z2jh 0.10.6 scale test failure with kube-scheduler v1.19.2 #2025
Comments
|
I realize that latest z2jh is using kube-scheduler 1.19.7 so that would fix the issue for us if we upgraded to the latest z2jh, but if possible it'd be good to fix this on the 0.10.x series for those that aren't jumping straight to the 0.11.x series (like us). We have a large user event happening in a couple of weeks so I'm trying to be conservative with the changes that we roll out to our production cluster before that event happens. For now we've got our fix in our helm chart, but it'd probably be good to patch the z2jh 0.10.x series with kube-scheduler (at least) 1.19.5 for anyone else that upgrades to the 0.10.x series and hits the same problem (like Matthew Brett above). |
|
If a 0.10.7 release isn't an option then maybe at least calling out the known issue in the docs is an alternative. |
|
Thanks for the writeup! Is the only required change for 0.10.6 What do you think about writing up a post on https://discourse.jupyter.org/ with this fix instead? It's more likely to be seen there, and I also think your testing process would be of interest to others. |
Yes, in this case. I also ran into jupyterhub/kubespawner#466 but that's a different issue which is already fixed in kubespawner 0.15.0 and that's picked up in z2jh 0.11.0.
Yup, good point.
Since I've already got a fix and am mostly trying to raise awareness on this, yeah I agree mentioning it in the forum is a good alternative, I'll do that and then close this issue. |
|
This is an amazing writeup @mriedem!!!! Thank you soooooooooooooooo much for doing this investigation!!!! ❤️ 🎉 I love that the issues @matthew-brett reported can be pinned to a reason, because I were really clueless about them! Nice work tracking this down all the way to kube-scheduler! Concrete action points that come to my mind:
|
|
FWIW, my second run of the scale test, to go from 1K to 2K active user notebook pods, started hitting failures around 1830 total active user pods. The hub restarted twice during that second run. There were no restarts of the user-scheduler pods. Unfortunately while this run was going on there is an issue with IBM's LogDNA service so I don't easily have an idea of what the hub errors were, but I'm assuming they were crashes due to reaching the consecutive spawn failure limit. Another thing I noticed is that the user-placeholders didn't dip as much as I'd expect when adding 1000 user pods, this is current: And a handful more of user nodes were scaled up, so it seems the issues with the placeholder pod pre-emption is not totally gone with that kube-scheduler fix. I was looking at #1837 and wondering if that might be affecting this but it's a bit over my head on how it could change the behavior from what we had working before (with z2jh 0.9.0-n212.hdd4fd8bd). |
|
@mriedem does @mriedem I concluded that 0.9.0-n246.h3d6e7579 introduced a new system in #1778. Before that, kube-scheduler v1.16.11 was used. 0.9.0-n212 was released 04 September 2020. Backtracking in time what 0.9.0-n212 was using, was the old kube-scheduler version of v1.16.11, and the old configuration of it as well. How we started kube-scheduler How we configured kube-scheduler {
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{ "name": "PodFitsResources" },
{ "name": "HostName" },
{ "name": "PodFitsHostPorts" },
{ "name": "MatchNodeSelector" },
{ "name": "NoDiskConflict" },
{ "name": "PodToleratesNodeTaints" },
{ "name": "MaxEBSVolumeCount" },
{ "name": "MaxGCEPDVolumeCount" },
{ "name": "MaxAzureDiskVolumeCount" },
{ "name": "MaxCSIVolumeCountPred" },
{ "name": "CheckVolumeBinding" },
{ "name": "NoVolumeZoneConflict" },
{ "name": "MatchInterPodAffinity" }
],
"priorities": [
{ "name": "NodePreferAvoidPodsPriority", "weight": 161051 },
{ "name": "NodeAffinityPriority", "weight": 14641 },
{ "name": "InterPodAffinityPriority", "weight": 1331 },
{ "name": "MostRequestedPriority", "weight": 121 },
{ "name": "ImageLocalityPriority", "weight": 11}
],
"hardPodAffinitySymmetricWeight" : 100,
"alwaysCheckAllPredicates" : false
}Currently, for anyone in k8s 1.16+, we use kube-scheduler 1.19.7 and... - /usr/local/bin/kube-scheduler
# NOTE: --leader-elect-... (new) and --lock-object-... (deprecated)
# flags are silently ignored in favor of whats defined in the
# passed KubeSchedulerConfiguration whenever --config is
# passed.
#
# ref: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/
#
# NOTE: --authentication-skip-lookup=true is used to avoid a
# seemingly harmless error, if we need to not skip
# "authentication lookup" in the future, see the linked issue.
#
# ref: https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/1894
{{- if .Capabilities.APIVersions.Has "storage.k8s.io/v1/CSINode" }}
- --config=/etc/user-scheduler/config.yaml
- --authentication-skip-lookup=true # plugins ref: https://kubernetes.io/docs/reference/scheduling/config/#scheduling-plugins-1
plugins:
score:
disabled:
- name: SelectorSpread
- name: TaintToleration
- name: PodTopologySpread
- name: NodeResourcesBalancedAllocation
- name: NodeResourcesLeastAllocated
# Disable plugins to be allowed to enable them again with a different
# weight and avoid an error.
- name: NodePreferAvoidPods
- name: NodeAffinity
- name: InterPodAffinity
- name: ImageLocality
enabled:
- name: NodePreferAvoidPods
weight: 161051
- name: NodeAffinity
weight: 14631
- name: InterPodAffinity
weight: 1331
- name: NodeResourcesMostAllocated
weight: 121
- name: ImageLocality
weight: 11 |
@mriedem Hmmm... that reads to me that 105 user-placeholder pods are pending or similar and that there were massive amounts of available seats for real users. Were there real user pods in a pending state at this point? I wonder if there is a limit on how much eviction can happen in a short amount of time and such. I think when the scheduler concludes it schedule a pod it will ask something else if a lower priority pod could be evicted to make room for the real user pod rather than doing that itself. I'm not sure about this though, but it would be very relevant to better diagnose this issue to understand how the schedulers decision leads to evictions. Hmmm... @mriedem have you inspected the resource requests on the scheduler also btw? If it fail to keep up with attempts to schedule, eviction won't happen fast enough either. Perhaps having more user-scheduler pods or more resources allocated to them will help? |
Got the logs back, it was what I suspected, consecutive spawn failure limit being reached:
Also seeing some of these, not sure what those might becoming from:
After stepping away for a bit here is where the placeholder stateful set is at: I don't see any pending real user pods:
Maybe, I can try scaling up the user-scheduler replicas. Here is what we have currently (though I don't have a scale test running at the moment): The resource requirements are the same as from default z2jh: I did see these events when describing the statefulset/user-placeholder: Checking some logs on that first pod I see this: So maybe the run up to 1000 real users was OK but the next step up to 2000 users maybe tipped something over in the scheduler trying to account for where all of the other pods are located across what is now 80 user nodes? IOW, as we add more users the scheduler is working harder and making mistakes. |
|
Also regarding user-scheduler deployment resources, during the last scale up runs the user-scheduler pods didn't seem to break a sweat:
|
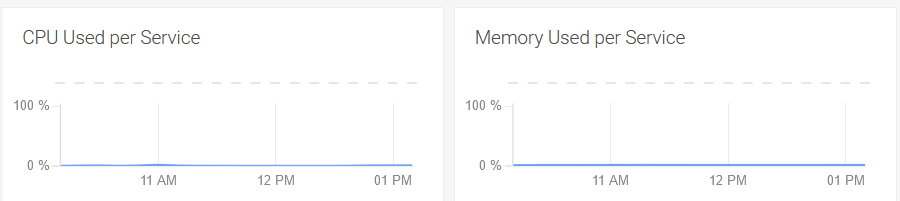

|
I should maybe note that our deployment only uses a single user notebook image and our singleuser pod resource specs on those in our pre-prod and production clusters are: However, in our testing cluster (where I'm doing the scale testing) the singleuser pods have this profile: {
"display_name": "micro",
"slug": "micro",
"description": "Useful for scale testing a lot of pods",
"default": true,
"kubespawner_override": {
"cpu_guarantee": 0.015,
"cpu_limit": 1,
"mem_guarantee": "64M",
"mem_limit": "1G"
}
