previews, then handle everything else normally. This doesn't strictly follow what the client asked for, but that's fine, you're doing something better, and it doesn't require any cooperation from the client. |
|
Some of these challenges will continue to exist regardless of what Prioirty levels are defined. The arguments against the scheme are weighted in favour of allowing complex UAs to have a safe freedom to change aspects of its priority model. External contributors pay a non-trivial cost to try and improve on this model. This to me highlights a problem with the applicability of the draft beyond urgency levels, that the extensible priority scheme will never see additional parameters because they leak abstractions. Leaking like this harms the ability for future change. It may also have security, privacy and fingerprinting concerns. My comments on simplicity reflect less complex UAs. Something like (lib)curl could easily synthesize request urgency levels, or pass through user-provided headers. This would avoid curl, or users, needing to define how they use all of the available level space. |
Fetch metadata reflects Fetch related parameters to the server. Those parameters defined in the Fetch spec, and new features that add new requests have to think long and hard about what those parameters should be. Theoretically, the Fetch spec could similarly define strict priority levels, their semantics and what each request destination should set them to. The part that I'm missing is why strict semantics are required in order to perform server side experimentation? Can you describe a scenario where they would differentiate between the server doing the right thing vs. the wrong thing? |
This is a good question given the stage of discussion. Starting with the axiom that the H2 tree allowed a very free form of indicating web priorities. Some server implementers found value in reading meaning into the tree and using that information to experiment. Having that info might not be a strict requirement, but it improves the chances that experiments can operate within some sane bounds. Divining the tree is fragile, and also hard when its empty or broken. A simpler scheme negates some of these problems. It reduces the amount of context needed on the server side and avoids issues caused by H3 delivery ordering. However, it also discards some information that was in the tree such as the exclusive priority relationship. This could help indicate that a resource is blocking in some way and tinkering with its importance is probably going to result in a bad time. OTOH adjusting server behaviour to protect or improve the serving of that blocking resource (I.e. schedule I/O reads from disk, use a fast path to upstream) could make things better. Without the signal we'll never know. A good example of useful information is the incremental (aka concurrency bit). This information allows a server to make a value judgement on how to time slice. The semantic levels indicate blocking and create some guard rails to say "if you push a priority outside here, it's probably not going to achieve a good result in the overall page load". What I'm hearing is that those rails are a hindrance for clients. And just having semantic free levels might be good enough, as long as servers understand which end of the space is high prioirty. There's a lot of mights above because actually being inclined to dig in and build software to do this is hard with thebstatis quo. |
|
OK, that sounds like something completely different from "we need semantic levels for priorities and mapping of the different resources to those". It sounds to me that what you really need are various "what is this resource" indicators. For resources that are streamingly processed, you need the concurrency bit. Some implementations that don't render images progressively may turn it off for images. Some, which streamingly parse multiple scripts at a time, may turn it on for scripts. But you want an indication for that "streaming" quality of the resource, regardless of its urgency. Similarly, it seems like you want an indication that a certain resource is blocking other operations (e.g. a render blocking script or style). That's more closely tied to priority, but maybe can/should be expressed as a separate "blocking" bit that you can use as indication that delaying that resource would result in significant client side delays. I wouldn't object to adding such a "blocking" bit as it seems like something that browsers can strictly define and agree on (i.e. define a Fetch flag that translates to that bit being sent out and properly set that flag in places that call Fetch for those resources) Would that solve your problem? |
