ConvNeXT モデルは、A ConvNet for the 2020s で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。 ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
論文の要約は次のとおりです。
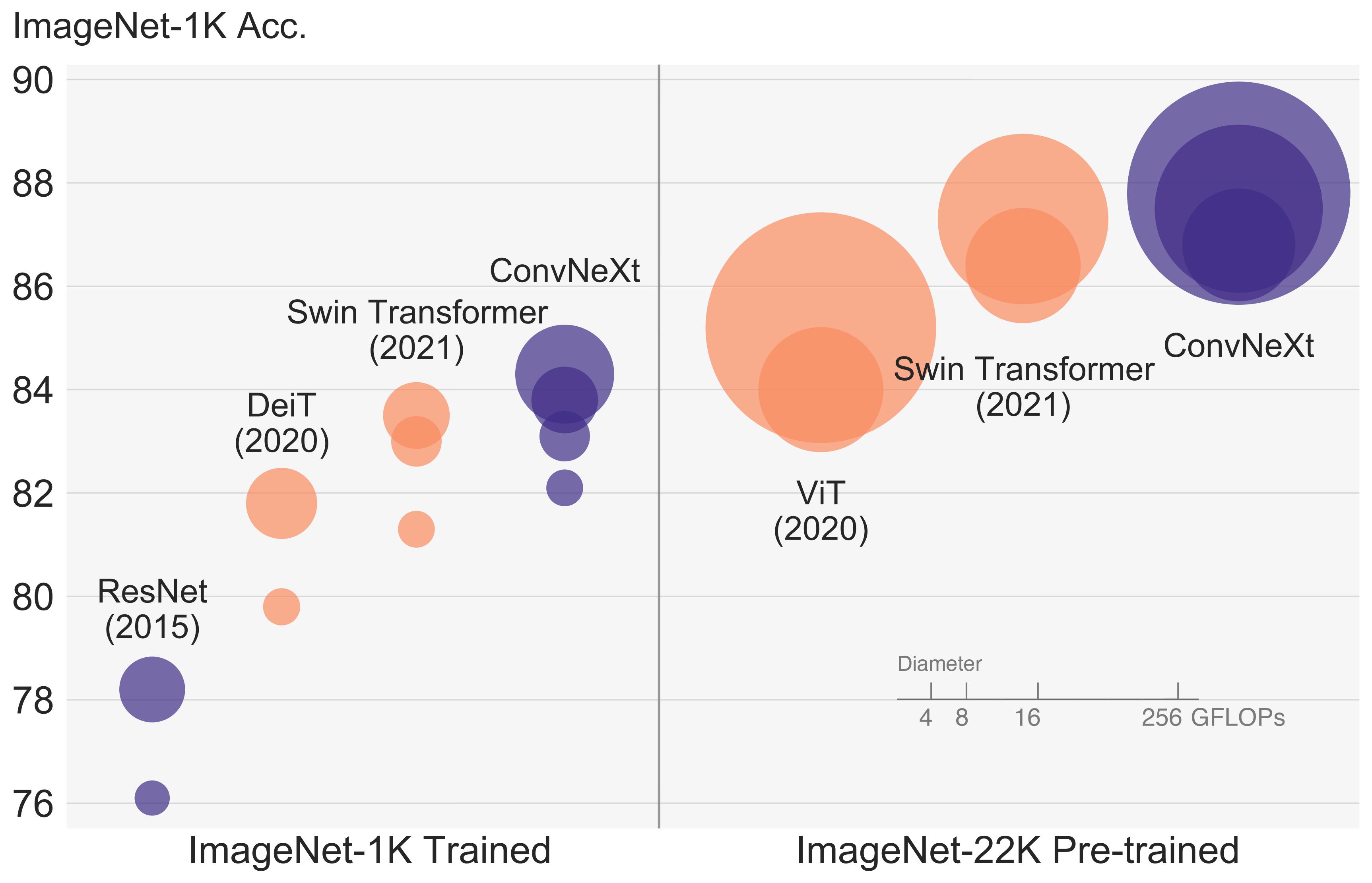
視覚認識の「狂騒の 20 年代」は、最先端の画像分類モデルとして ConvNet にすぐに取って代わられた Vision Transformers (ViT) の導入から始まりました。 一方、バニラ ViT は、オブジェクト検出やセマンティック セグメンテーションなどの一般的なコンピューター ビジョン タスクに適用すると困難に直面します。階層型トランスフォーマーです (Swin Transformers など) は、いくつかの ConvNet の以前の機能を再導入し、Transformers を汎用ビジョン バックボーンとして実用的に可能にし、幅広い環境で顕著なパフォーマンスを実証しました。 さまざまな視覚タスク。ただし、このようなハイブリッド アプローチの有効性は、依然として、固有の誘導性ではなく、トランスフォーマーの本質的な優位性によるところが大きいと考えられています。 畳み込みのバイアス。この作業では、設計空間を再検討し、純粋な ConvNet が達成できる限界をテストします。標準 ResNet を設計に向けて徐々に「最新化」します。 ビジョン Transformer の概要を確認し、途中でパフォーマンスの違いに寄与するいくつかの重要なコンポーネントを発見します。この調査の結果は、純粋な ConvNet モデルのファミリーです。 ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュールから構築されており、精度と拡張性の点で Transformers と有利に競合し、87.8% の ImageNet トップ 1 精度を達成しています。 標準 ConvNet のシンプルさと効率を維持しながら、COCO 検出と ADE20K セグメンテーションでは Swin Transformers よりも優れたパフォーマンスを発揮します。
ConvNeXT アーキテクチャ。 元の論文から抜粋。
このモデルは、nielsr によって提供されました。 TensorFlow バージョンのモデルは ariG23498 によって提供されました。 gante、および sayakpaul (同等の貢献)。元のコードは こちら にあります。
ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
- [
ConvNextForImageClassification] は、この サンプル スクリプト および ノートブック。 - 参照: 画像分類タスク ガイド
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
[[autodoc]] ConvNextConfig
[[autodoc]] ConvNextFeatureExtractor
[[autodoc]] ConvNextImageProcessor - preprocess
[[autodoc]] ConvNextModel - forward
[[autodoc]] ConvNextForImageClassification - forward
[[autodoc]] TFConvNextModel - call
[[autodoc]] TFConvNextForImageClassification - call