ADD S3 support for downloading and uploading processed datasets #1723
Conversation
There was a problem hiding this comment.
Thank you for your help on this :)
I left a few comments.
In particular I think we can make things even simpler by adding a fs parameter to save_to_disk/load_from_disk so that the user can have full control on authentication but also on the type of filesystem they want to use.
I'm not too familiar with moto unfortunately but if you think I can help fixing the tests let me know.
Make it working with Windows style paths.
src/datasets/arrow_dataset.py
Outdated
| dataset_path (``str``): path or s3 uri of the dataset directory where the dataset will be saved to | ||
| aws_profile (:obj:`str`, `optional`, defaults to :obj:``default``): the aws profile used to create the `boto_session` for uploading the data to s3 | ||
| aws_access_key_id (:obj:`str`, `optional`, defaults to :obj:``None``): the aws access key id used to create the `boto_session` for uploading the data to s3 | ||
| aws_secret_access_key (:obj:`str`, `optional`, defaults to :obj:``None``): the aws secret access key used to create the `boto_session` for uploading the data to s3 |
There was a problem hiding this comment.
if we have boto3 as an optional dependency, maybe there's a way to not use those (verbose) params and use like a profile name or something instead? (not sure, just a question)
There was a problem hiding this comment.
As @lhoestq mentioned, we can probably avoid using these params by letting the user provide a custom fs directly. I think this has several advantages (avoid having too many params, lets remove code specific to s3, ..)
There was a problem hiding this comment.
so you would suggest something like that?
import fsspec
s3 = fsspec.filesystem("s3", anon=False, key=aws_access_key_id, secret=aws_secret_access_key)
dataset.save_to_disk('s3://my-s3-bucket-with-region/dataset/train',fs=s3)What I don't like about that is the manual creation, since fsspec is not that well documented for the remote filesystems, e.g. when you want to know which "credentials" you need you to have to go to the s3fs documentation.
what do you think if we remove the named arguments aws_profile... and handle it how fsspec does with an storage_options dict.
dataset.save_to_disk('s3://my-s3-bucket-with-region/dataset/train',
storage_options={
'aws_access_key_id': 123,
'aws_secret_access_key': 123
})There was a problem hiding this comment.
Indeed the docstring of fsspec.filesystem is not ideal:
Signature: fsspec.filesystem(protocol, **storage_options)
Docstring:
Instantiate filesystems for given protocol and arguments
``storage_options`` are specific to the protocol being chosen, and are
passed directly to the class.
Maybe we can have a better documentation on our side instead using a wrapper:
import datasets
fs = datasets.filesystem("s3", anon=False, key=aws_access_key_id, secret=aws_secret_access_key)Where the docstring of datasets.filesystem is more complete and includes examples for popular filesystems like s3
There was a problem hiding this comment.
Another option would be to make available the filesystems classes easily:
>>> from datasets.filesystems import S3FileSystem # S3FileSystem is simply the class from s3fs
>>> S3FileSystem? # show the docstringshows
Init signature: s3fs.core.S3FileSystem(*args, **kwargs)
Docstring:
Access S3 as if it were a file system.
This exposes a filesystem-like API (ls, cp, open, etc.) on top of S3
storage.
Provide credentials either explicitly (``key=``, ``secret=``) or depend
on boto's credential methods. See botocore documentation for more
information. If no credentials are available, use ``anon=True``.
Parameters
----------
anon : bool (False)
Whether to use anonymous connection (public buckets only). If False,
uses the key/secret given, or boto's credential resolver (client_kwargs,
environment, variables, config files, EC2 IAM server, in that order)
key : string (None)
If not anonymous, use this access key ID, if specified
secret : string (None)
If not anonymous, use this secret access key, if specified
token : string (None)
If not anonymous, use this security token, if specified
etc.
There was a problem hiding this comment.
- If we add the various params separately, the more new filesystems we support, the more complicated it becomes. For the user it becomes difficult to know which params to look at, and for us to document everything. It seems like a good option to test things out, but having to change it down the road will require breaking changes, and we usually try to avoid these as much as possible.
- Using some kind of
storage_optionsjust likefsspec.filesystemmight be better but it seems difficult to document also. I think the same argument applies to having adatasets.filesystemhelper.
I think I have a preference for your second option @lhoestq
- It seems easy to show all the available filesystems to the user, with each of them having a meaningful documentation
- We can probably add tests for those we support explicitly
- If all of them share the same interface, then power users can probably use anything they want from
fsspecwithout explicit support from us?
What do you guys think?
There was a problem hiding this comment.
Yes I think the second option is interesting and I totally agree with your three points.
Maybe let's start by having S3FileSystem in datasets.filesystems and we can add the other ones later.
In the documentation of save_to_disk/load_from_disk we can then say that any filesystem from datasets.filesystems or fsspec can be used.
There was a problem hiding this comment.
I have rebuilt everything so that you can now pass in a fsspec like filesystem.
from datasets import S3Filesystem, load_from_disk
s3 = datasets.S3FileSystem(key=aws_access_key_id, secret=aws_secret_access_key) # doctest: +SKIP
dataset = load_from_disk('s3://my-private-datasets/imdb/train',fs=s3) # doctest: +SKIP
print(len(dataset))
# 25000I also created a "draft" documentation version with a few examples for S3Fileystem. Your feedback would be nice.
Afterwards, I would adjust the documentation of save_to_disk/load_from_disk
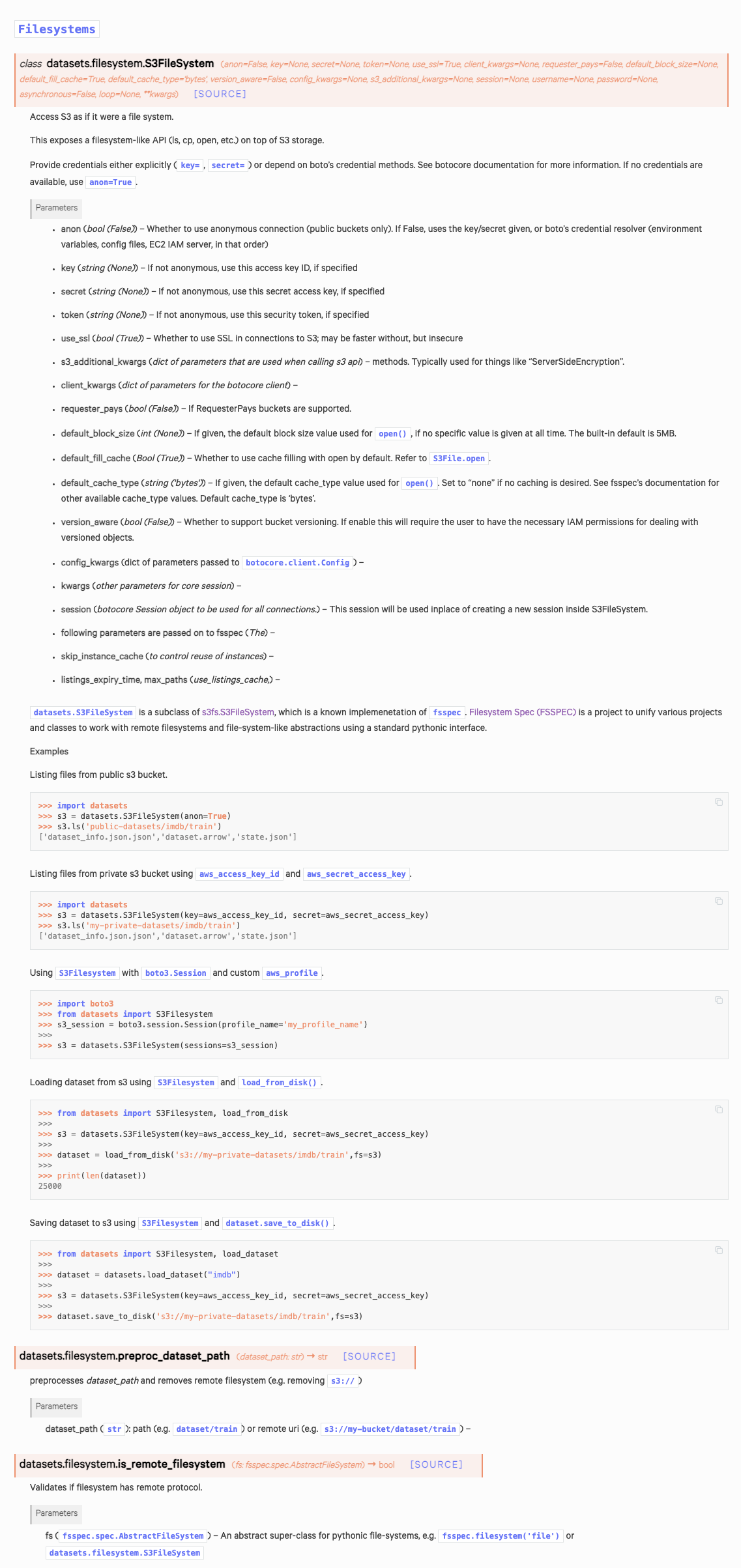
|
I created the documentation for |

Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
Co-authored-by: Quentin Lhoest <42851186+lhoestq@users.noreply.github.com>
There was a problem hiding this comment.
Thanks for adding this @philschmid :)
I tried to find a better name for save_to_disk/load_from_disk but actually I like it this way
Co-authored-by: Julien Chaumond <chaumond@gmail.com>
Co-authored-by: Julien Chaumond <chaumond@gmail.com>
Co-authored-by: Julien Chaumond <chaumond@gmail.com>
What does this PR do?
This PR adds the functionality to load and save
datasetsfrom and to s3.You can save
datasetswith eitherDataset.save_to_disk()orDatasetDict.save_to_disk.You can load
datasetswith eitherload_from_diskorDataset.load_from_disk(),DatasetDict.load_from_disk().Loading
csvorjsondatasets from s3 is not implemented.To save/load datasets to s3 you either need to provide an
aws_profile, which is set up on your machine, per default it uses thedefaultprofile or you have to pass anaws_access_key_idandaws_secret_access_key.The implementation was done with the
fsspecandboto3.Example
aws_profile:Example
aws_access_key_idandaws_secret_access_key:If you want to load a dataset from a public s3 bucket you can pass
anon=TrueExample
anon=True:Full Example
Related to #878
I would also adjust the documentation after the code would be reviewed, as long as I leave the PR in "draft" status. Something that we can consider is renaming the functions and changing the
_diskmaybe to_filesystem