XLNET SQuAD2.0 Fine-Tuning - What May Have Changed? #2651
Comments
|
I have been facing the same problem with RoBERTa finetuning for multiple choice QA datasets. I have even tried going back to the older version of transformers (version 2.1.0 from Oct 2019) and re-running my experiments but I am not able to replicate results from before anymore. The loss just varies within a range of +/- 0.1. |
|
Are you using one of the recent versions of run_squad.py? It was quite heavily refactored in december. Maybe there is a mistake now. Can you try it with the run_squad.py of the 2.1.1 release again? |
|
Could it be related to 96e8350? Before november 29 there was a mistake where the script would only evaluate on 1/N_GPU of the entire evaluation set. |
|
@cronoik good suggestion
I'm attempting to recreate the environment that existed for the successful fine-turning above that was dated 26Nov2019. I have the .yml file for that environment but after re-creating & re-running the script I get errors of missing "Albert files" and others. Not making much sense since this is using XLNET. I'm keeping after it. @LysandreJik helpful information
Perhaps, but given that the successful run was before 29Nov2019, plus my eval script uses single GPU ( CUDA_VISIBLE_DEVICES=0 ), could [96e8350] be a culprit? How best to debug my latest, up-to-date environment? |
|
How about the cached files at .cache/torch/transformers? Ran single GPU0 on script above with gradient accumulation set to 48, everything else the same. Results and loss were the same. Apparently it is not a distributed processing issue. Update 30Jan20: Cleared the caches, ran the distributed processing script in the first post above adding |
|
Hi guys! I just run into the same issue. I fine-tuned XLNet on the squad 2 trainingset over the weekend, exactly as instructed on the examples page, and got the same inferior results:
My versions: I will proceed to run it again on transformers v2.1.1 and report back whether the old code still works for XLNet. |
|
Hi @WilliamNurmi, thank you for taking the time to do this. Do you mind making sure that you're using This should only affect setups with more than 1 gpu and this does not seem to be your case, but if it is, it would be great to update the sampler. |
|
Hi @LysandreJik, I'm indeed using only 1 gpu, so we should be good there! |
|
No dice with XLNet on v2.1.1. I used the same parameters as @ahotrod except for slight changes for gradient_accumulation_steps (not used), max_seq_length (368) and per_gpu_train_batch_size (1).
Inferior results:
I tried to mimic the setup at the time with the following versions: Interestingly the first run with Does anyone have any idea what could have changed since last November that completely broke the SQuAD2 training? Could it be the files (pretrained network, tokenization, hyperparameters etc) that transformers lib is downloading at the beginning of the training ? |
|
Is the run_squad.py the 2.1.1 version? |
|
As noted on other issues, plain old Bert is working better, so the issue seems to be specific to XLNet, RoBERTa On transformers
|
|
After nearly two weeks of unsuccessful varied XLNet fine-tunes, I gave-up and switched to fine-tuning ALBERT for an alternative model: Ahhh, the beauty and flexibility of Transformers, out with one model and in with another. Current system configuration: |
Nice results @ahotrod! Better than what you got in Dec: Could you share the hyper-parameters you used? |
|
@WilliamNurmi thanks for your feedback When Google Research released their v2 of ALBERT LMs they stated that xxlarge-v1 outperforms xxlarge-v2 and have a discussion as to why: https://github.com/google-research/ALBERT. So I've stuck with v1 for that reason plus the "teething" issues that have been associated with v2 LMs. Yes, seems there have been transfomers revisions positively impacting ALBERT SQuAD 2.0 fine-tuning since my results Dec19 as you noted. I think including Additional ALBERT & transformers refinements, hopefully significant, are in transformers v2.4.1: BTW the heat produced from my hardware-challenged computer, hotrod, is a welcome tuning by-product for my winter office, summer not so much. Hoping for a NVIDIA Ampere upgrade before this summer's heat. My fine-tuning has been with transformer's |
|
Thanks for all the details @ahotrod, I had missed the fact that classifier dropout had just been added! I restarted my run with v2.4.1. Loss seems to be going down nicely, so far so good. It's gonna be 6 days for me since I'm on a single Ti 1080. I'm gonna have to look for some new hardware / instances soon as well. Any bigger model or sequence length and I couldn't fit a single batch on this GPU anymore :D Looking forward to the sneak peak of the results when your run finishes! |
|
@ahotrod could you consider sharing trained ALBERT SQUAD trained model on https://huggingface.co/models? |
@knuser Absolutely, I signed-up some time ago with that intent but have yet to contribute. FYI, 11 question inferencing/prediction with this 512 max_seq_length xxlarge ALBERT model takes 37 seconds CPU and 5 secs single GPU w/large batches on my computer, hotrod, described above. BTW, sharing can definitely save some energy & lower the carbon footprint. As an example my office electric bill doubled last month from just under $100 to over $200 with nearly constant hotrod fine-tuning. Perhaps the gas heater didn't need to fire-up as often though. ;-] |
|
Fine-tuning the which is no improvement over fine-tuning the same script with Transformers 2.3.0 My best model to date is now posted at: https://huggingface.co/ahotrod/albert_xxlargev1_squad2_512 The AutoModels: (AutoConfig, AutoTokenizer & AutoModel) should also work, however I Hope this furthers your efforts! |
|
Hi guys, thanks for the great discussion. I've been trying to reproduce the XLNet fine-tuning myself, but have failed to do so so far. I stumbled upon a few issues along the way, mostly related to the padding side. There was an issue that I fixed this morning related to the I'm still actively working on it and will let you know as I progress (it is quite a lengthy process as a finetuning requires a full-day of computing on my machine). |
|
Hi @LysandreJik, thanks for hunting the bugs! It's going to be a great help for many people. I don't know the details of the remaining bugs, but at least the bugs I encountered were so bad that I think you should see whether or not it works very quickly after starting fine-tuning by checking if the loss is decreasing on tensorboard. |
|
I can also confirm the issue after fine-tuning xlnet-large-cased on Squad 2.0 for 1 epoch. The F1 score is 46.53 although the NoAns_F1 was 89.05, probably because the model is predicting so many blanks (most with "start_log_prob": -1000000.0, "end_log_prob": -1000000.0) while HasAns_exact is close to 0. Not sure if it is related to the CLS token position mentioned in #947 and #1088. But it might be specific to the unanswerable questions in Squad 2.0. Hopefully the bug will be found and fixed soon :-) Transformers: 2.5.1 |
|
@ahotrod I saw you're using a different eval script ( |
|
@elgeish - good eye on my eval script using My https://huggingface.co/ahotrod/xlnet_large_squad2_512 model is from Nov 2019, same as the successful fine-tuned model described in my first post above. |
|
@ahotrod thanks for the explanation! |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
Any update on this issue? I am facing same issue when fine tuning custom RoBERTa. |
|
I'm on |
❓ Questions & Help
I fine-tuned XLNet_large_cased on SQuAD 2.0 last November 2019 with Transformers V2.1.1 yielding satisfactory results:
with script:
After upgrading Transformers to Version 2.3.0 I decided to see if there would be any improvements in the fine-tuning results using the same script above. I got the following results:
No learning takes place:
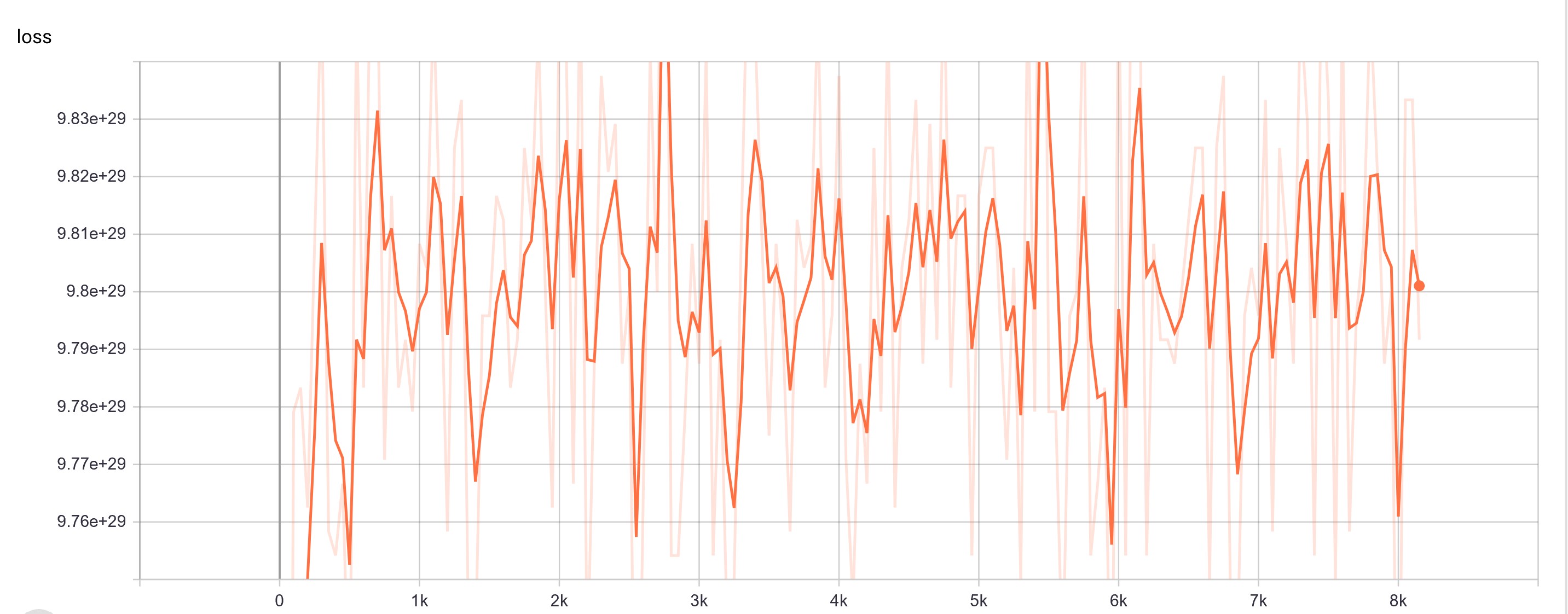
Looking for potential explanation(s)/source(s) for the loss of performance. I have searched Transformer releases and issues for anything pertaining to XLNet with no clues. Are there new fine-tuning hyperparameters I've missed that now need to be assigned, or maybe didn't exist in earlier Transformer versions? Any PyTorch/Tensorflow later version issues? I may have to recreate the Nov 2019 environment for a re-run to verify the earlier results, and then incrementally update Transformers, PyTorch, Tensorflow, etc.?
Current system configuration:
OS: Linux Mint 19.3 based on Ubuntu 18.04. 3 LTS and Linux Kernel 5.0
GPU/CPU: 2 x NVIDIA 1080Ti / Intel i7-8700
Seasonic 1300W Prime Gold Power Supply
CyberPower 1500VA/1000W battery backup
Transformers: 2.3.0
PyTorch: 1.3.0
TensorFlow: 2.0.0
Python: 3.7.5
The text was updated successfully, but these errors were encountered: