
- Deep learning is a more approachable name for an artificial neural network.
- The “deep” in deep learning refers to the depth of the network a.k.a Hidden layers. But an artificial neural network can also be very shallow.

- Neural networks are inspired by the structure of the cerebral cortex.
- At the basic level is the Perceptron, the mathematical representation of a biological neuron.
- Like in the cerebral cortex, there can be several layers of interconnected perceptrons.
Its the simplest ANN architecture. It was invented by Frank Rosenblatt in 1957 and published as Rosenblatt, Frank (1958), The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, v65, No. 6, pp. 386–408. doi:10.1037/h0042519
Lets see the architecture shown below -
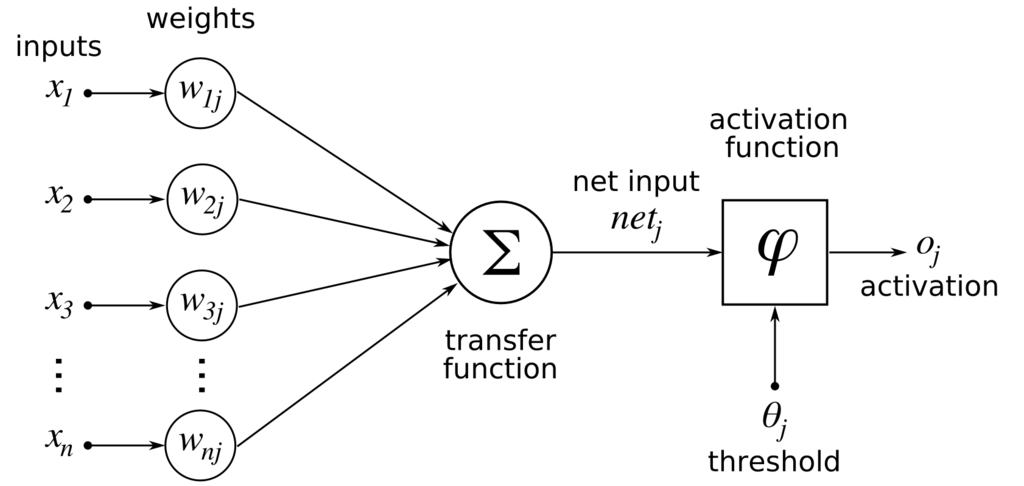
Perceptron
- For multiplication of 2 matrices we need to have 1st matrix column= 2nd matrix row. That's why we take transpose of matrix W to WT.
- We are taking theta
$\large \theta$ as the thrisold value-
- Changing RHS to LHS
- We are taking theta as
$W_0X_0$ and$W_0X_0$ which is 'y intercept' or 'c' in y=mX+c

- In
$\large y=mX+c$ ,- c or bias helps the shifting from +ve to -ve and vice versa so that the output is controlled.
- m or the slope helps the rotation.

- Bias effects the output as the following it change the output class +ve to -ve.

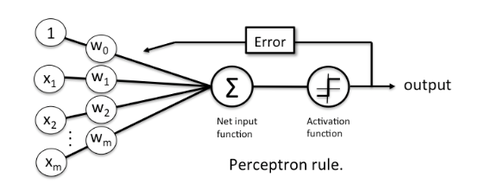
-
As we know error is (Predicted Value - Acctual Value) .
-
A Neural Network back propagate and updates Weights and Bias.
-
Now, the question is What would be the update weight?

- The update value for each input is not same as each input weight has different contribution to the final error.
- So the rectification of weight for each input would be different.

- Suppose we have a Neural Network with 3 input layers and 2 hidden layers and we are using sigmoid as a activation function inside the hidden layer as well as in final weight calculation.

- Input buffers(that's why not having Bias, Input neuron would have Bias), Hidden layers, Output Neuron are like
- Hidden Layer weight calculation

- Final layer weight calculation


- Calculationin Hidden layers
- Calculation in Output layer
Neural networks are set of algorithms inspired by the functioning of human brian. Generally when you open your eyes, what you see is called data and is processed by the Nuerons(data processing cells) in your brain, and recognises what is around you. That’s how similar the Neural Networks works. They takes a large set of data, process the data(draws out the patterns from data), and outputs what it is.
-
Neural networks were one of the first machine learning models.
-
Deep learning implies the use of neural networks.
-
The "deep" in deep learning refers to a neural network with many hidden layers.
-
Neural networks accept input and produce output.
- The input to a neural network is called the feature vector.
- The size of this vector is always a fixed length.
- Changing the size of the feature vector means recreating the entire neural network.
- A vector implies a 1D array. Historically the input to a neural network was always 1D.
- However, with modern neural networks you might see inputs, such as:-
-
1D Vector - Classic input to a neural network, similar to rows in a spreadsheet. Common in predictive modeling.
-
2D Matrix - Grayscale image input to a convolutional neural network (CNN).
-
3D Matrix - Color image input to a convolutional neural network (CNN).
-
nD Matrix - Higher order input to a CNN.
Prior to CNN's, the image input was sent to a neural network simply by squashing the image matrix into a long array by placing the image's rows side-by-side. CNNs are different, as the nD matrix literally passes through the neural network layers.
Dimensions The term dimension can be confusing in neural networks. In the sense of a 1D input vector, dimension refers to how many elements are in that 1D array.
- For example a neural network with 10 input neurons has 10 dimensions.
- However, now that we have CNN's, the input has dimensions too.
- The input to the neural network will usually have 1, 2 or 3 dimensions. 4 or more dimensions is unusual.
- You might have a 2D input to a neural network that has 64x64 pixels.
- This would result in 4,096 input neurons.
- This network is either** 2D or 4,096D, **depending on which set of dimensions you are talking about!
Like many models, neural networks can function in classification or regression:
- Regression - You expect a number as your neural network's prediction.
- Classification - You expect a class/category as your neural network's prediction.(the number of Input = The number of Output)
The following shows a classification and regression neural network:

- Notice that the output of the regression neural network is numeric and the output of the classification is a class.
- Regression, or two-class classification, networks always have a single output.
- Classification neural networks have an output neuron for each class.

The Calculation would be like-
- (I1W1+I2W2+B) = Weighted sum ;and it would be go through the Activation function
- Where 'I' is the input and 'W' is the weight.
The following diagram shows a typical neural network:

There are usually four types of neurons in a neural network:
- Input Neurons - Each input neuron is mapped to one element in the feature vector.
- Hidden Neurons - Hidden neurons allow the neural network to abstract and process the input into the output.
- Output Neurons - Each output neuron calculates one part of the output.
- Context Neurons - Holds state between calls to the neural network to predict.
- Bias Neurons - Work similar to the y-intercept of a linear equation.
These neurons are grouped into layers:
- Input Layer - The input layer accepts feature vectors from the dataset. Input layers usually have a bias neuron.
- Output Layer - The output from the neural network. The output layer does not have a bias neuron.
- Hidden Layers - Layers that occur between the input and output layers. Each hidden layer will usually have a bias neuron.
Deep learning is a machine learning technique that teaches computers to do what comes naturally to humans: learn by example
Activation functions are really important for a Artificial Neural Network to learn and make sense of something really complicated and Non-linear complex functional mappings between the inputs and response variable.
- Their main purpose is to convert a input signal of a node in a A-NN to an output signal.
- A Neural Network without Activation function would simply be a Linear regression Model which has limited power and does not performs good most of the times.
- Also without activation function our Neural network would not be able to learn and model other complicated kinds of data such as images, videos , audio , speech etc
- Non-linear functions are those which have degree more than one and they have a curvature when we plot a Non-Linear function. Now we need a Neural Network Model to learn and represent almost anything and any arbitrary complex function which maps inputs to outputs.
- Also another important feature of a Activation function is that it should be differentiable. We need it to be this way so as to perform backpropogation optimization strategy while propogating backwards in the network to compute gradients of Error(loss) with respect to Weights and then accordingly optimize weights using Gradient descend or any other Optimization technique to reduce Error.
Sigmoid or Logistic Tanh — Hyperbolic tangent ReLu -Rectified linear units

- Error or loss is the difference between the actual value and the expected value.
- In deep Neural Net we adding up the Waights in every layer and at the end (or between-ReLu for hidden layer)we calculate all the waightes with a Activation function.
- The main perpose of back propagation is to go back in the Neural Network and modify the weights

- Backpropagation is a technique used to train certain classes of neural networks – it is essentially a principal that allows the machine learning program to adjust itself according to looking at its past function.
- Backpropagation is sometimes called the “backpropagation of errors.”
- Backpropagation as a technique uses gradient descent: It calculates the gradient of the loss function at output, and distributes it back through the layers of a deep neural network. The result is adjusted weights for neurons.