The BEiT model was proposed in BEiT: BERT Pre-Training of Image Transformers by Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class of an image (as done in the original ViT paper), BEiT models are pre-trained to predict visual tokens from the codebook of OpenAI's DALL-E model given masked patches.
The abstract from the paper is the following:
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).
This model was contributed by nielsr. The JAX/FLAX version of this model was contributed by kamalkraj. The original code can be found here.
- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
outperform both the original model (ViT) as well as Data-efficient Image Transformers (DeiT) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
fine-tuning on custom data here (you can just replace
[
ViTFeatureExtractor] by [BeitImageProcessor] and [ViTForImageClassification] by [BeitForImageClassification]). - There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for performing masked image modeling. You can find it here.
- As the BEiT models expect each image to be of the same size (resolution), one can use
[
BeitImageProcessor] to resize (or rescale) and normalize images for the model. - Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
each checkpoint. For example,
microsoft/beit-base-patch16-224refers to a base-sized architecture with patch resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the hub. - The available checkpoints are either (1) pre-trained on ImageNet-22k (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on ImageNet-1k (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
- BEiT uses relative position embeddings, inspired by the T5 model. During pre-training, the authors shared the
relative position bias among the several self-attention layers. During fine-tuning, each layer's relative position
bias is initialized with the shared relative position bias obtained after pre-training. Note that, if one wants to
pre-train a model from scratch, one needs to either set the
use_relative_position_biasor theuse_relative_position_biasattribute of [BeitConfig] toTruein order to add position embeddings.
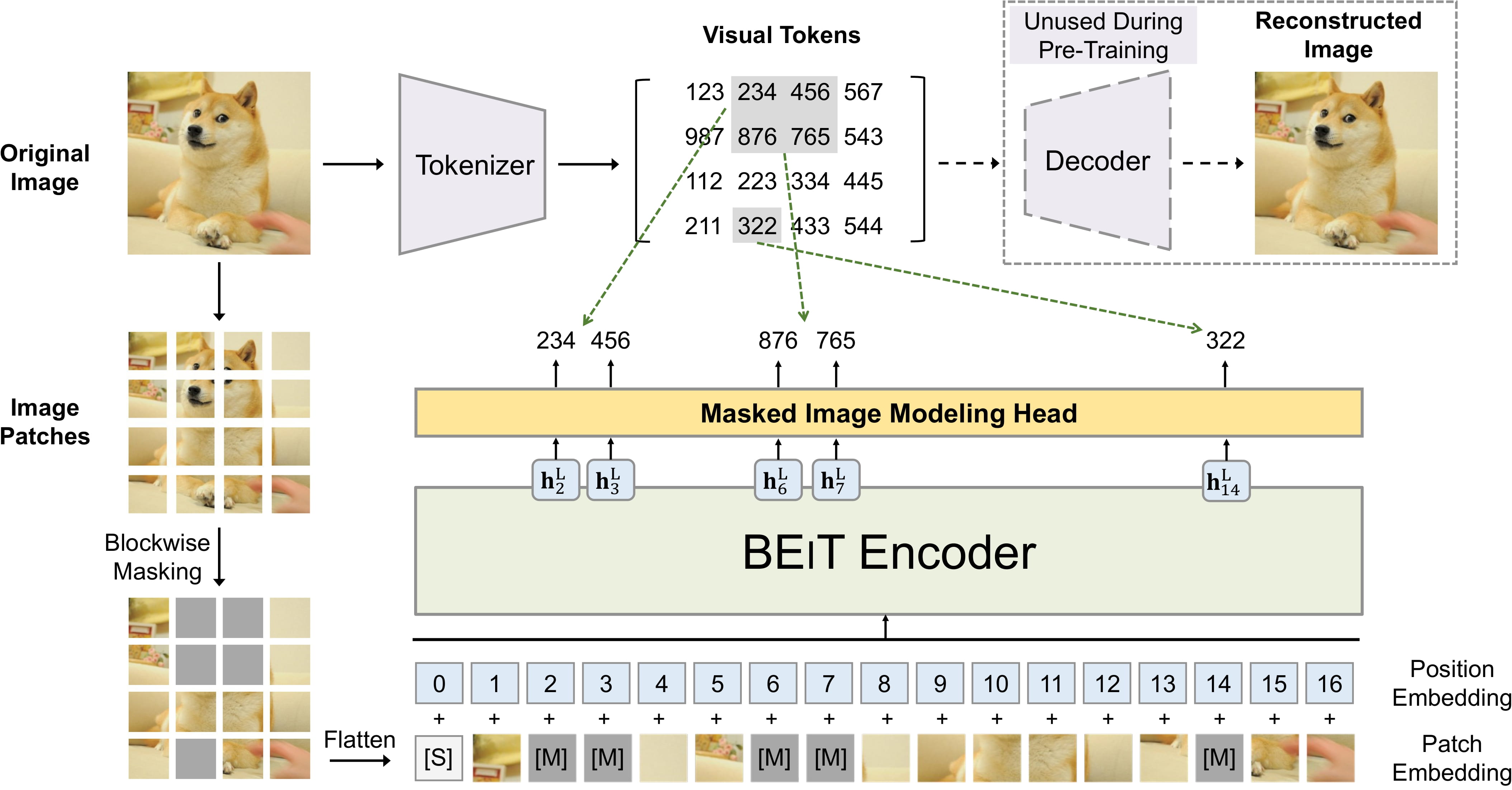
BEiT pre-training. Taken from the original paper.
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
- [
BeitForImageClassification] is supported by this example script and notebook. - See also: Image classification task guide
Semantic segmentation
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
[[autodoc]] BeitConfig
[[autodoc]] BeitFeatureExtractor - call - post_process_semantic_segmentation
[[autodoc]] BeitImageProcessor - preprocess - post_process_semantic_segmentation
[[autodoc]] BeitModel - forward
[[autodoc]] BeitForMaskedImageModeling - forward
[[autodoc]] BeitForImageClassification - forward
[[autodoc]] BeitForSemanticSegmentation - forward
[[autodoc]] FlaxBeitModel - call
[[autodoc]] FlaxBeitForMaskedImageModeling - call
[[autodoc]] FlaxBeitForImageClassification - call