}But the placeholder pod template in all environments is this: So in the scale tests we end up having a lot of those micro pods and I've really inflated the number of user nodes since I scaled up the placeholder replicas to 2000. So I'm not surprised that I'm seeing I'm going to scale the placeholder replicas down to 1000, deploy the hub with kubespawner 0.15.0, purge the existing singleuser notebook pods and then redo the scale test. |
|
@mriedem ooooh but hey! These are the defaults of the user-scheduler's resource requests I think!! It can very well be throttled. scheduling
userScheduler:
resources:
requests:
cpu: 50m
memory: 256MiCan you try increasing the request or limit of CPU? I think it won't matter adding replicas as it seems that only one is taking the load pretty much. It can also be that the k8s-apiserver is failing to respond quickly enough and that is throttling things. There are plenty of things that could bottleneck scheduling:
# get pending real-user pods
kubectl get pods -l component=singleuser-server -o json | jq -r '
.items[]
| select(.status.phase == "Pending") | .metadata.name
' | wc -l |
|
This issue has been mentioned on Jupyter Community Forum. There might be relevant details there: https://discourse.jupyter.org/t/scheduling-errors-with-z2jh-0-10-x/7826/1 |
Investigation and misc...kube-scheduler will not consider all nodes
https://kubernetes.io/docs/concepts/scheduling-eviction/scheduler-perf-tuning/ kube-scheduler's post-filter plugin does the pre-emption / eviction It seems that kube-scheduler is doing the pre-emption / eviction itself as part of a post-filter plugin. Filters are ruling out nodes for scheduling, so the default-preemption post-filter plugin will probably trigger if there was no node to schedule on at all. At that point, it will pre-empt a pods with lower priority on nodes to accomplish its goal of making room for the pod it wants to schedule. Overview of kube-scheduler configuration / plugins etc https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/ Off topic idea to solve another issue There is an issue about user pods being scheduled on freshly booted nodes without images pulled when there were nodes with warm seats but that were full because user-placeholders hogged the room. In thos situations, it would be preferably to evict a user-placeholder pod to allow room for a user pod on the older node with images pre-pulled already. If we could make a plugin that deletes a scheduled user-placeholder pod for each real user pod to be scheduled, we could solve this I think. This assumes the scheduler will sort the pods based on priority before trying to scheduled them as well, which it does. |
|
An update before I drop off for the weekend. I made some changes:
This time I scaled up the placeholder pods to 2400 to get 24 user nodes to start. I also watched the user-scheduler top usage. Again there were placeholder pods being evicted but apparently not fast enough because more user nodes were added by the auto-scaler. Placeholder pods got own to ~1700 but then started going back up as the new user nodes were added. It almost seems like the scheduler is competing between adding user nodes for the placeholder pods to satisfy the stateful set and the actual user pods which have higher priority. One of the user-scheduler pods hit a probe failure and was restarted.
Average user-scheduler pod core usage was around .3:
The hub crashed a couple of times due to consecutive pod spawn failure limits being reached:
I think that's just due to contention between the user pods and the placeholder pods and the pre-emption not working like we'd expect. To try and cut off the placeholders I scaled those down to 1000 so the user pods could take over. At that point I was up to 33 user nodes. The hub API response times are all less than 1s on average as well. Now that the run is done here are the user pod stats: So over 250 failed to spawn. The hub was restarted 4 times: The user-scheduler pods restarted once: Looks like this is the error from the user-scheduler pod that crashed: Next steps for me are to go through the notes/links in the comment above. |
