BEiT モデルは、BEiT: BERT Pre-Training of Image Transformers で提案されました。 ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。 ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく (オリジナルの ViT 論文 で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。 マスクされた OpenAI の DALL-E モデル のコードブックからビジュアル トークンを予測します パッチ。
論文の要約は次のとおりです。
自己教師あり視覚表現モデル BEiT (Bidirectional Encoderpresentation) を導入します。 イメージトランスフォーマーより。自然言語処理分野で開発されたBERTに倣い、マスク画像を提案します。 ビジョントランスフォーマーを事前にトレーニングするためのモデリングタスク。具体的には、事前トレーニングでは各画像に 2 つのビューがあります。 パッチ (16x16 ピクセルなど)、およびビジュアル トークン (つまり、個別のトークン)。まず、元の画像を「トークン化」して、 ビジュアルトークン。次に、いくつかの画像パッチをランダムにマスクし、それらをバックボーンの Transformer に供給します。事前トレーニング 目的は、破損したイメージ パッチに基づいて元のビジュアル トークンを回復することです。 BEiTの事前トレーニング後、 事前トレーニングされたエンコーダーにタスク レイヤーを追加することで、ダウンストリーム タスクのモデル パラメーターを直接微調整します。 画像分類とセマンティックセグメンテーションに関する実験結果は、私たちのモデルが競争力のある結果を達成することを示しています 以前の事前トレーニング方法を使用して。たとえば、基本サイズの BEiT は、ImageNet-1K で 83.2% のトップ 1 精度を達成します。 同じ設定でゼロからの DeiT トレーニング (81.8%) を大幅に上回りました。また、大型BEiTは 86.3% は ImageNet-1K のみを使用しており、ImageNet-22K での教師付き事前トレーニングを使用した ViT-L (85.2%) を上回っています。
- BEiT モデルは通常のビジョン トランスフォーマーですが、教師ありではなく自己教師ありの方法で事前トレーニングされています。彼らは
ImageNet-1K および CIFAR-100 で微調整すると、オリジナル モデル (ViT) と データ効率の高いイメージ トランスフォーマー (DeiT) の両方を上回るパフォーマンスを発揮します。推論に関するデモノートブックもチェックできます。
カスタム データの微調整は こちら (置き換えるだけで済みます)
[
BeitImageProcessor] による [ViTFeatureExtractor] と [ViTForImageClassification] by [BeitForImageClassification])。 - DALL-E の画像トークナイザーと BEiT を組み合わせる方法を紹介するデモ ノートブックも利用可能です。 マスクされた画像モデリングを実行します。 ここ で見つけることができます。
- BEiT モデルは各画像が同じサイズ (解像度) であることを期待しているため、次のように使用できます。
[
