The text-visual prompting (TVP) framework was proposed in the paper Text-Visual Prompting for Efficient 2D Temporal Video Grounding by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
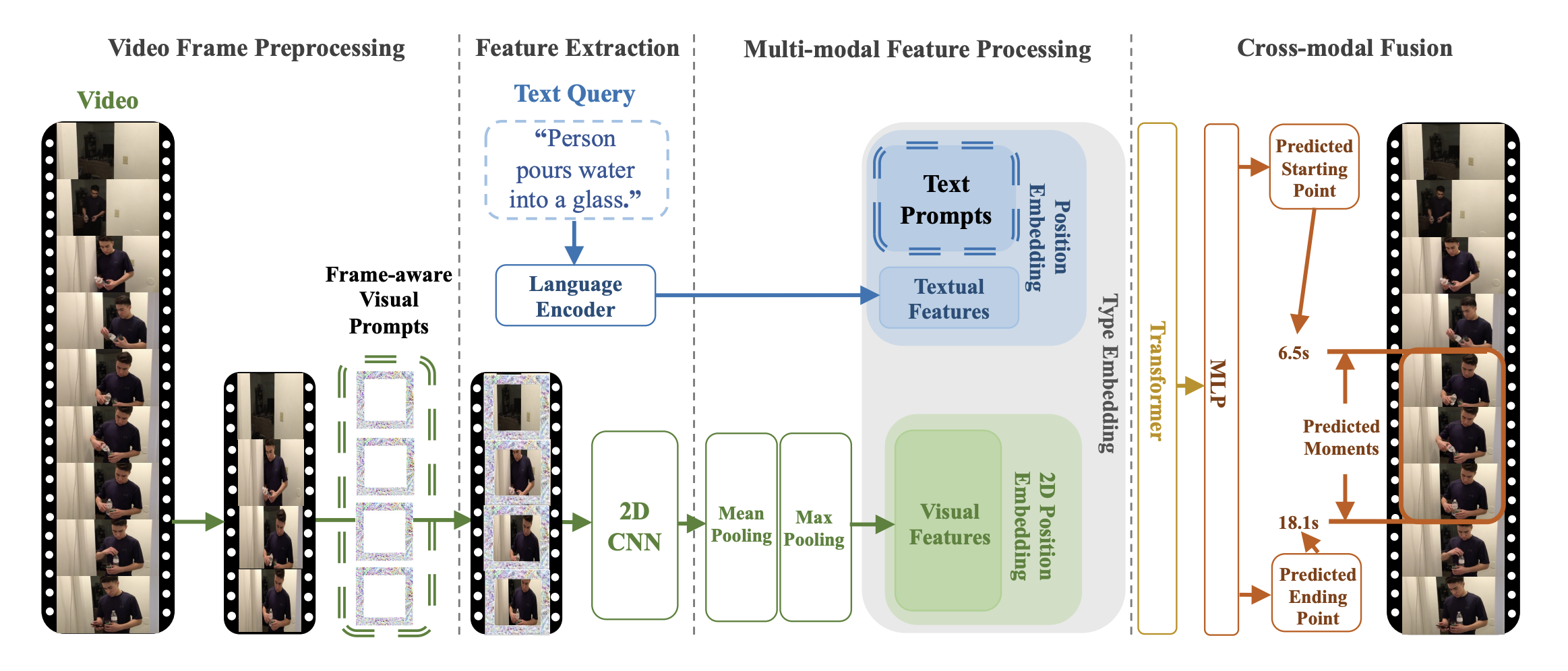
TVP architecture. Taken from the original paper.
This model was contributed by Jiqing Feng. The original code can be found here.
Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems. In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
The [TvpProcessor] wraps [BertTokenizer] and [TvpImageProcessor] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run temporal video grounding using [TvpProcessor] and [TvpForVideoGrounding].
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video. Return None if the no
video stream was found.
fps (float): the number of frames per second of the video.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Decode the video and perform temporal sampling.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video.
'''
assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")Tips:
- This implementation of TVP uses [
BertTokenizer] to generate text embeddings and Resnet-50 model to compute visual embeddings. - Checkpoints for pre-trained tvp-base is released.
- Please refer to Table 2 for TVP's performance on Temporal Video Grounding task.
[[autodoc]] TvpConfig
[[autodoc]] TvpImageProcessor - preprocess
[[autodoc]] TvpProcessor - call
[[autodoc]] TvpModel - forward
[[autodoc]] TvpForVideoGrounding - forward