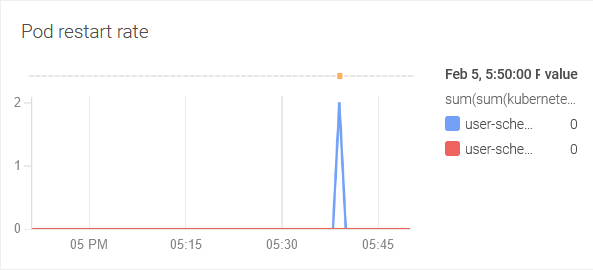
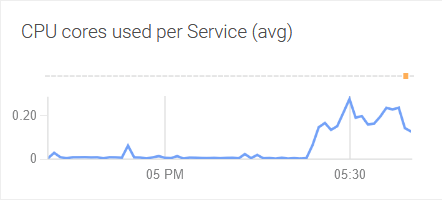
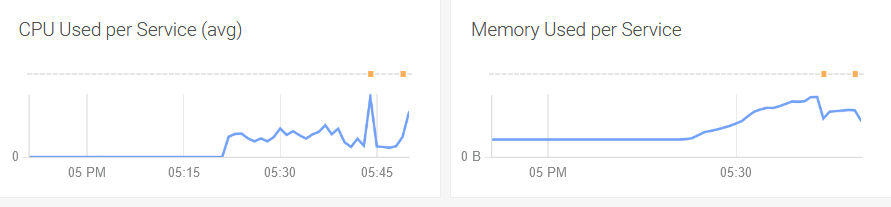
|
One thought that came to mind is we are currently using the same resources for the user-placeholder pods as our singleuser notebook pods, but do people generally create fewer placeholder replicas but make them larger? We had a large user event last year where the scheduler and auto-scaler didn't seem to be packing singleuser pods like we expected so we changed the size on the placeholder pods to be much larger which then evicted them and freed up space on the user nodes for the singleuser pods. |
That might be kubernetes/kubeadm#2284 but it looks to be fixed in 1.19.5: So I'm not sure why we'd be hitting that since we upgrade kube-scheduler to 1.19.5. Unless I misunderstand where that fix gets applied and we just haven't done it yet. |
|
It would be interesting to see some kube-scheduler metrics. Perhaps that could give some insights as well. Googling I found some grafana dashboard definitions: https://grafana.com/grafana/dashboards/12130/reviews But, the user-scheduler needs to have a service targeting it with annotations to promethus scrapes from it, and, it needs to have ports opened for scraping. Also, not confident about how this will be influenced by the fact that we have two scheduler pods in a leader election setup, will sometimes one reply saying its calm and easy, while othertimes the other reply saying it is very busy? https://help.sumologic.com/Metrics/Kubernetes_Metrics#scheduler-kube-scheduler-metrics
I note that there are significant time delays between various errors here, and only the last two lines could have been the cause of the restart I think. |
|
To sort of close the loop on our placeholder eviction problem, @rmoe did some testing and found that with a much larger placeholder pod (8GB memory) and far fewer placeholder replicas we were able to scale up to our previous expected numbers (3K singleuser pods) without hitting spawn failures, the user node auto-scaler kicking in, or the hub crashing. Must be something about the K8S scheduler in newer releases (1.18+) because it was packing more placeholders on a user node but not evicting them to make room for singleuser pods when those pods were the same size, or maybe it was not evicting fast enough while trying to scale back up the placeholders before the auto-scaler kicked in. |
|
@mriedem thank you so much for reporting back this hard gained experience!!! Configuring user-placeholder resources Here is the code where the resources are set, by referencing a complicated helper function not considering the Another workaround idea By using larger placeholder pods you reduce the performance required by the user-scheduler and the k8s api-server it interacts with. I wonder what is bottlenecking, it could be that the user-scheduler in its new form is making more requests than before, and due to that is throttled. Consider for example With this in mind, I wonder how much k8s api-server requests and such are made given various configuration of the kube-scheduler binary. What if we configured it to be a bit more crude in how it schedules pod in order to reduce the amount of requests made? More concretely, what would happen if changes introduced with 0.10.0 were reverted to some degree, what if we instead of enable a larger set of node scoring plugins only used one single. scheduling:
userScheduler:
enabled: true
replicas: 2
logLevel: 4
# plugins ref: https://kubernetes.io/docs/reference/scheduling/config/#scheduling-plugins-1
plugins:
score:
disabled:
- name: SelectorSpread
- name: TaintToleration
- name: PodTopologySpread
- name: NodeResourcesBalancedAllocation
- name: NodeResourcesLeastAllocated
# Disable plugins to be allowed to enable them again with a different
# weight and avoid an error.
- name: NodePreferAvoidPods
- name: NodeAffinity
- name: InterPodAffinity
- name: ImageLocality
# What if we never enable the NodeAffinity, InterPodAffinity, ImageLocality again?
# I suspect InterPodAffinity and/or ImageLocality could cause a significant performance hit in practice.
enabled:
- name: NodePreferAvoidPods
weight: 161051
- name: NodeResourcesMostAllocated
weight: 121 # These are enabled by default
enabled:
- name: NodePreferAvoidPods
weight: 161051
- name: NodeAffinity
weight: 14631
- name: InterPodAffinity
weight: 1331
- name: NodeResourcesMostAllocated
weight: 121
- name: ImageLocality
weight: 11 |
@rmoe has been editing the user-placeholder stateful set manually. We think we might have a workaround though by using a default profile via |
|
@yuvipanda do you have references to your work with using user placeholder's for entire nodes? I recall that you had managed to improve performance by using fewer and larger user placeholders that fit entire nodes instead of having many smaller, and that we concluded it was good for other reasons as well. For example, one would never end up with a node that is partially full with user placeholder pods etc but always manage to pack nodes full of real users. I figure I'll write an issue about this in this repo and try to cover the discussion regarding the choice of having user-placeholders vs node-placeholders and consider how we make it easy for users to work with node placeholders in this repo. I wonder if we can manage to get node placeholders with strict anti-affinity or similar and nodeSelector labels rather than specific resource requests? I'd like to deliberate a bit on that in a dedicated issue anyhow, having a reference to your past work on it would be great! |
|
I spoke with @Ryan-McPartlan about scaling issues and wanted to tag Ryan here for visibility. Also, @yuvipanda has discussed using "node placeholder" pods instead of "user placeholder" pods, as well as relying on for example GKE's pod scheduler instead of deploying one of our own. |
Bug description
Yesterday I upgraded our testing environment cluster from z2jh 0.9.0 to 0.10.6. This is on IBM Cloud's Kubernetes service and running Kubernetes 1.18.5. There is nothing very magical about this deployment, we have a custom authenticator but that's about it. All user notebook pod storage is backed by an s3fs object store rather than PVCs. And we're using placeholder pods for scaling and preparation for scheduled large user events to scale up user nodes etc.
Before promoting the change to our pre-production cluster I wanted to run a scale test of 2000 active user notebook pods using https://github.com/IBM/jupyter-tools. I started by scaling the user-placeholder replicas to 2000 which created ~71 additional user nodes (the actual profile we use on the pods in the testing cluster are a much smaller resource footprint so I probably would have been fine with 1K placeholders to scale up the user nodes, but alas).
Then I ran the
hub-stress-testscript with-c 2000which will create 2000 users and then start the notebook servers (pods) in batches of 10. When the scale test got to around 500-600 active user pods I was seeing a lot of timeout failures and consecutive spawn failures in the hub logs which was causing the hub to crash, e.g.:Later I also noticed that it didn't appear that the placeholder pods were being pre-empted so I started digging into the user-scheduler pod logs and saw this:
Feb 4 19:58:30 user-scheduler-6c4d89654-hgrqd user-scheduler fatal fatal error: concurrent map writesAnd there were a lot of restarts of the 2 user-scheduler pod replicas:
Resources were not an issue for the user-scheduler pods:
Eventually I found this Kubernetes issue kubernetes/kubernetes#96832 which says it was introduced in 1.19, and I didn't think that applied to us since we're running Kubernetes 1.18.5. But then I noticed that z2jh 0.10.6 is using kube-scheduler 1.19.2 per 39e0cd5.
So the next thing to try was the backport for that Kubenertes issue: kubernetes/kubernetes#96809
That's in kube-scheduler 1.19.5: https://github.com/kubernetes/kubernetes/blob/v1.19.5/pkg/scheduler/framework/plugins/volumebinding/volume_binding.go
So I upgraded the kube-scheduler version to be
v1.19.5in our helm chart:I then ran our scale test back up to 1K users and then another 1K after that, so far so good and the user-placeholder pods were being pre-empted during the scale test as expected:
Furthermore there are no errors in the user-scheduler logs.
Expected behaviour
Should be able to scale up our environment to 2000 or more with z2jh 0.10.6.
Actual behaviour
See above.
How to reproduce
See above - note that another user was mentioning a similar issue in Gitter on Jan 28:
Your personal set up
See above. If you need anything more specific I'm happy to share but this seems pretty straight-forward.
The text was updated successfully, but these errors were encountered: