





Ecco is a python library for exploring and explaining Natural Language Processing models using interactive visualizations.
Ecco provides multiple interfaces to aid the explanation and intuition of Transformer-based language models. Read: Interfaces for Explaining Transformer Language Models.
Ecco runs inside Jupyter notebooks. It is built on top of pytorch and transformers.
Ecco is not concerned with training or fine-tuning models. Only exploring and understanding existing pre-trained models. The library is currently an alpha release of a research project. You're welcome to contribute to make it better!
Documentation: ecco.readthedocs.io
- Support for a wide variety of language models (GPT2, BERT, RoBERTA, T5, T0, and others) [notebook & instructions for adding more models].
- Ability to add your own local models (if they're based on Hugging Face pytorch models).
- Feature attribution (IntegratedGradients, Saliency, InputXGradient, DeepLift, DeepLiftShap, GuidedBackprop, GuidedGradCam, Deconvolution, and LRP via Captum)
- Capture neuron activations in the FFNN layer in the Transformer block
- Identify and visualize neuron activation patterns (via Non-negative Matrix Factorization)
- Examine neuron activations via comparisons of activations spaces using SVCCA, PWCCA, and CKA (See this video on inspecting neural networks with CCA)
- Visualizations for:
- Evolution of processing a token through the layers of the model (Logit lens)
- Candidate output tokens and their probabilities (at each layer in the model)
You can install ecco either with pip or with conda.
with pip
pip install eccowith conda
conda install -c conda-forge eccoYou can run all these examples from this [notebook] | [colab].

Use a large language model (T5 in this case) to detect text sentiment. In addition to the sentiment, see the tokens the model broke the text into (which can help debug some edge cases).

Feature attribution using Integrated Gradients helps you explore model decisions. In this case, switching "weakness" to "inclination" allows the model to correctly switch the prediction to positive.

Does GPT2 know where Heathrow Airport is? Yes. It does.
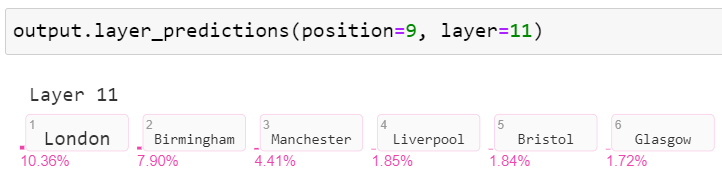
Visualize the candidate output tokens and their probability scores.

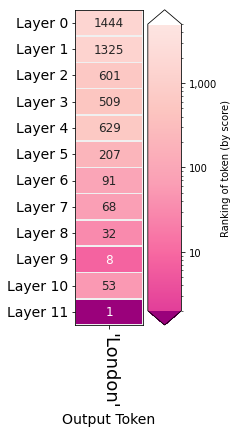
The model chose London by making the highest probability token (ranking it #1) after the last layer in the model. How much did each layer contribute to increasing the ranking of London? This is a logit lens visualizations that helps explore the activity of different model layers.

A group of neurons in BERT tend to fire in response to commas and other punctuation. Other groups of neurons tend to fire in response to pronouns. Use this visualization to factorize neuron activity in individual FFNN layers or in the entire model.
Read the paper:
Ecco: An Open Source Library for the Explainability of Transformer Language Models Association for Computational Linguistics (ACL) System Demonstrations, 2021
- Interfaces for Explaining Transformer Language Models
- Finding the Words to Say: Hidden State Visualizations for Language Models
The API reference and the architecture page explain Ecco's components and how they work together.
Predicted Tokens: View the model's prediction for the next token (with probability scores). See how the predictions evolved through the model's layers. [Notebook] [Colab]

Rankings across layers: After the model picks an output token, Look back at how each layer ranked that token. [Notebook] [Colab]

Layer Predictions:Compare the rankings of multiple tokens as candidates for a certain position in the sequence. [Notebook] [Colab]

Primary Attributions: How much did each input token contribute to producing the output token? [Notebook] [Colab]

Detailed Primary Attributions: See more precise input attributions values using the detailed view. [Notebook] [Colab]

Neuron Activation Analysis: Examine underlying patterns in neuron activations using non-negative matrix factorization. [Notebook] [Colab]

Having trouble?
- The Discussion board might have some relevant information. If not, you can post your questions there.
- Report bugs at Ecco's issue tracker
Bibtex for citations:
@inproceedings{alammar-2021-ecco,
title = "Ecco: An Open Source Library for the Explainability of Transformer Language Models",
author = "Alammar, J",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
year = "2021",
publisher = "Association for Computational Linguistics",
}