Repository for the blog post: Accelerating Generative AI Part III: Diffusion, Fast. You can find a run down of the techniques on the 🤗 Diffusers website too.
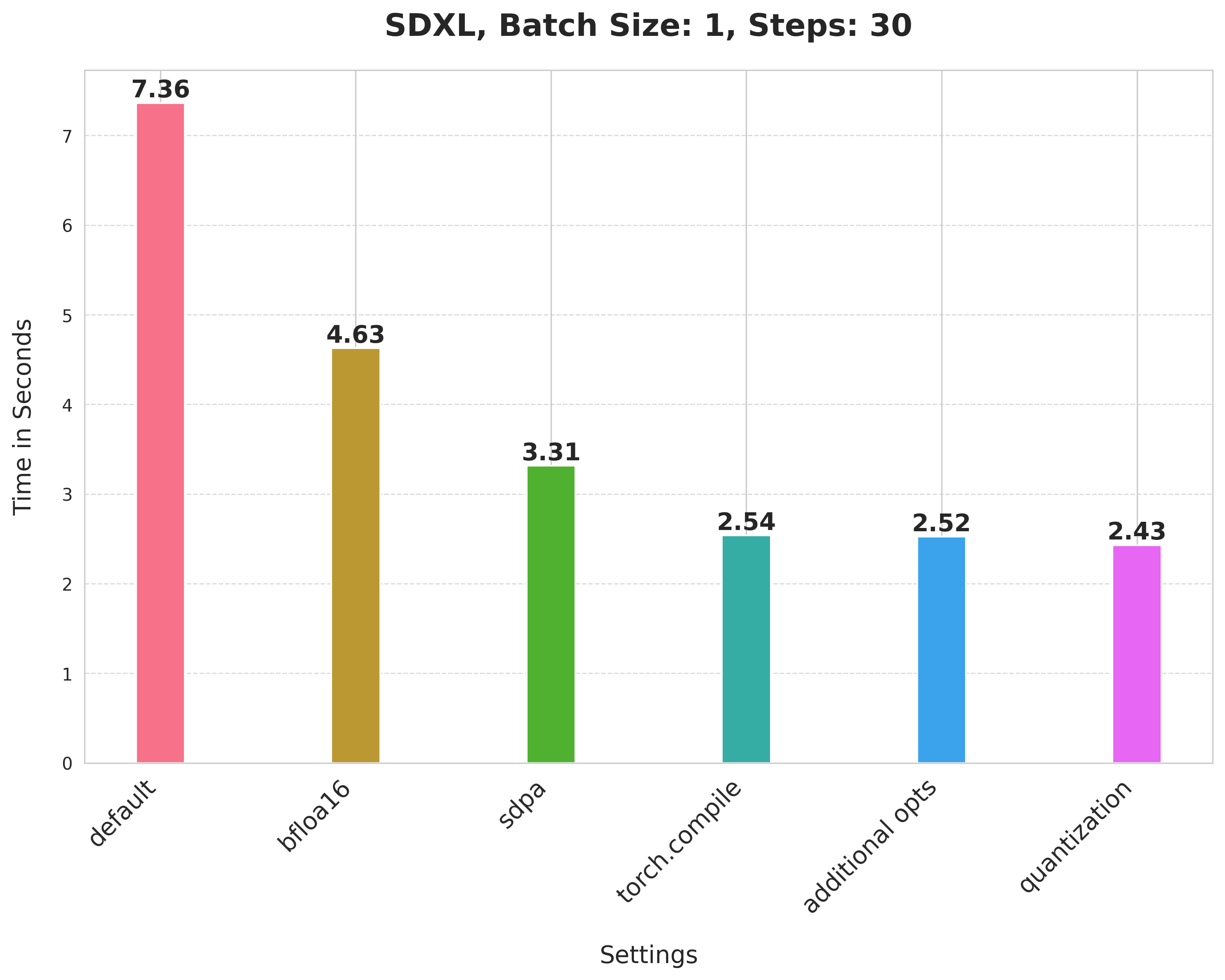
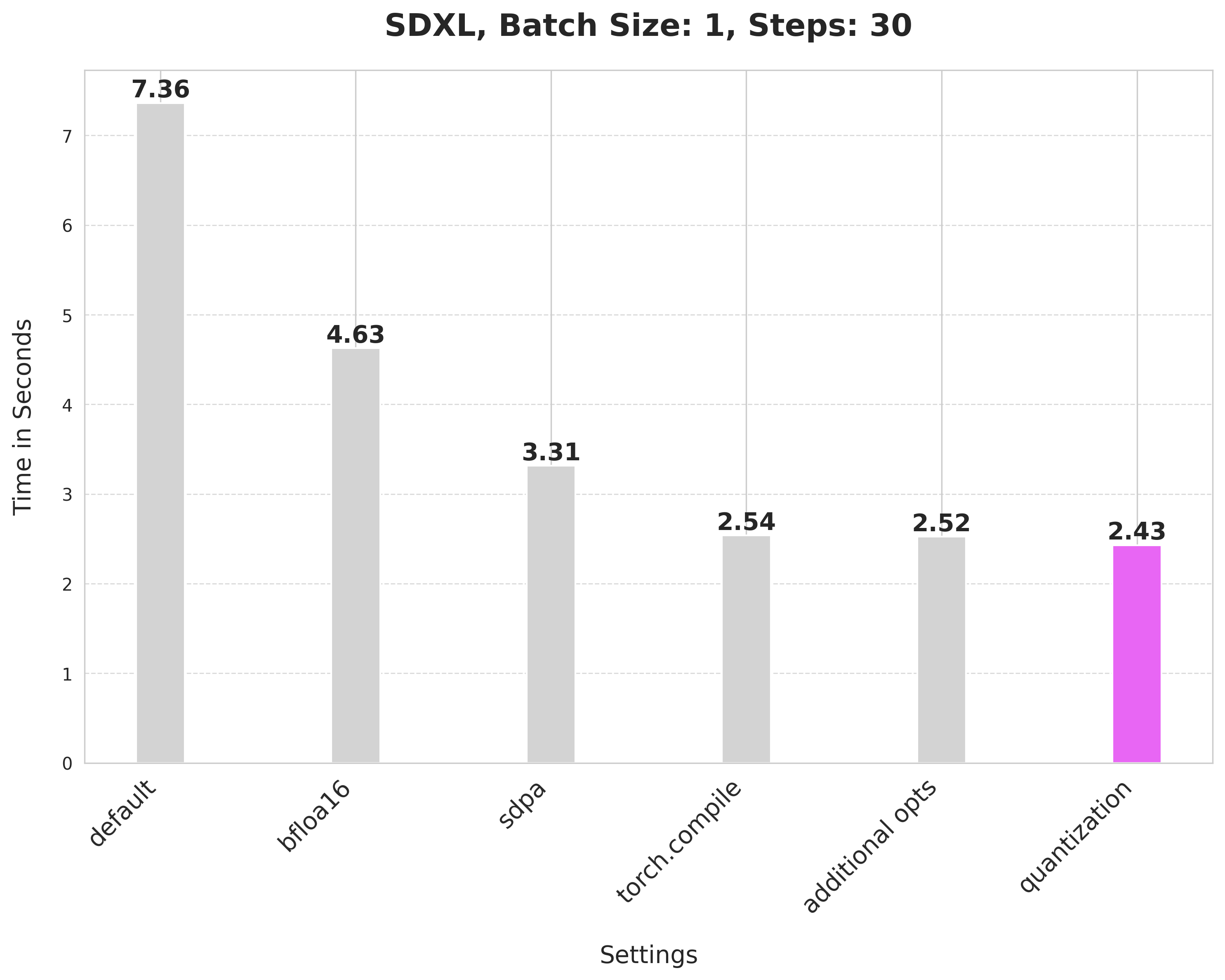
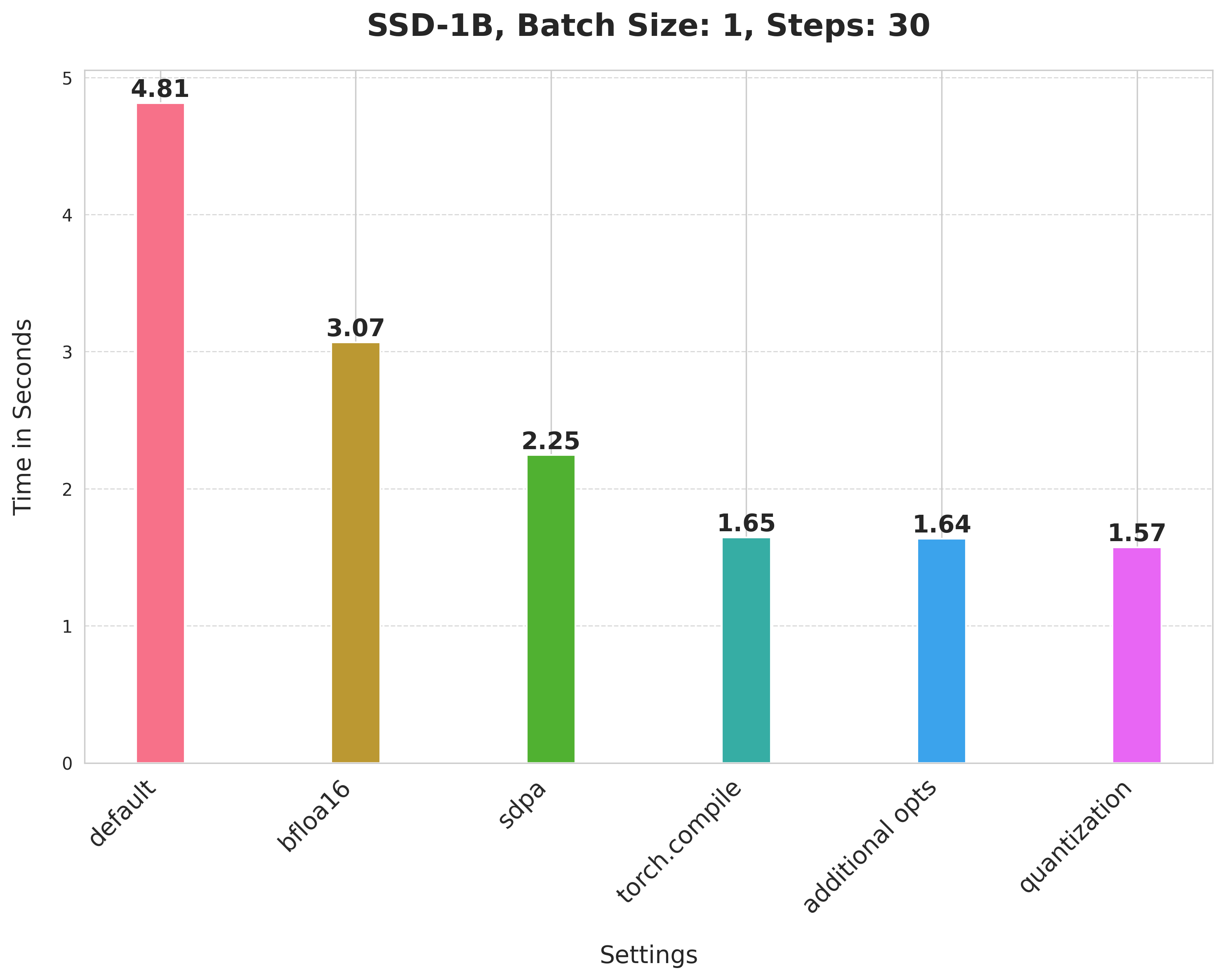
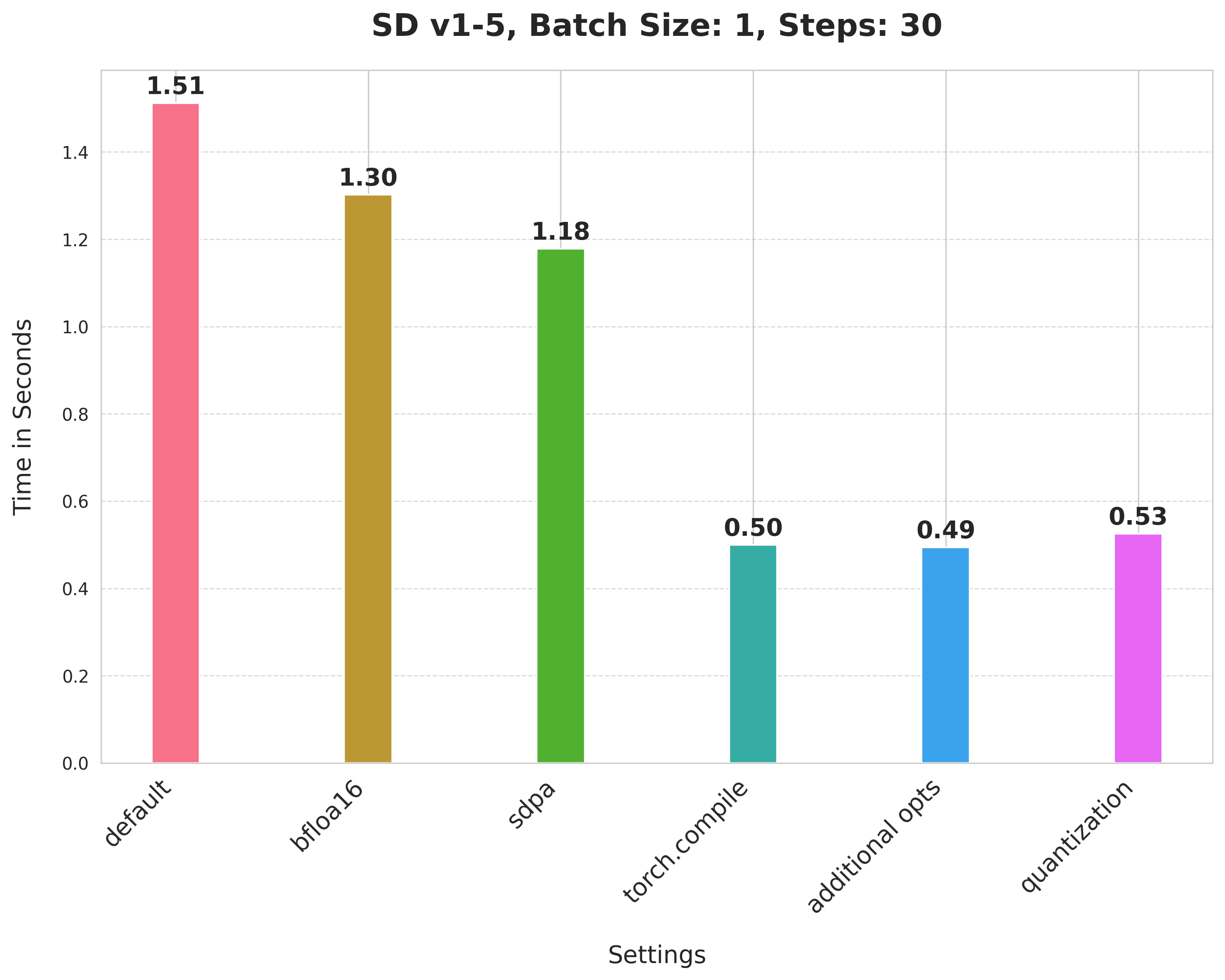
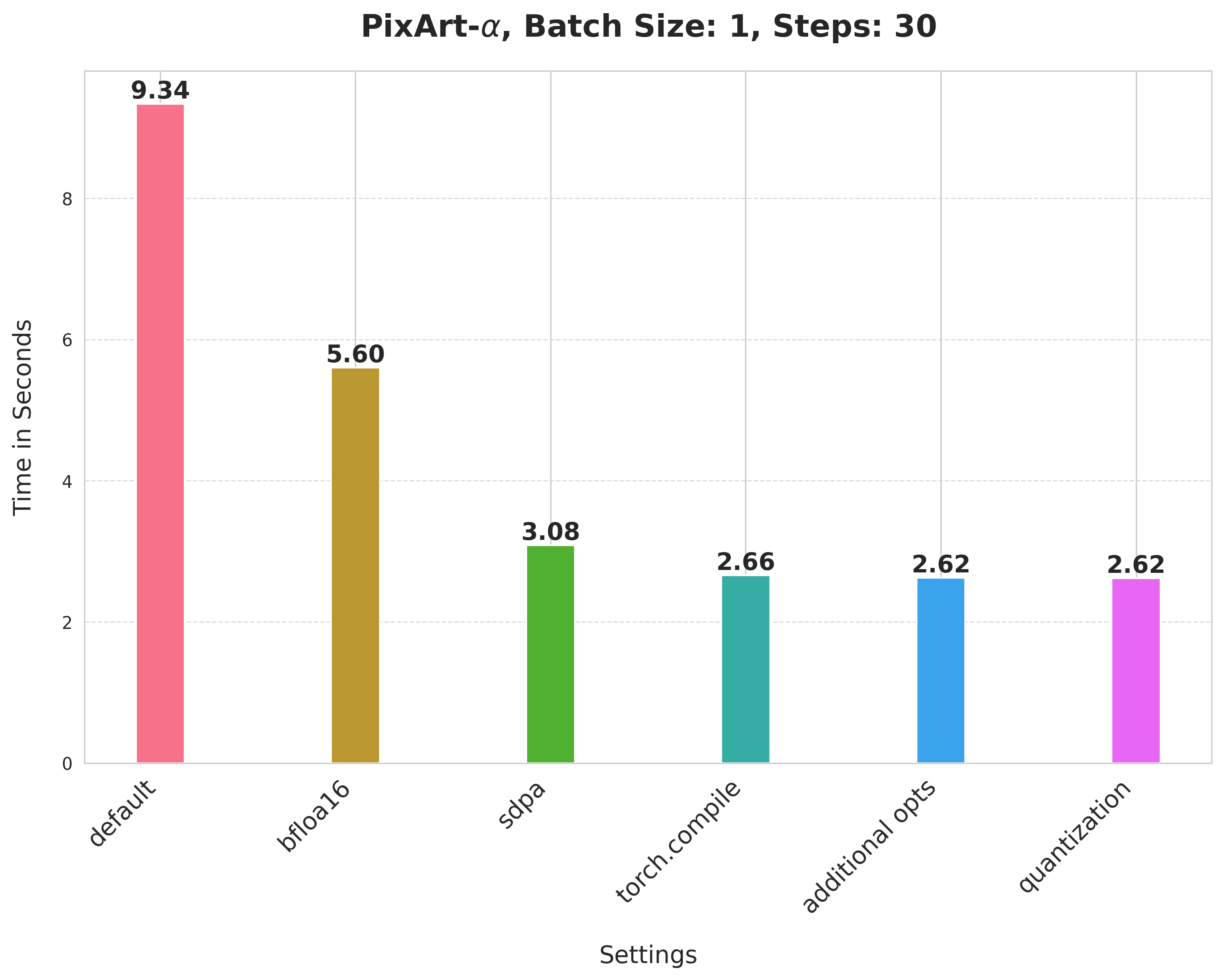
Summary of the optimizations:
- Running with the bfloat16 precision
scaled_dot_product_attention(SPDA)torch.compile- Combining q,k,v projections for attention computation
- Dynamic int8 quantization
These techniques are fairly generalizable to other pipelines too, as we show below.
Table of contents:
We rely on pure PyTorch for the optimizations. You can refer to the Dockerfile to get the complete development environment setup.
For hardware, we used an 80GB 400W A100 GPU with its memory clock set to the maximum rate (1593 in our case).
run_benchmark.py is the main script for benchmarking the different optimization techniques. After an experiment has been done, you should expect to see two files:
- A
.csvfile with all the benchmarking numbers. - A
.jpegimage file corresponding to the experiment.
Refer to the experiment-scripts/run_sd.sh for some reference experiment commands.
Notes on running PixArt-Alpha experiments:
- Use the
run_experiment_pixart.pyfor this. - Uninstall the current installation of
diffusersand re-install it again like so:pip install git+https://github.com/huggingface/diffusers@fuse-projections-pixart. - Refer to the
experiment-scripts/run_pixart.shscript for some reference experiment commands.
(Support for PixArt-Alpha is experimental.)