|
@yoavweiss for some context, one of the floated ideas initially was to take what you call "what is the resource" indicators further with (very) fine-grained info. That discussion can be found here: kazuho/draft-kazuho-httpbis-priority#28 (though that exact strawman isn't necessarily what I'd champion). This was discussed and determined to be too complex for a first iteration, as we're trying to ship this with/before HTTP/3 is done. That's partly why we stuck with the current setup with "semantic levels", aiming to explore additional indicators/aspects in later iterations (which should be quite easy if we would use HTTP headers). A blocking bit would be helpful and might be a good compromise to explore. |
|
I'm open to options. We had some discussion before but now the document is adopted we have wider input. Maybe older dead ends are more attractive than current ones. I appreciate everyone's patience in talking though this area. |
|
I open to this too, but it would be helpful to see specific examples. What does the "blocking bit" mean (i.e., what specifically is blocking), what are some optimizations the server wants to perform, and why does the presence of this bit prevent the server from making the wrong decision. Although the implementation cost of this is much lower, it is non zero, so if we're going to get buy in from all browsers to actually implement this idea, it will be helpful to point at specific examples of why it is needed. |
|
Some of us gathered during the QUIC Interim this week, and discussed how we can go forward. We considered the following two scenarios specifically, in which mostly client-driven prioritization + server refinement could be helpful:
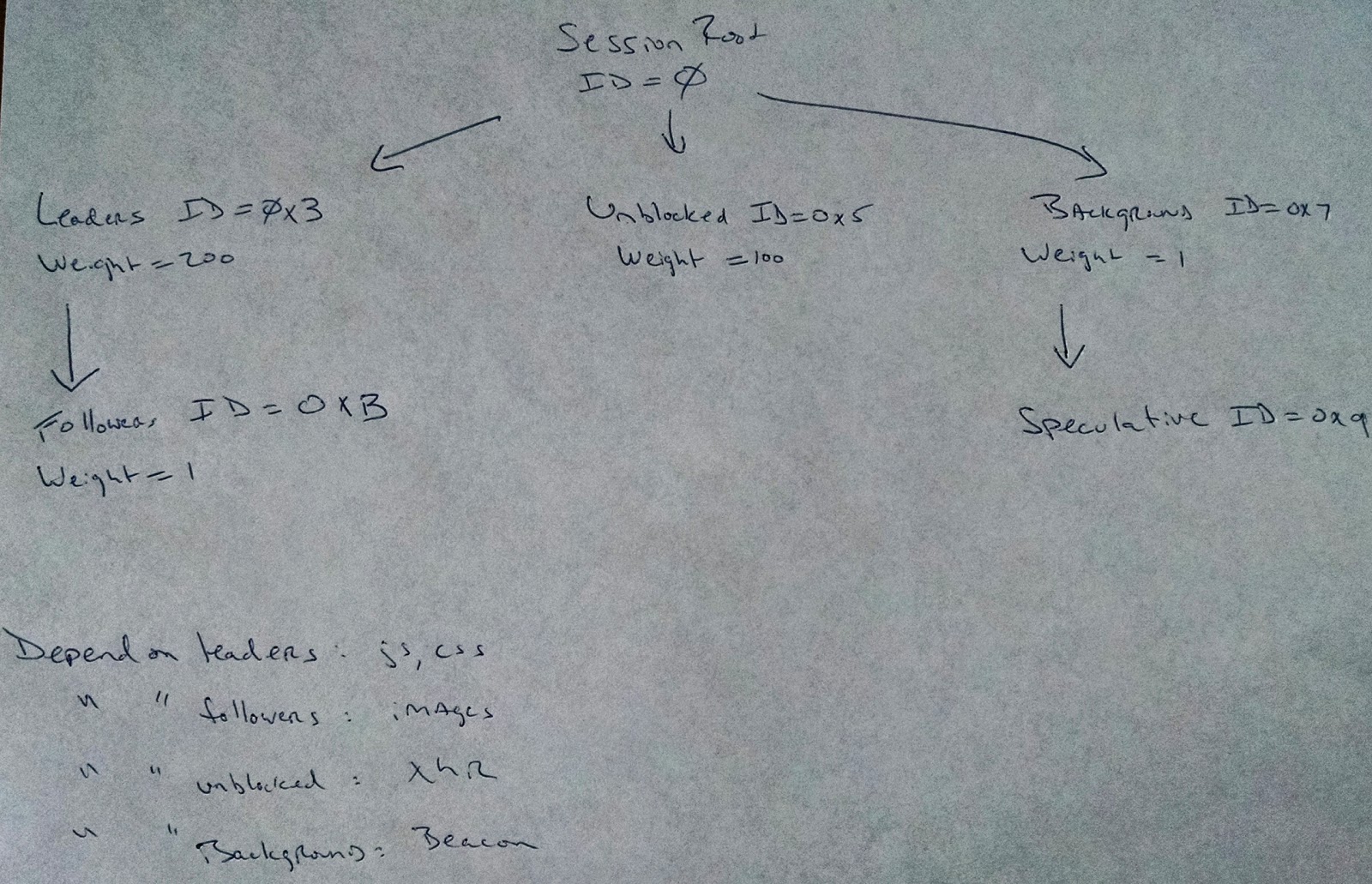
If we are to support these two scenarios, there needs to be a common understanding about where the "default" urgency level is (i.e. the urgency level used for fetching the HTML of the main window), and where the "background" level is. In case of the first scenario, the server would promote the urgency to the "document" level or one above that. In case of the latter, the server would demote the urgency to the level right above "background." Then, we considered if we could support these scenarios at the same time minimizing the restriction to be imposed to the client-side. The rough consensus was that having a common understanding of only two levels: "default" and "background" level could be an acceptable compromise. Based on our previous agreement that having 8 levels of urgency would be sufficient, we chose 7 (the lowest) for background, and 3 (the middle of all levels excluding background) as the default. The outcome is PR #1048. PS. This issue comment is based on my understanding of the discussion. Please correct me if I am wrong. |
|
agreed, lets close this and open new issues for any specific problems with the document. |
The document implies that server priorities override client ones. I think that is a mistake. The current approach seems strongly biased toward the role that a gateway provides.
Both values provide some information and an intermediary can use that information as it chooses. Including advice that suggests the server information might be more complete and thus worthy of greater attention is probably the right way to address this question. I can definitely see gateways throwing out client priorities in favour of server ones, but you don't have to require that.
The text was updated successfully, but these errors were encountered: