

by Justin Lok
Welcome to the Pokémon card scanner that can use any video input such as webcam or phone camera to scan a card or multiple cards real-time and identify them against the complete database of currently about 20,000 English Pokémon cards. It is able to identify all types including holos, reverse holos, full art cards, etc. purely via deep learning and imaging techniques. No OCR (text recognition) is used.
This is a working proof of concept built in Python with the goal of integrating it as a feature into my React Native Pokémon card collection tracking app. Some sample code is provided for read-only.
There are 3 main steps in the process that I focused on:
- Object Detection and Segmentation - Find the cards
- Perspective Transform - Process the cards
- Image Hashing - Match the cards
I trained a deep learning model to do the detection phase. Object detection models typically only locate the item with a bounding box in the image, or in other words, a rectangular frame that contains the object. Unless the card is viewed perfectly straight, the bounding box contains too much other content from the background. We need to take this a step further and find not just the bounding box, but the exact pixels representing the card, also known as the segmentation mask.
After evaluating several different segmentation-capable models, I found RTM-Det to be the most viable for this situation since it is very fast based on benchmarks and ideal for mobile deployments. It’s also not bound by restrictive licenses as many other models are in the Yolo family, which is important if I were to use it in my own closed-source projects. RTM-Det also performs instance segmentation (as opposed to just semantic segmentation) which is capable of assigning a separate mask to each detection which is what I need.
Training
I generated a training dataset of 50,000 images by repeatedly compositing 2-5 random card images onto a random background. Some skew, rotation, scaling, and overlap was applied to each card to provide variance and mimic real life scenarios. Early iterations of the model were trained on a dataset of only 5,000 images having 1 card each, limiting its versatility. The larger dataset and fewer epochs helped to greatly improve the model's precision and ability to generalize. I also omitted common and uncommon cards to steer the dataset towards more rare types like full art cards that are more likely to be scanned by users and also don't have a simple yellow border. Only 1 class is needed, “card”.
Training time for 20 epochs was about 40 hours though after about 10 epochs, accuracy noticeably decreased as the model suffered from overfitting to the training data. The model achieved a segmentation mask mean average precision (mAP) of .90, which is extremely good. I believe the very regular shape and smooth edges of the cards have a lot to do with the unusually high mAP.
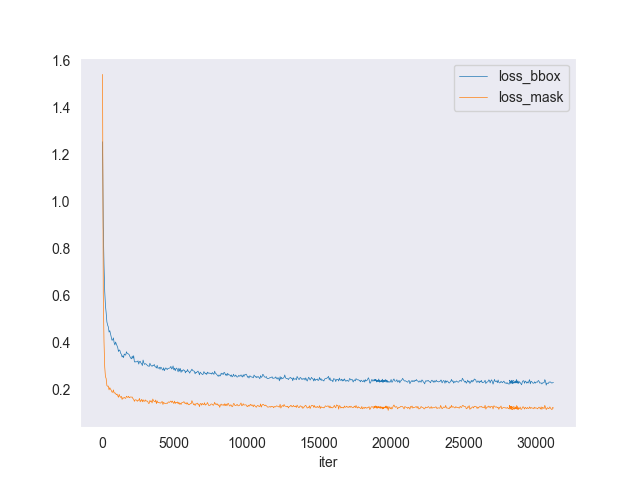
The following chart shows the training log of loss (lower is better) which is the difference between the prediction and actuality. The model improves incredibly fast then levels off, again likely due to the very simple shape of the cards.
Examples of training images with segmentation annotations drawn:

|

|

|

|
You can see clear improvements in the inference results after training optimizations for the model to be very accurate with high confidence scores (top right) and it can even predict edges of cards that are partially occluded (bottom right).
 |
 |

|

|
I also integrated a simple object tracking algorithm, SORT, to track objects between frames and avoid rerunning the subsequent matching process on cards already previously matched.
The model outputs a segmentation mask of each detected object. We need to isolate the card from the rest of the image based on the mask and correct its orientation and any skewing so we can compare it to the database.
A segmentation mask is a matrix grid with dimensions matching the image dimensions in pixels. Each index contains a binary integer representing whether or not that pixel is part of the object detected. We pass each mask to OpenCV and use edge detection and contouring to isolate the card out of the original image. Since we expect cards to be a rectangle with four straight edges, we can filter out any detections that have more or less than four edges. The four corners of the card are identified and pulled to reach the corners of the image canvas. This is perspective transform. A card that was skewed or crooked has been corrected to appear as if it is being viewed perfectly straight on. The card image is also oriented to portrait in this process. It may or may not be upside down, but we can worry about that later.
Now how can we take the processed card image and find its match in the database? A blurry image pulled, stretched, and with some inconsistent lighting will never perfectly match pixel to pixel with the official digital glam photos. The solution is image hashing. We use an algorithm to hash an image into a hexadecimal string which is stored in a database and compared using a hamming distance formula. Images that are visually similar will have similar hashes. Small changes to an image will result in only small changes to its hash. This is different from cryptographic hashing such as with passwords where small changes to your input can and will result in big or even complete changes to your output so it will be indiscernible.
Using only a single hashing algorithm at a 16 byte length results in too many hash collisions when using such a large database of almost 20,000 cards. Two cards may not look similar to us, but still end up with similar hash strings. To solve this issue, I combined two different hashing algorithms together, difference hash and perceptual hash, and increased the hash length of each. Combining two algorithms together eliminates issues with a single algorithm resulting in similar hashes for non-similar cards. 32 byte length provides double the granularity over 16 byte as there is more data to compare.
Using a simple hamming distance formula, hash strings are compared and, within a given threshold, the pair with the most similarities is returned as the match. We can handle possible upside down cards here by rotating the card image 180 degrees and hashing it again if no match was found. The threshold is adjusted to provide a good balance between allowing some interference such as glare, overlap, fingers over cards, etc. while not returning too many false matches.


I combined the versatility of a machine learning model with the speed of OpenCV and Image hashing to create a fast and accurate trading card scanner. When new cards are released, the hash database is easily updated while the model and all detection logic remains unchanged. The database used in this demo only consists of Pokémon cards but can easily be expanded to include any other types of trading cards and even other types of products as well.
✅ Deployment to TFlite Part of the next steps of integrating the scanner into a React-Native mobile app is deploying the ML model as a TensorFlow Lite model. TF Lite is designed to be lightweight for mobile devices and provides APIs for hardware acceleration. Converting a model from PyTorch to TF Lite involves first converting from PyTorch to Onnx format, Onnx format to TensorFlow, then TensorFlow to TF Lite. I have completed this step of converting my model to TF Lite but it remains in float32 datatype format.
🚧 Quantization One challenge I have had is model quantization, a technique to reduce the memory usage and speed up inference by converting the model from using higher precision float32 numbers to lower precision int8. Quantization is instrumental to getting the model running fast and efficiently on mobile devices. I've already tried quantization as an Onnx model, TF model, and TF Lite model but the processes either fail or the quantized model gives incorrect results. I believe the high complexity of RTM-Det and especially the post-processing steps is incompatible with the post-training quantization through those respective APIs. Work in progress as I explore other ways to solve this issue.
☐ Implement VP Tree Finding a match for the hash strings in the database is currently O(n) time complexity using a simple for loop. I decided after testing that it is not important to optimize this step for the proof of concept. When the project is ported and integrated into a React-Native app, I will implement a VP tree to facilitate the database search which is O(nlogn) time complexity.
☐ Port to C++ I will convert all of the relevant Python code to C++ in order to integrate this scanner into a React-Native mobile application.
During testing, I found OpenCV edge detection has difficulty detecting cards in less-than-ideal scenarios such as not enough or too much light, glare, or cards against a similar colored background. It also had a lot of trouble with cards without a clearly defined border such as full art cards. This would give a very poor user experience. My deep learning model overcomes these difficulties and is even able to predict edges of cards that are partially occluded.
This would mean training a model not on a single class as I did, but on almost 20,000 classes, one for each card. Even at a mere (and likely inadequate) 1000 images per class/card, that would equal a huge training dataset of 20 million images. Not only that, but each time new cards are released, the model would need to be retrained on those new cards and redeployed. Inference with large models requires enormous amounts of memory and compute and may still take several seconds to produce a result. Both inference and training time would be unreasonably long.
Remember, the goal of this project is to be able to run on-device inference real-time directly on mobile, not with some delay through a remote server. The model plus the rest of the scanning process must be as light and as fast as possible to run at least a few frames per second to provide a good user experience.