Adding to_tf_dataset method #2731
Conversation
There was a problem hiding this comment.
This is very... PyTorchic XD
I like the design, I just think it can be made more general by using a data_collator instead of a tokenizer. My only concern is how it will go in term of performance (since TF might not like the PyTorch-iness of it all) but since we're just grabbing tokenized texts and maybe padding, this shouldn't be too much of a problem.
For computer vision though, we should see if there is a way to make sure to use several processes to prepare the batches, or does the final map do that automatically? Knowing TF I doubt it but one can hope.
|
This seems to be working reasonably well in testing, and performance is way better. |
3aec479
to
cc20d27
Compare
|
I made a change to the The key problem is that up until now the The change I made was to try to return standard |
|
Also I really can't emphasize enough how slow |
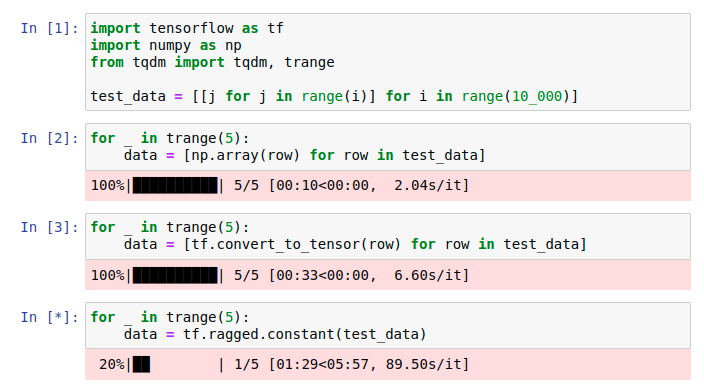
There was a problem hiding this comment.
I'm fine with this change to use tf tensors instead of ragged tensors, and it's nice to see that there is a fallback on ragged tensors anyway. I'm very impressed by the speed gains
This is indeed a breaking change, but I agree with you that in the end it's the only way to have a proper speed. It's also always better to get actual tensors rather than ragged tensors when possible.
The API looks fine to me :)
Maybe in the future people will be happy to have more control over the shuffling (setting the parameters to pass to Dataset.shuffle), but for now I think it's fine
src/datasets/arrow_dataset.py
Outdated
| columns, | ||
| batch_size, | ||
| shuffle, |
There was a problem hiding this comment.
Could they be optional parameters ?
There was a problem hiding this comment.
I was thinking about that! It's unclear to me what the defaults should be for columns or batch_size though, and I really wanted shuffle to be a required parameter to ensure people were aware of it, and that they didn't accidentally shuffle or skip shuffling their data when they didn't mean to.
I could maybe set batch_size to something like 32 by default and leave the other two as required parameters?
There was a problem hiding this comment.
Oh I see your point about shuffle.
And actually thinking more about it, it looks like we should require batch_size as well no ?
Maybe if columns is not specified then all of them are used ?
(this is just some random ideas, in the end we should just pick the one that fits the TF paradigm the best)
There was a problem hiding this comment.
I was thinking about that, but usually our datasets have one or more string columns that we don't want, so the default of using all columns will probably not work most of the time. It'd be nice if we had some way to auto-detect relevant columns, but I can't think of how we'd do that, so I think the safest thing to do is to just ask them to specify.
|
Hi @lhoestq, the tests have been modified and everything is passing. The Windows tests look to be failing for an unrelated reason, but other than that I'm ready to merge if you are! |
|
Hi @Rocketknight1 ! Feel free to merge |
4f7e564
to
71054d7
Compare
|
@lhoestq rebased onto master and it looks good! I'm doing some testing with new notebook examples, but are you happy to merge if that looks good? |
src/datasets/arrow_dataset.py
Outdated
| # We assume that if you're shuffling it's the train set, so we drop the remainder unless told not to | ||
| drop_remainder = shuffle | ||
| dataset = self.remove_columns([col for col in self.features if col not in cols_to_retain]) | ||
| dataset.set_format("python") |
There was a problem hiding this comment.
Note that it is faster to use the numpy format rather than python, especially for tensors. There's a zero-copy conversion from the Arrow data to numpy).
There was a problem hiding this comment.
Noted! I'll try to make it work in numpy format.
| cast_dtype = np.int64 if np.issubdtype(array.dtype, np.integer) else np.float32 | ||
| array = array.astype(cast_dtype) |
There was a problem hiding this comment.
Would this work for string types or nested types ?
There was a problem hiding this comment.
I've had some success with nested dtypes (in multiple choice datasets). This does fail on string types though - the tf.data.Dataset is intended to be passed straight to a model, so the assumption was that everything coming out of it would be convertable to a tf.Tensor. We could possibly make strings work in this context, though - but I'd need to think about a more generic approach to building the dataset and doing shape inference.
There was a problem hiding this comment.
Ok ! Maybe we can mention this in the docstring ?
There was a problem hiding this comment.
I just mentioned that numeric data only are expected in the docstring :)
…ort padding to constant size for TPU training
fdafeff
to
c8f251b
Compare
There was a problem hiding this comment.
Thanks a lot ! I think the PR is ready to be merged now :)
After that we may to update parts of the documentation:
- add the method to the list of documented Dataset method in
main_classes.rst - update the demo google colab
- update the tensorflow parts of the documentation
Are there other changes that you wanted to do before merging ?
|
@lhoestq No, I'm happy to merge it as-is and add documentation afterwards! |
Oh my god do not merge this yet, it's just a draft.
I've added a method (via a mixin) to the
arrow_dataset.Datasetclass that automatically converts our Dataset classes to TF Dataset classes ready for training. It hopefully has most of the features we want, including streaming from disk (no need to load the whole dataset in memory!), correct shuffling, variable-length batches to reduce compute, and correct support for unusual padding. It achieves that by calling the tokenizerpadmethod in the middle of a TF compute graph via a very hacky call totf.py_function, which is heretical but seems to work.A number of issues need to be resolved before it's ready to merge, though:
arrow_dataset.Datasetneed this method too?Dataset. Is there some automatic way to get the columns we want, or see which columns were added by the tokenizer?