You can use the prepare_results.py script to generate a consolidated CSV file and a plot to visualize the results from it. This is best used after you have run a couple of benchmarking experiments already and have their corresponding CSV files.
To run the script, you need the following dependencies:
- pandas
- matplotlib
- seaborn
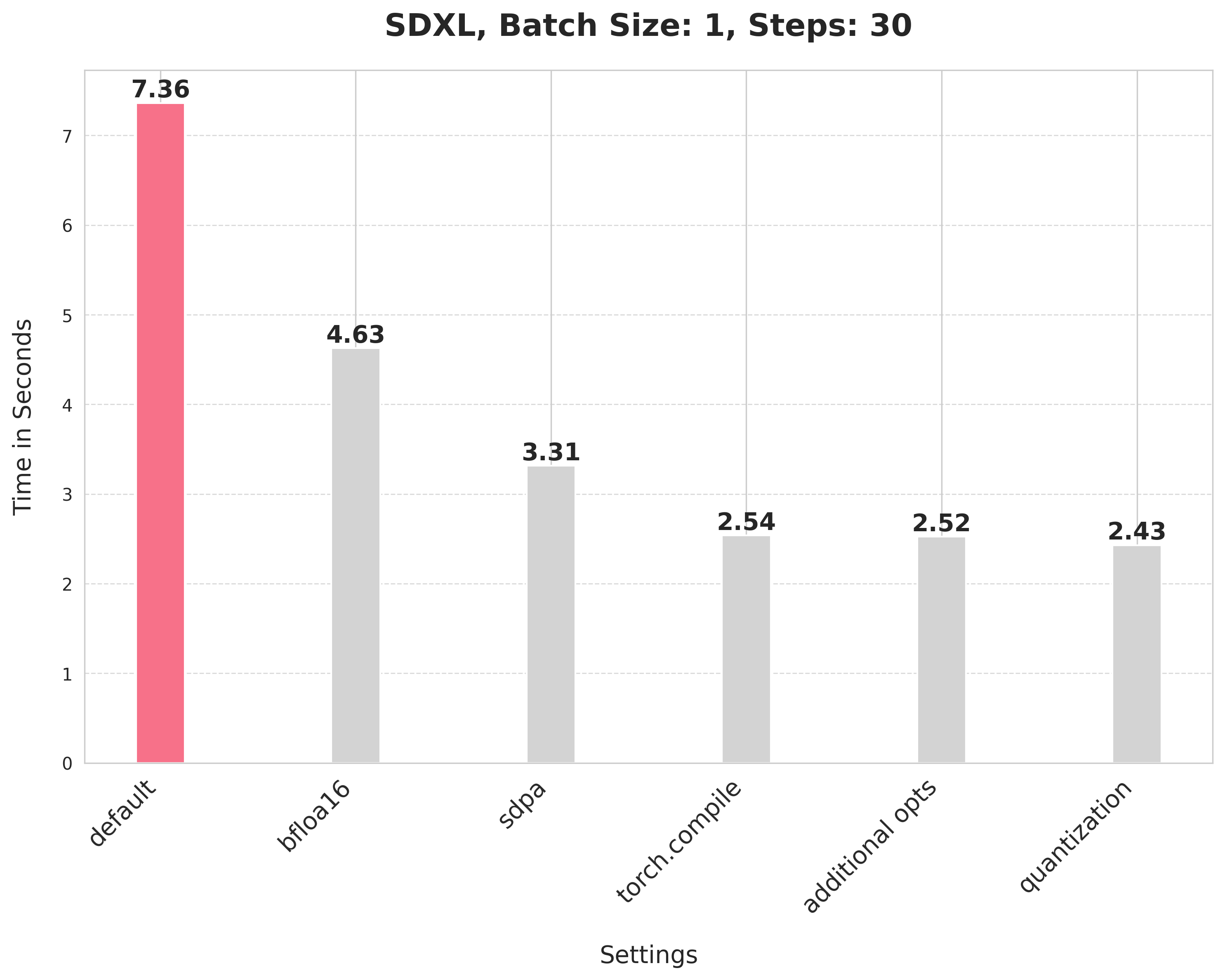
Baseline
from diffusers import StableDiffusionXLPipeline
# Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]With this, we're at:
Bfloat16
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]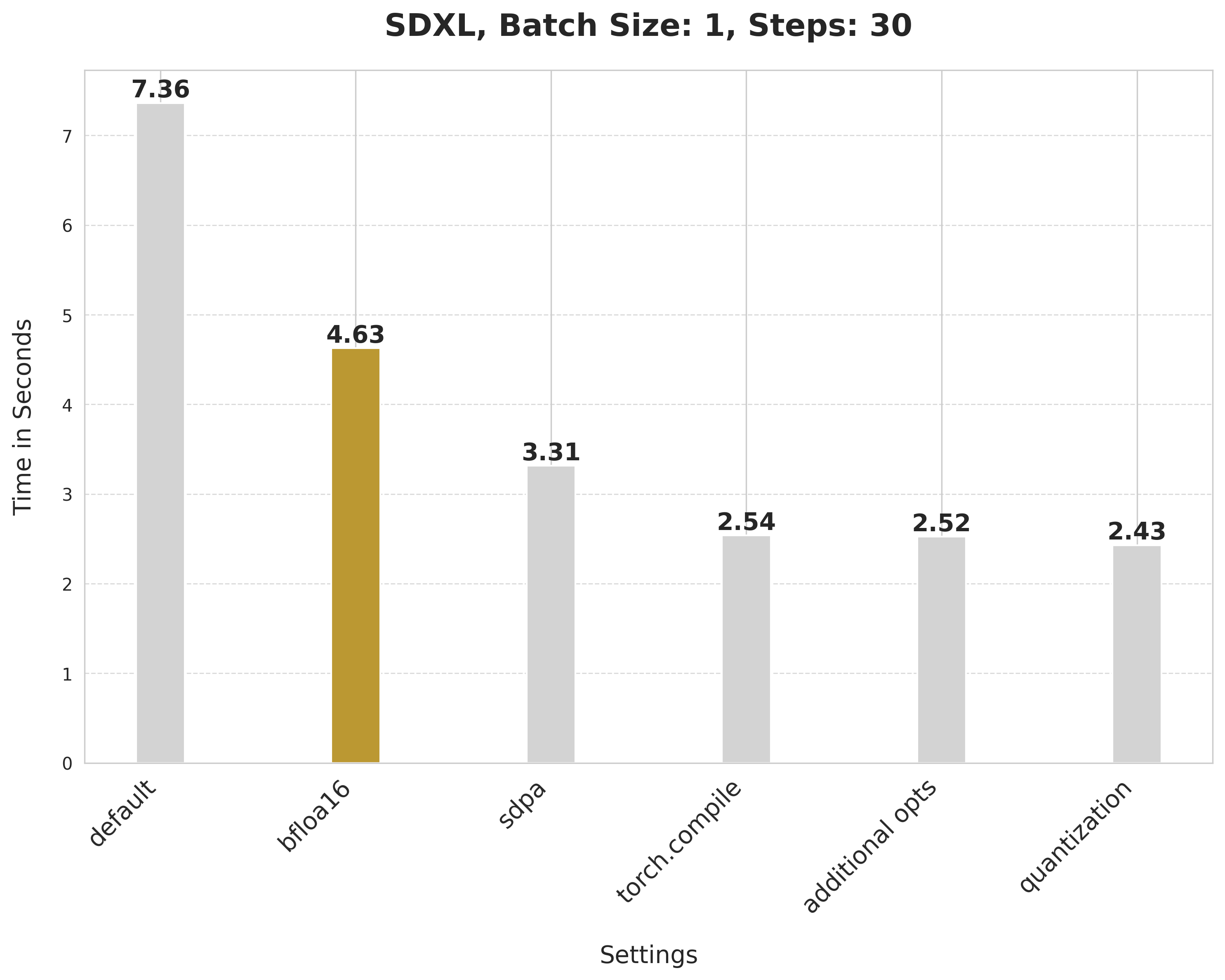
💡 We later ran the experiments in float16 and found out that the recent versions of
torchaodo not incur numerical problems from float16.
scaled_dot_product_attention
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]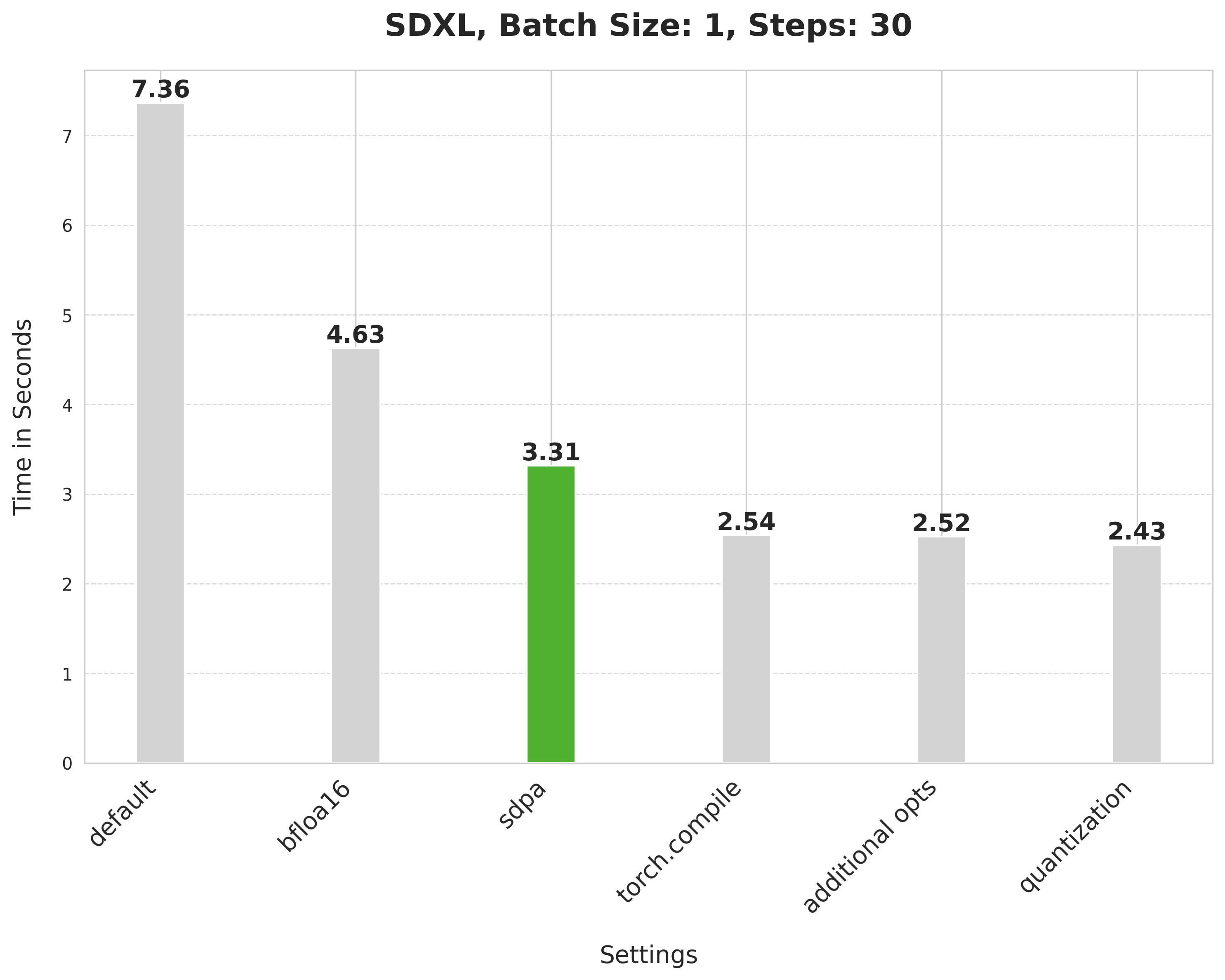
torch.compile
First, configure some compiler flags:
from diffusers import StableDiffusionXLPipeline
import torch
# Set the following compiler flags to make things go brrr.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = TrueThen load the pipeline:
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")Compile and perform inference:
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]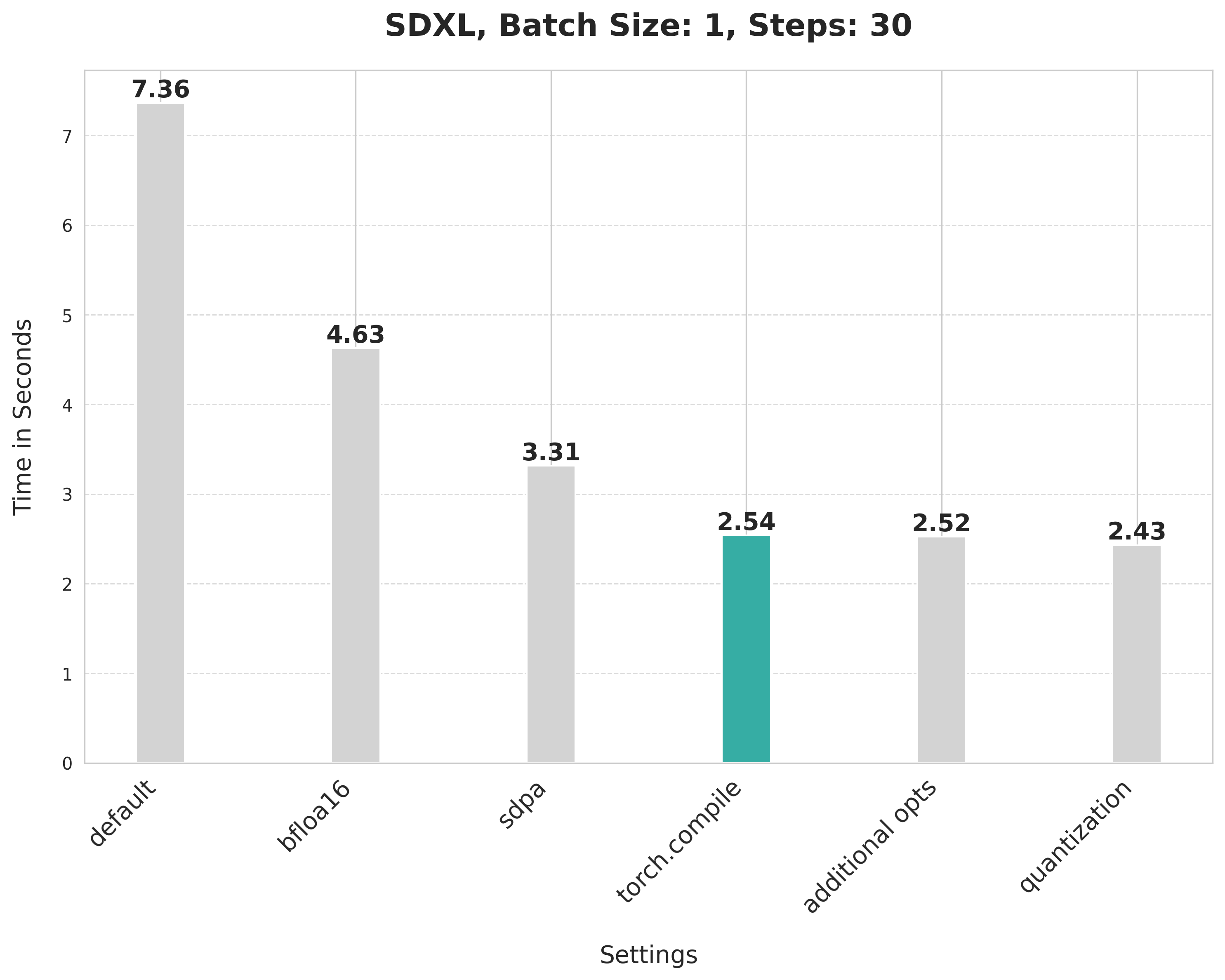
Combining attention projection matrices
from diffusers import StableDiffusionXLPipeline
import torch
# Configure the compiler flags.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]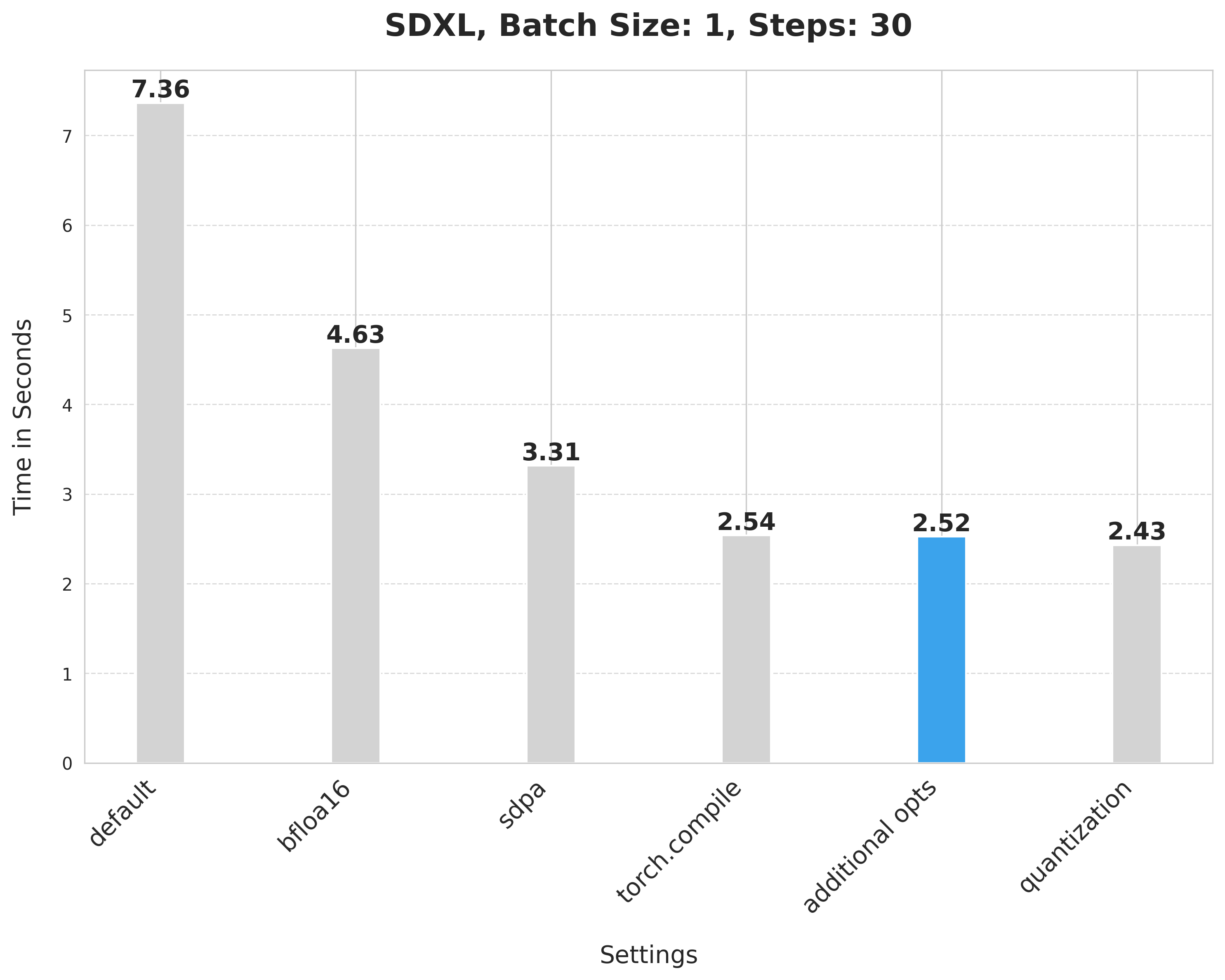
Dynamic quantization
Start by setting the compiler flags (this time, we have two new):
from diffusers import StableDiffusionXLPipeline
import torch
from torchao.quantization import apply_dynamic_quant, swap_conv2d_1x1_to_linear
# Compiler flags. There are two new.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = TrueThen write the filtering functions to apply dynamic quantization:
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)Then we're rwady for inference:
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Change the memory layout.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
# Swap the pointwise convs with linears.
swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
# Apply dynamic quantization.
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
# Compile.
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]