SNN++ implements a single layer non linear Spiking Neural Network for images classification and generation.
The main idea behind a spiking neural network is that instead of real valued inputs, SNN process spatial and time-dependent input stream of 0s and 1s that more efficiently encode information. The network implemented here is a dense, feed-forward, single-layer, and unsupervized network that possess both generative and discriminative abilities.
The implementation was based on this paper and this python reference implementation. This implementation offers massive speed ups and an extensible shared library that can be used and embedded in other C++ or python applications. As well as offering additional visualization features
The network was trained and tested on the MNIST dataset, which is higher dimensional than the SEMION dataset the original paper and code were trained on. However, despite this additional challenge, the network was able to learn representations to all classes of the MNIST dataset out of 30 output neurons. Because this is a single layer SNN, we can use the weights to directly generate representations of these digits and reconstruct them into actual images. Some sample images are listed below:
30 neurons were able to learn all digits except the digit 4. With a little bit of tuning and data set augumentation (or adding more neurons) we could probably get it to learn 4.
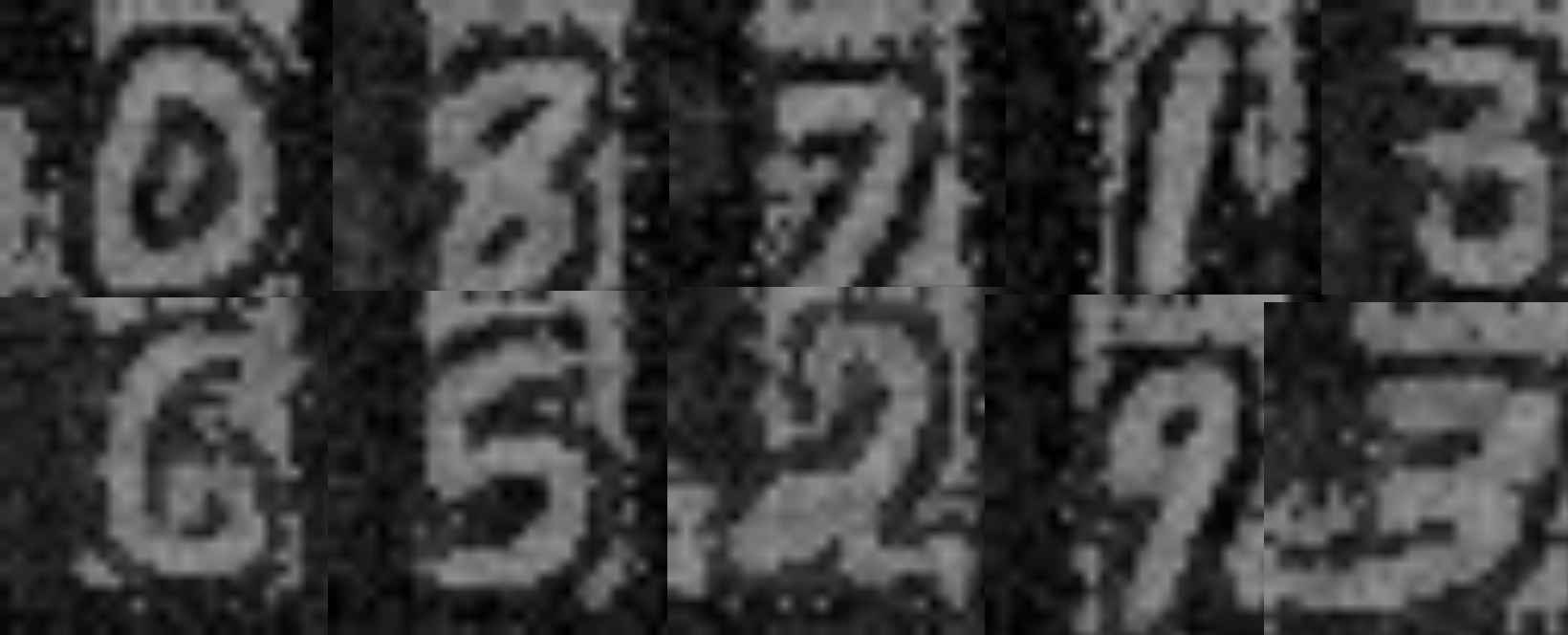
The evolution of the weights of each neurons as it goes through the training process

This implementation also saw massive ~2000% speed up over the paper's reference implementation. The following two tests were run on an M1 Pro with clang native arm64 compilation.
