The OPT model was proposed in Open Pre-trained Transformer Language Models by Meta AI. OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
This model was contributed by Arthur Zucker, Younes Belkada, and Patrick Von Platen. The original code can be found here.
Tips:
- OPT has the same architecture as [
BartDecoder]. - Contrary to GPT2, OPT adds the EOS token
</s>to the beginning of every prompt.
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook on fine-tuning OPT with PEFT, bitsandbytes, and Transformers. 🌎
- A blog post on decoding strategies with OPT.
- Causal language modeling chapter of the 🤗 Hugging Face Course.
- [
OPTForCausalLM] is supported by this causal language modeling example script and notebook. - [
TFOPTForCausalLM] is supported by this causal language modeling example script and notebook. - [
FlaxOPTForCausalLM] is supported by this causal language modeling example script.
- Text classification task guide
- [
OPTForSequenceClassification] is supported by this example script and notebook.
- [
OPTForQuestionAnswering] is supported by this question answering example script and notebook. - Question answering chapter of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on How 🤗 Accelerate runs very large models thanks to PyTorch with OPT.
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolationMake also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
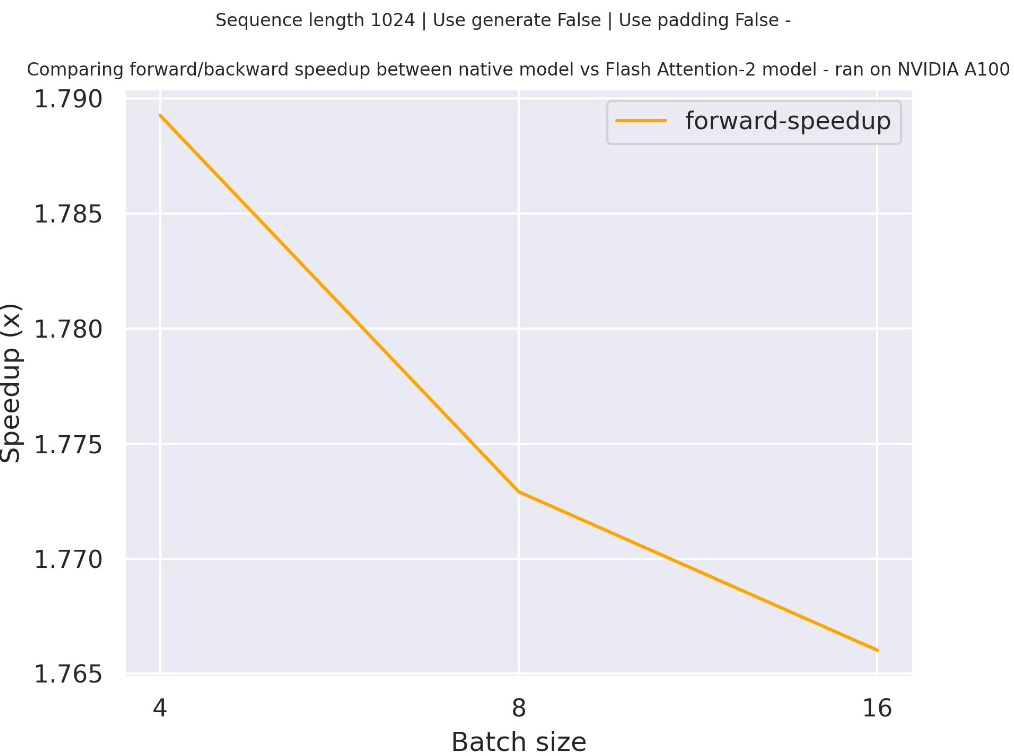
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-2.7b checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
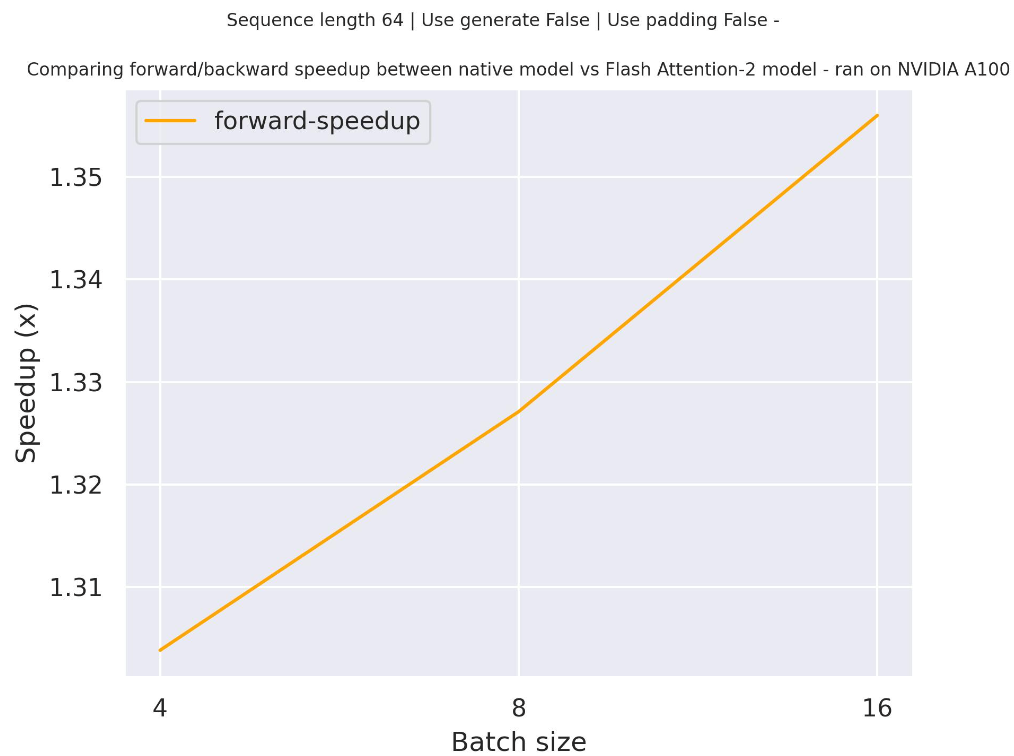
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-350m checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
[[autodoc]] OPTConfig
[[autodoc]] OPTModel - forward
[[autodoc]] OPTForCausalLM - forward
[[autodoc]] OPTForSequenceClassification - forward
[[autodoc]] OPTForQuestionAnswering - forward
[[autodoc]] TFOPTModel - call
[[autodoc]] TFOPTForCausalLM - call
[[autodoc]] FlaxOPTModel - call
[[autodoc]] FlaxOPTForCausalLM - call