This project was developed Winter 2018
This project is my introduction to RL and safe RL. I develop two grid-world simulation and RL algorithms from scratch, with no ML or RL libraries, to experiment and test safety methods. After training and deploying the agents, I was able to achieve my goal. For every environment, the agent was capable of learning an optimal policy while staying safe.
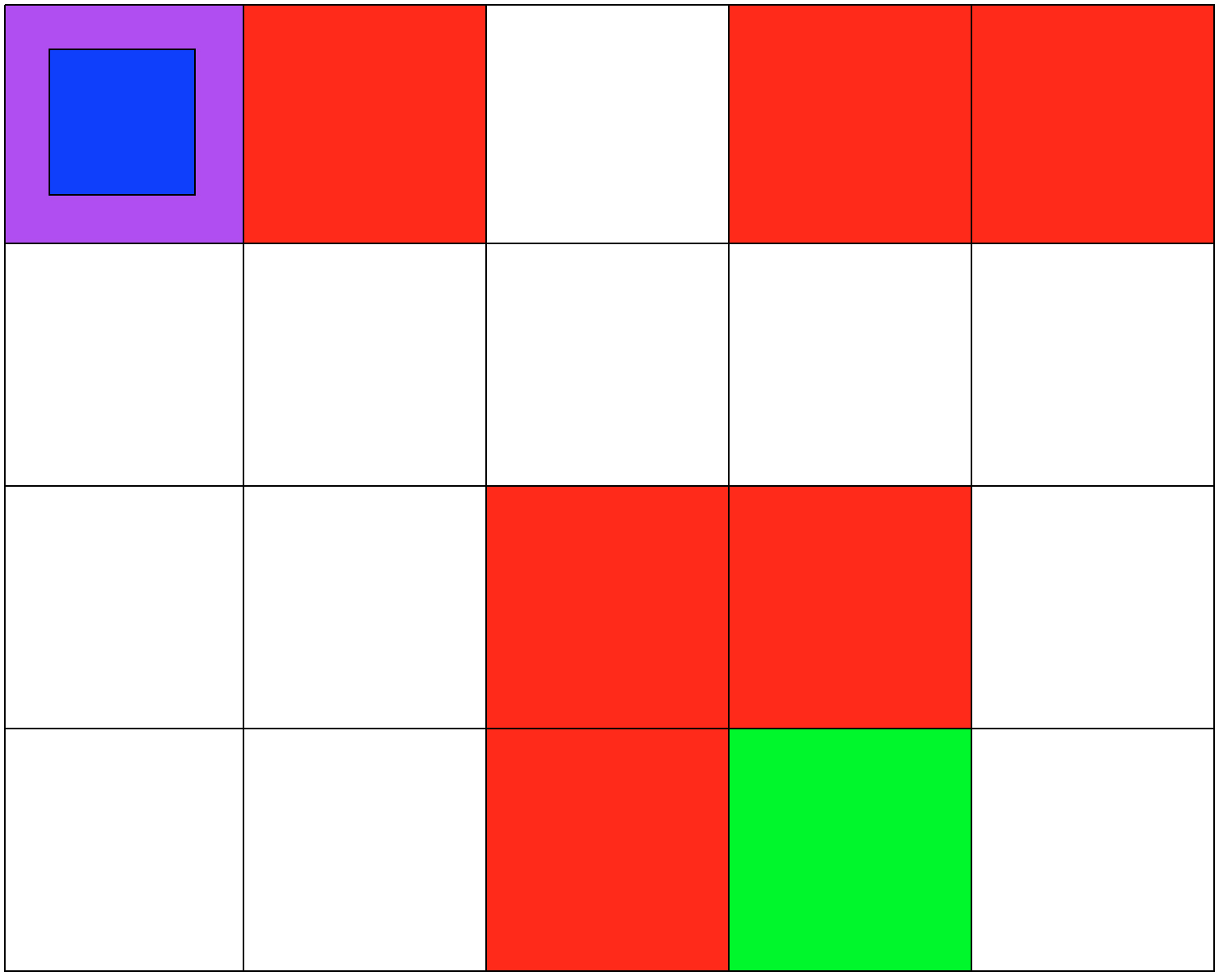
Both environments involve 5x4 grids limited by four borders. The agent can move from one grid to another by performing 1 out of 4 possible actions (Up, Down, Left, and Right). The first set of grid-world environments are Navigation simulations. It consists of a planetary robot (blue) looking to travel from a starting point (purple) to a specified target destination (green) while trying not to fall into craters (red).
The second set of grid-world environments are Mineral Collection simulations. It consists of a planetary robot (blue) looking to collect mineral ore (yellow) and bringing it back to its starting position (purple) while trying not to fall into craters (red). The agent will automatically pick up the ore when it reaches its location.

A list of all the prerequisites you'll need to run the experiments
Python
numpy
Files that will be used to generate each environment.
/env/input.txt
/env/input-2.txt
/env/input-3.txt
For each environment run the following code to reproduce the experiment. It will load the .txt file used to generate the environment, run a Q-learning algorithm and deploy the trained agent in the environment.
python3 grid-world.py < <path>/input.txt
python3 grid-world.py < <path>/input-2.txt
python3 grid-world.py < <path>/input-3.txt
python3 mineral-world.py < <path>/input.txt
python3 mineral-world.py < <path>/input-2.txt
python3 mineral-world.py < <path>/input-3.txt
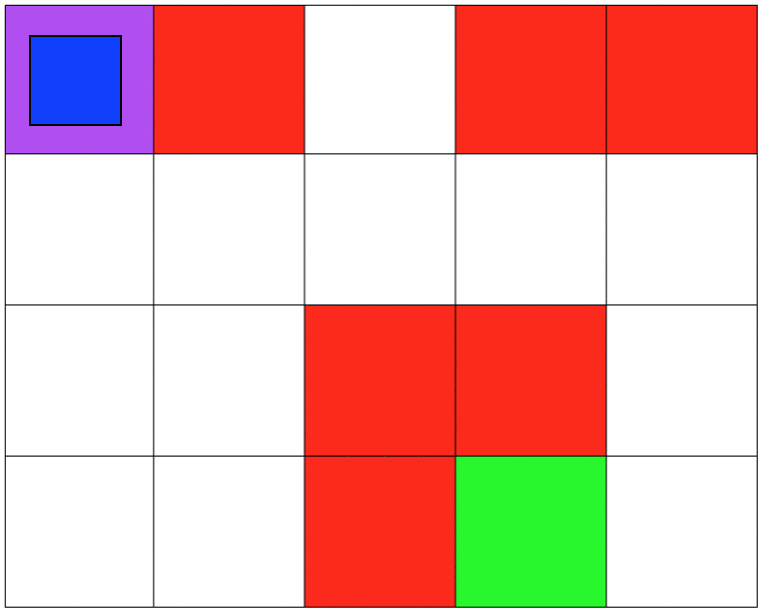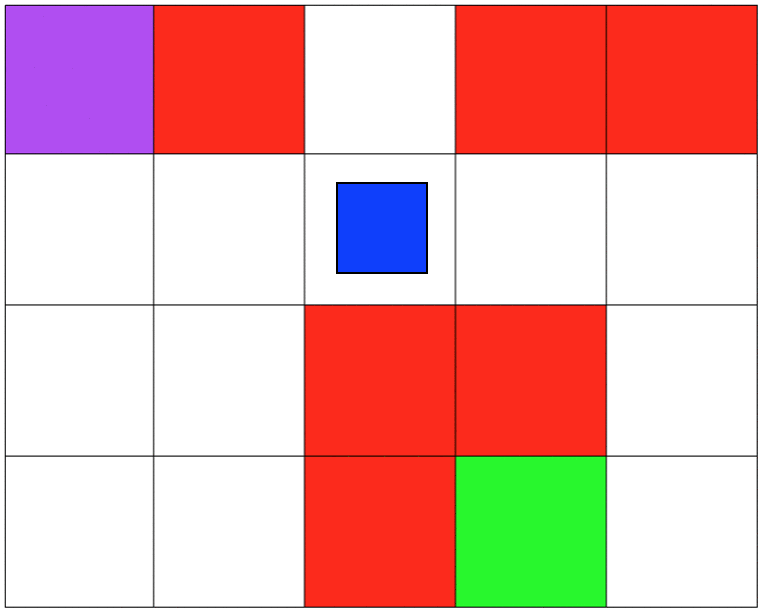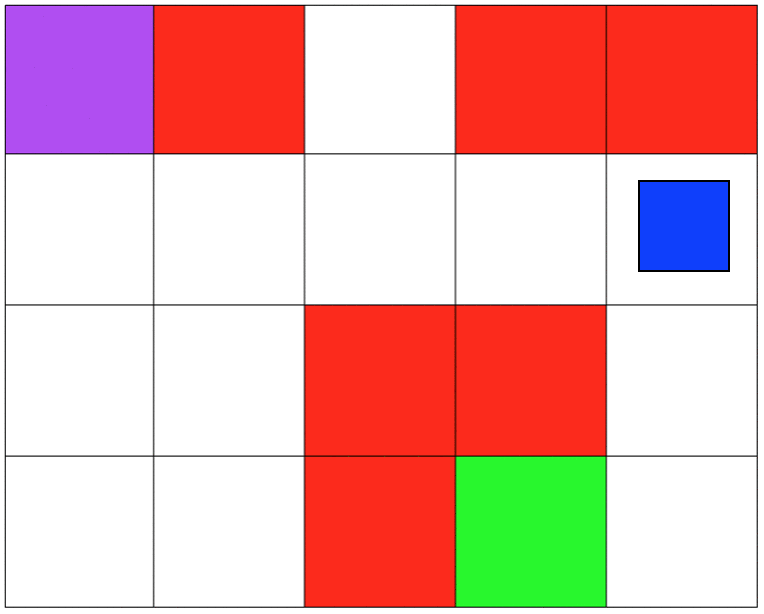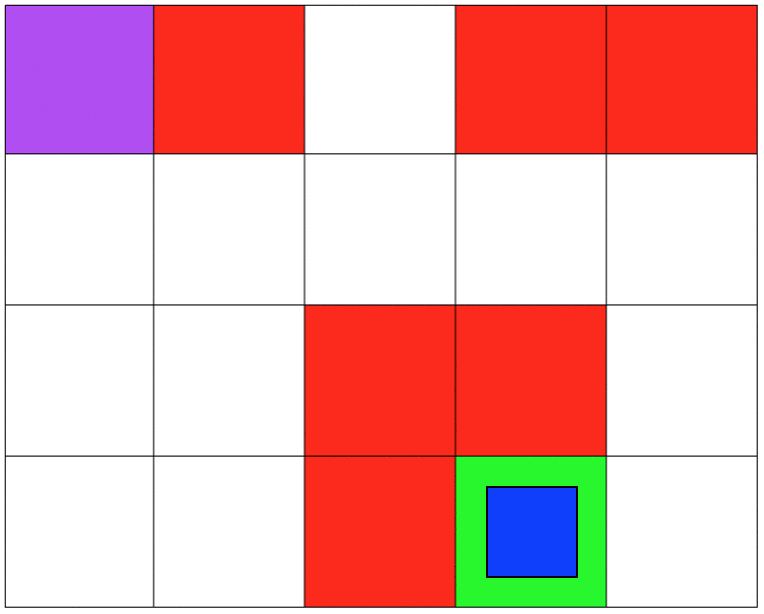
NAVIGATION DOMAIN:
from (0,0) -> move DOWN to: (0,1)
from (0,1) -> move RIGHT to: (1,1)
from (1,1) -> move RIGHT to: (2,1)
from (2,1) -> move RIGHT to: (3,1)
from (3,1) -> move RIGHT to: (4,1)
from (4,1) -> move DOWN to: (4,2)
from (4,2) -> move DOWN to: (4,3)
from (4,3) -> move LEFT to: (3,3)
You have found the minerals!
CONGRATULATIONS!
SAFETY DATA: Your Rover has fallen 0
time/s.
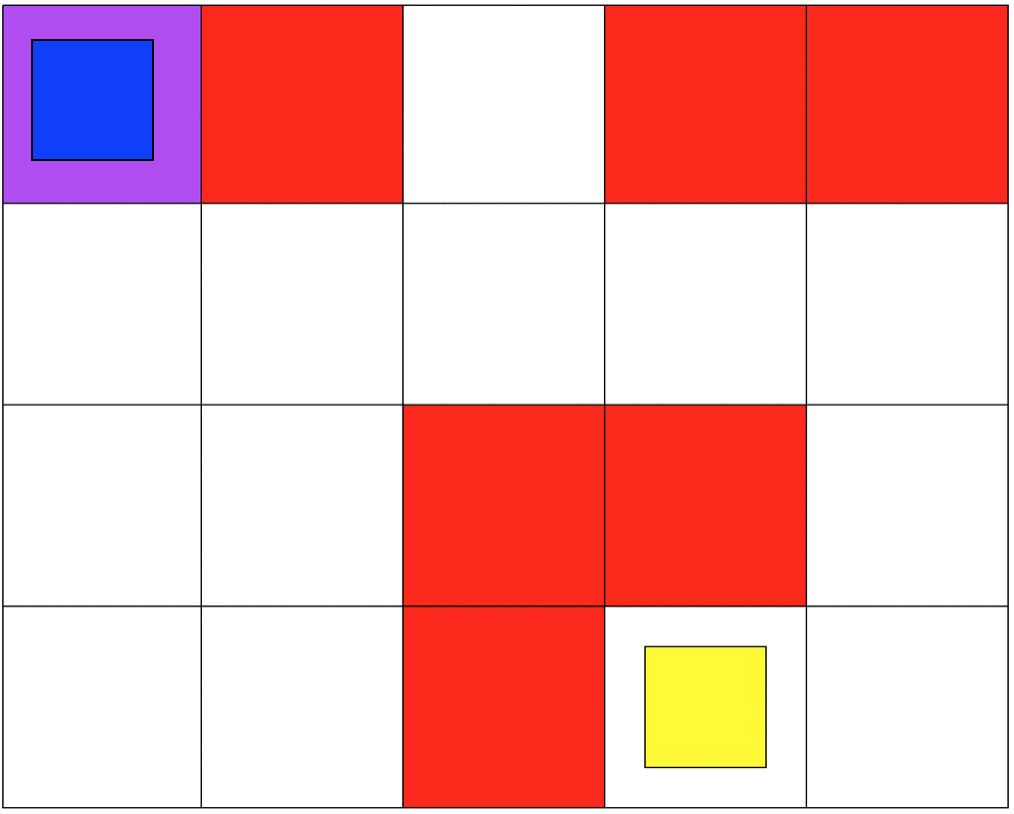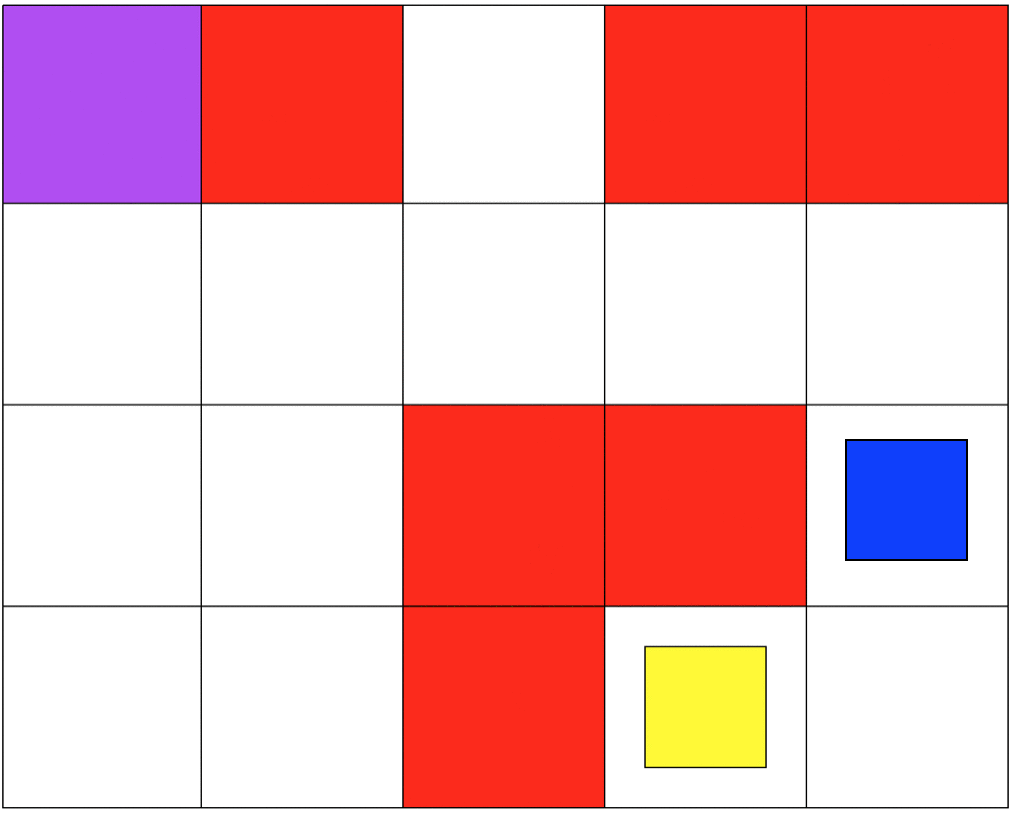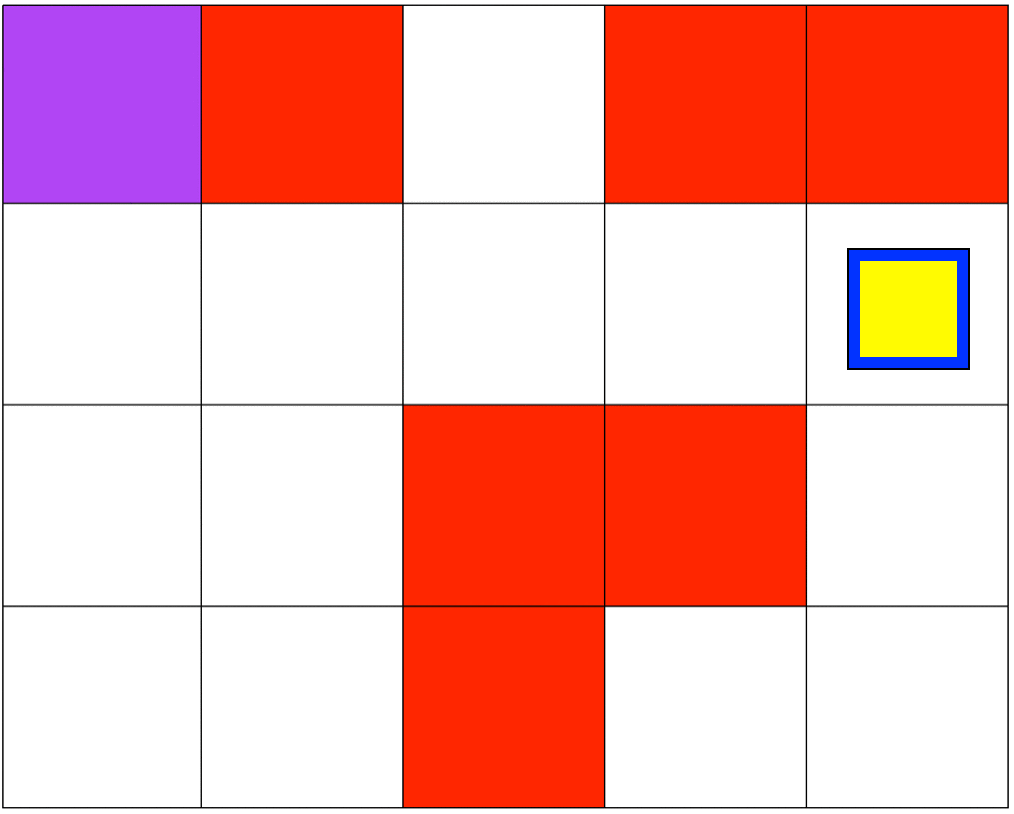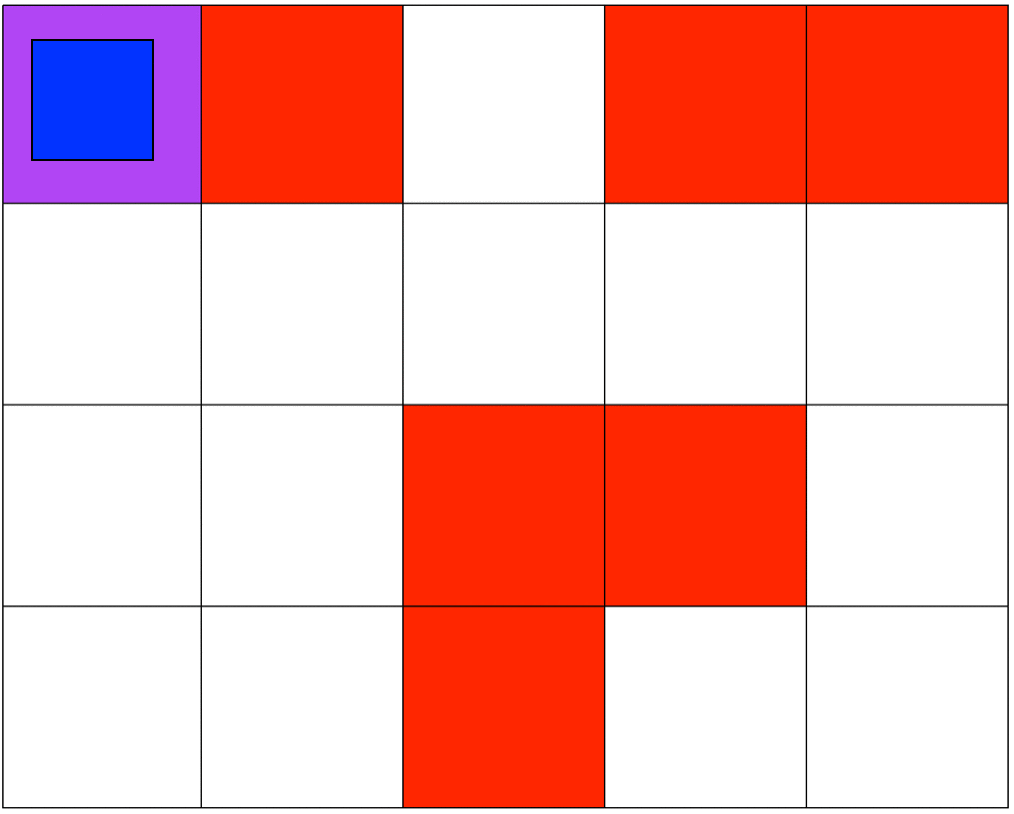
MINERAL COLLECTION DOMAIN
from (0,0) -> move DOWN to: (0,1)
from (0,1) -> move RIGHT to: (1,1)
from (1,1) -> move RIGHT to: (2,1)
from (2,1) -> move RIGHT to: (3,1)
from (3,1) -> move RIGHT to: (4,1)
from (4,1) -> move DOWN to: (4,2)
from (4,2) -> move DOWN to: (4,3)
from (4,3) -> move LEFT to: (3,3)
You have found the minerals!
CONGRATULATIONS!
from (3,3) -> move RIGHT to: (4,3)
from (4,3) -> move UP to: (4,2)
from (4,2) -> move UP to: (4,1)
from (4,1) -> move LEFT to: (3,1)
from (3,1) -> move LEFT to: (2,1)
from (2,1) -> move LEFT to: (1,1)
from (1,1) -> move LEFT to: (0,1)
from (0,1) -> move UP to: (0,0)
You are back in BASE with the MINERALS,
CONGRATULATIONS!
SAFETY DATA: Your Rover has fallen 0 time/s.
If you want to develop you own environment to test the algorithms you can generate a file with the following content:
1. n: Number of states, then the set of states to be considered will be [0, n-1]
2. m: Number of action, then the set of actions to be considered will be [0, m-1]
3. flag: {0,1} s.t. 1 if the environment is non-deterministic and 0 if it’s deterministic
4. 𝒔𝟎: Initial state of our agent
5. 𝒔𝒈𝒐𝒂𝒍: Goal state of out agent
6. [(𝒔𝟏, 𝒓𝟏), . . . , (𝒔𝒅, 𝒓𝒅)] : Set of state reward pairs, which indicated what reward will an
agent obtain if it where to land in state 𝑠i
7. [𝒔𝟏, . . . , 𝒔𝒌]: Set of unsafe states.
8. i: Number of iterations for Q-learning algorithm convergence.
9. T: 𝑛×𝑚, Transition Matrix s.t. for all states 𝑠 and action 𝑎, 𝑇[𝑠][𝑎] will indicate what
state should an agent go to if it’s currently in state 𝑠 and performs action 𝑎. If the
environment is non-deterministic this will be left empty.
10. 𝑷𝒂 𝒔𝒂 𝒔 : Probability distribution s.t. for all state-action pairs (𝑠, 𝑎), 𝑃; will return the
probability of ending in a successor state 𝒔𝒂 after performing