BeitImageProcessor] を使用して、モデルの画像のサイズを変更 (または再スケール) し、正規化します。 - 事前トレーニングまたは微調整中に使用されるパッチ解像度と画像解像度の両方が名前に反映されます。
各チェックポイント。たとえば、
microsoft/beit-base-patch16-224は、パッチ付きの基本サイズのアーキテクチャを指します。 解像度は 16x16、微調整解像度は 224x224 です。すべてのチェックポイントは ハブ で見つけることができます。 - 利用可能なチェックポイントは、(1) ImageNet-22k で事前トレーニングされています ( 1,400 万の画像と 22,000 のクラス) のみ、(2) ImageNet-22k でも微調整、または (3) ImageNet-1kでも微調整/2012/) (ILSVRC 2012 とも呼ばれ、130 万件のコレクション) 画像と 1,000 クラス)。
- BEiT は、T5 モデルからインスピレーションを得た相対位置埋め込みを使用します。事前トレーニング中に、著者は次のことを共有しました。
いくつかの自己注意層間の相対的な位置の偏り。微調整中、各レイヤーの相対位置
バイアスは、事前トレーニング後に取得された共有相対位置バイアスで初期化されます。ご希望の場合は、
モデルを最初から事前トレーニングするには、
use_relative_position_biasまたは 追加するには、[BeitConfig] のuse_relative_position_bias属性をTrueに設定します。 位置の埋め込み。
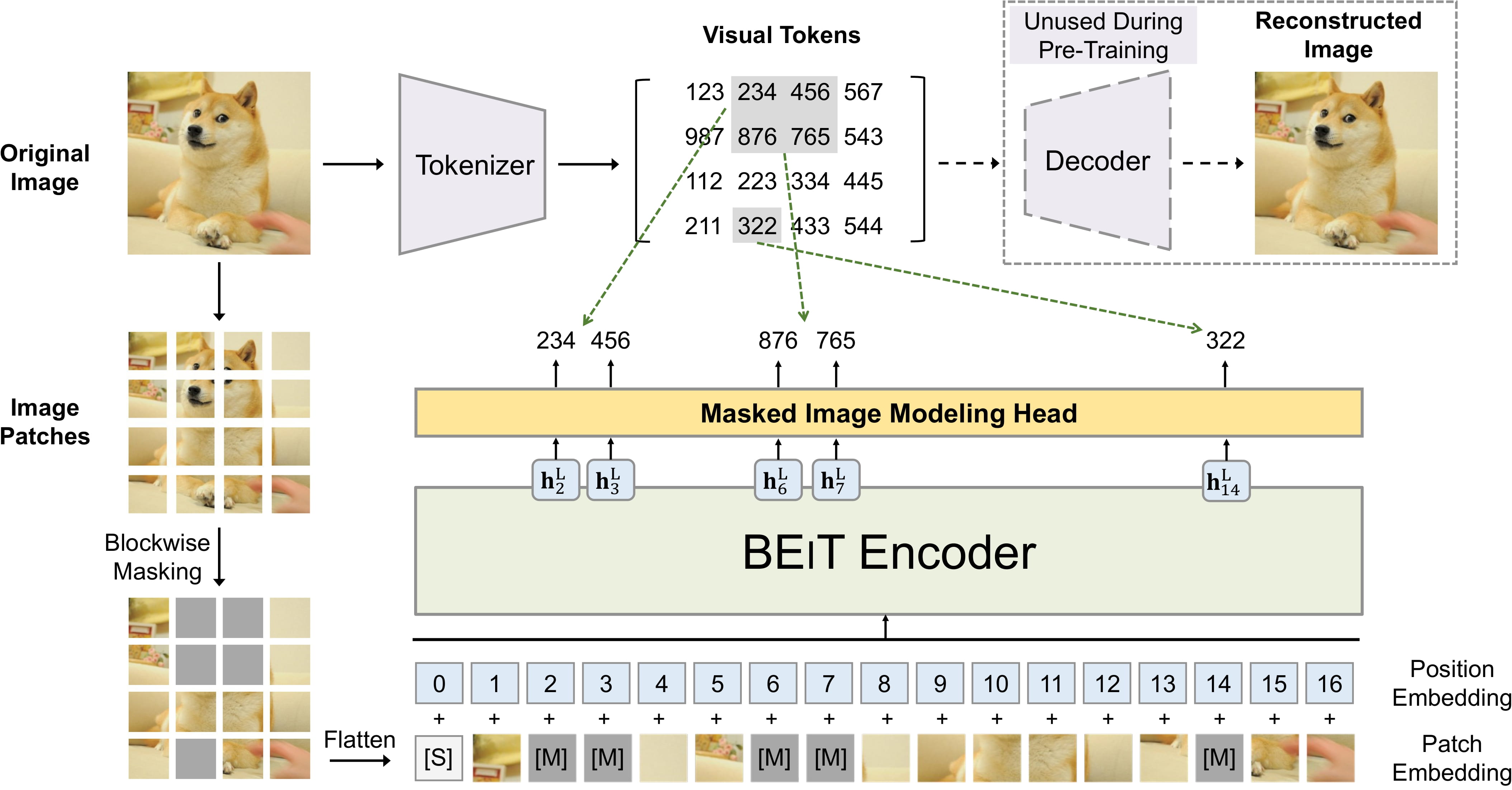
BEiT の事前トレーニング。 元の論文から抜粋。
このモデルは、nielsr によって提供されました。このモデルの JAX/FLAX バージョンは、 kamalkraj による投稿。元のコードは ここ にあります。
BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
- [
BeitForImageClassification] は、この サンプル スクリプト および ノートブック。 - 参照: 画像分類タスク ガイド
セマンティック セグメンテーション
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
[[autodoc]] BeitConfig
[[autodoc]] BeitFeatureExtractor - call - post_process_semantic_segmentation
[[autodoc]] BeitImageProcessor - preprocess - post_process_semantic_segmentation
[[autodoc]] BeitModel - forward
[[autodoc]] BeitForMaskedImageModeling - forward
[[autodoc]] BeitForImageClassification - forward
[[autodoc]] BeitForSemanticSegmentation - forward
[[autodoc]] FlaxBeitModel - call
[[autodoc]] FlaxBeitForMaskedImageModeling - call
[[autodoc]] FlaxBeitForImageClassification - call