This implementation (C++):
╭─parvus at core in ~/dev/fun/snn on master✘✘✘
╰─± time build/snn
Processing epoch 0
[##################################################] 100%
Processing epoch 1
[##################################################] 100%
Processing epoch 2
[##################################################] 100%
Processing epoch 3
[##################################################] 100%
Processing epoch 4
[##################################################] 100%
build/snn 48.36s user 0.89s system 98% cpu 49.765 totalReference Implementation (Python):
╭─parvus at core in ~/dev/school/Spiking-Neural-Network on master✘✘✘
╰─± time python3 training/learning.py
100%|███████████████████████████████████████████████████| 1990/1990 [03:12<00:00, 10.35it/s]
100%|███████████████████████████████████████████████████| 1990/1990 [03:20<00:00, 9.92it/s]
100%|███████████████████████████████████████████████████| 1990/1990 [03:23<00:00, 9.78it/s]
100%|███████████████████████████████████████████████████| 1990/1990 [03:26<00:00, 9.63it/s]
100%|███████████████████████████████████████████████████| 1990/1990 [03:27<00:00, 9.61it/s]
python3 training/learning.py 1018.43s user 13.60s system 92% cpu 18:39.88 totalSNNPP has been tested on M1 based MacOS 12, 13 and Ubuntu 20.04 ARM & x86_64 Install dependencies:
opencv
cmake
make
g++ or clang
To build the project:
git clone https://github.com/ianmkim/snnpp.git
cd snnpp
mkdir build
cd build
cmake ..
makeTo run the unit tests
cd ..
build/unit_testsTo run the sample application
tar -xf mnist_set.tar.gz # decompress the included mnist dataset
build/snnAfter compilation, the shared library libsnnpp.dylib (or libsnnpp.so) will be created in the build directory. Use your compiler to link the library to use it in another application.
Starter code:
#include <iostream>
#include "network.hpp"
int main(int argc, char* argv[]){
// input x, input y, output layer dimension
Network net(28, 28, 30);
// for training
// path to the training data
// should be structured as this:
// mnist_set/
// category1/
// first_file.jpg
// second_file.jpg
// category2/
// category3/
// or...
// minst_set/
// img1.jpg
// img2.jpg
// ....
vector<string> data_paths = net.get_training_data("mnist_set", 500, true);
net.train(data_paths, 12, true, true);
// save the weights
net.save_weights("weights.dat");
// then load the weights
net.load_weights("weights.dat");
// generate images from the learned weights
net.reconstruct_all_weights();
// predict on an image
int res = net.predict("mnist_set/9/img_1.jpg");
cout << res << endl;
}You can either store the training images in a categorized or uncategorized manner since STDP is an unsupervized algorithm. It will not matter how its stored, but it must be stored in one of the two ways:
- categorized:
minst_set/
category1/
img1.jpg
img2.jpg
...
category2/
img1.jpg
img2.jpg
...
...
- uncategorized:
mnist_set/
img1.jpg
img2.jpg
img3.jpg
img4.jpg
...
The weights from the trained network can be stored as a txt file containing the weight values of the network.
The program has been tested for leaks using leaks for MacOS
Process: snn [9416]
Path: /Users/USER/*/snn
Load Address: 0x104fa0000
Identifier: snn
Version: 0
Code Type: ARM64
Platform: macOS
Parent Process: leaks [9415]
Date/Time: 2022-11-07 22:11:20.060 -0500
Launch Time: 2022-11-07 22:11:19.146 -0500
OS Version: macOS 13.0 (22A380)
Report Version: 7
Analysis Tool: /Applications/Xcode.app/Contents/Developer/usr/bin/leaks
Analysis Tool Version: Xcode 14.1 (14B47b)
Physical footprint: 8626K
Physical footprint (peak): 8626K
Idle exit: untracked
----
leaks Report Version: 4.0, multi-line stacks
Process 9416: 2041 nodes malloced for 427 KB
Process 9416: 0 leaks for 0 total leaked bytes.
src/
learning.cpp # weight adjustment code
network.cpp # implements network & training code
neuron.cpp # implements neuron code
receptive_field.cpp # implements image preprocessing code
spike_train.cpp # implements encoding code to convert inp to spike train
threshold.cpp # implements variable treshold for training
utils.cpp # various linear algebra & math utilsThe neurons implement the leaky integrate and fire model which models each neuron's membrane potential. Information is transmitted from one neuron to another by synapses with learned weights. The voltage is accumulated within each neuron and if it hits a certain threshold, the neuron fires and its potential returns to its resting potential (-70mV). The membrane potential at any given time is calculated as the sum of all excitatory and inhibitory signals coming into the neuron. There's also a refractory period during which the neuron cannot fire again. The tau values in the parameter determines the steepness of the potential increase and decrease.
Unlike a regular DLN, the input image cannot be fed into the model as its plain pixel values. Instead they must be converted into a spike train. The conversion happens through a convolution with a kernel inspired by the visual receptive field, which is a cone shaped volume which alters how sensitive certain optic nerves are. The convoluted image is then encoded into a 1 dimensional spike train and fed into the input neurons.
The learning follows principles of Spike-Timing-Dependent Plasticity (STDP) which is a Hebbian-esq unsupervized algorithm. The STDP equation models the change in synaptic weight based on the time between the presynaptic spike and the post synaptic spike. If the time difference is positive (meaning that it did not contribute to the spike) the synaptic weight is decreased and if the time difference is negative, the synaptic weight is increased. The functions themselves are an exponential growth and inverted exponential growth functions such that only the asymptote side of the y-axis is used for respective positive and negative time differences. The actual new weight values are limited by a weight min and max and is controlled by a learning rate term as well.

The prediction and training is done by simulating the response of the output layer of the network for 200 time steps.
The network also employs lateral inhibition as a strategy for unsupervized training. The neuron with the highest activity is selected as the winner then we suppress the membrane potentials of all other neurons in that layer.
There are multiple APIs that perform dot products. The regular templated dot function performs a loop through both vectors. It is a naive implementation
The array based dot function does the same thing except with heap allocated arrays. This is marginally faster.
The vector based dot_sse function uses Intel SSE SIMD intrinsics are used (with support for ARM NEON intrinsics as well with the help of the sse2neon.h library). We use the _m128 registers to multiply and sum multiple float values at the same time.
The array based dot_sse improves upon the vector based one by padding a heap allocated array with a multiple of 4 using realloc then memset-ing them with 0 until the end. This is much much faster than the vector based functions. However, they require interacting with dynamic memory allocation rather than using references.
We saw dramatic reduction in time spent doing dot products in the benchmarks. ~22% computation time decrease was achieved using arrays and SIMD intrinsics as compared to array based dot products with regular for loops.
The receptive field convolution was also optimized based on the dot_sse functions. Since the convolutions are just a bunch of dot products, we can utilize dot_sse by making array 1 the flattened version of the kernel and the other array a flattened version of the sliding window of the image. To accomplish this without inefficient branching if statements, we pad the original image by 4 rows and 4 columns.
We saw more than ~40% reduction between the naive loop receptive field convolution and SIMD intrinsics optimized convolution.