Concurrency and Multithreading
Important
GitHub Wiki is just a mirror of our online documentation.
We highly recommend using our website docs due to Github Wiki limitations. Only some illustrations, links, screencasts, and code examples will work here, and the formatting may be broken.
Please use https://karafka.io/docs.
Karafka uses native Ruby threads to achieve concurrent processing in four scenarios:
- for concurrent processing of messages from different topics partitions.
- for concurrent processing of messages from same topic different partitions (via Multiplexing or Non-Blocking Jobs).
- for concurrent processing of messages from a single partition when using the Virtual Partitions feature.
- to handle consumer groups management (each consumer group defined will be managed by a separate thread).
Additionally, Karafka supports Swarm Mode for enhanced concurrency. This mode forks independent processes to optimize CPU utilization, leveraging Ruby's Copy-On-Write (CoW) and process supervision for improved throughput and scalability in processing Kafka messages.
!!! Tip "Separate Resources Management Documentation"
Please be aware that detailed information on how Karafka manages resources such as threads and TCP connections can be found on a separate documentation page titled [Resources Management](https://karafka.io/docs/Resources-Management). This page provides comprehensive insights into the allocation and optimization of system resources by Karafka components.
After messages are fetched from Kafka, Karafka will split incoming messages into separate jobs. Those jobs will then be put on a queue from which a poll of workers can consume. All the ordering warranties will be preserved.
You can control the number of workers you want to start by using the concurrency setting:
class KarafkaApp < Karafka::App
setup do |config|
# Run two processing threads
config.concurrency = 2
# Other settings here...
end
endKarafka uses multiple threads to process messages coming from different topics and partitions.
Using multiple threads for IO intense work can bring great performance improvements to your system "for free."
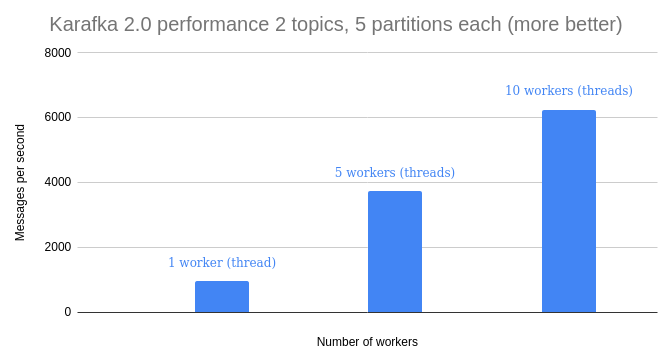
*This example illustrates performace difference for IO intense jobs.
Example of work distribution amongst two workers:

!!! note ""
Please keep in mind that if you scale horizontally and end up with one Karafka process being subscribed only to a single topic partition, you can still process data from it in parallel using the **Virtual Partitions** feature.
Karafka uses a concept called subscription groups to organize topics into groups that can be subscribed to Kafka together. This aims to preserve resources to achieve as few connections to Kafka as possible.
This grouping strategy has certain downsides, as with one connection, in case of a lag, you may get messages from a single topic partition for an extended time. This may prevent you from utilizing multiple threads to achieve better performance.
If you expect scenarios like this to occur, you may want to manually control the number of background connections from Karafka to Kafka. You can define a subscription_group block for several topics, and topics within the same subscription_group will be grouped and will share a separate connection to the cluster. By default, all the topics are grouped within a single subscription group.
Each subscription group connection operates independently in a separate background thread. They do, however, share the workers' poll for processing.
Below you can find an example of how routing translates into subscription groups and Kafka connections:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
subscription_group 'a' do
topic :A do
consumer ConsumerA
end
topic :B do
consumer ConsumerB
end
topic :D do
consumer ConsumerD
end
end
subscription_group 'b' do
topic :C do
consumer ConsumerC
end
end
end
end

*This example illustrates how Karafka routing translates into subscription groups and their underlying connections to Kafka.
!!! note ""
This example is a simplification. Depending on other factors, Karafka may create more subscription groups to manage the resources better. It will, however, never group topics together that are within different subscription groups.
!!! note ""
Subscription groups are a different concept than consumer groups. It is an internal Karafka concept; you can have many subscription groups in one consumer group.
!!! note ""
If you are interested in how `librdkafka` fetches messages, please refer to [this](https://github.com/edenhill/librdkafka/wiki/FAQ#how-are-partitions-fetched) documentation.
Karafka allows you to parallelize further processing of data from a single partition of a single topic via a feature called Virtual Partitions.
Virtual Partitions allow you to parallelize the processing of data from a single partition. This can drastically increase throughput when IO operations are involved.
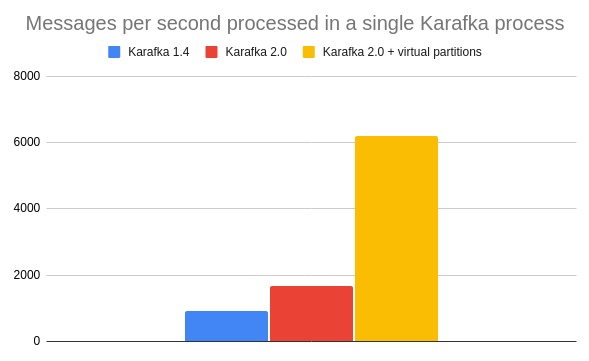
*This example illustrates the throughput difference for IO intense work, where the IO cost of processing a single message is 1ms.
You can read more about this feature here.
Parallel consumption and processing of the same topic partitions in Karafka can be achieved through Multiplying the connections or using Non-Blocking Jobs feature. Multiplexing creates connections to Kafka, allowing for concurrent consumption, which is ideal for different operations or scaling needs. Non-Blocking Jobs, conversely, utilize the same connection but employ a sophisticated pausing strategy to handle processing efficiently. The choice between these approaches depends on the specific requirements, such as operation type and scale. For a comprehensive understanding, visiting the dedicated documentation pages for Multiplexing and Non-Blocking Jobs is recommended.
Since each consumer group requires a separate connection and a thread, we do this concurrently.
It means that for each consumer group, you will have one additional thread running. For high-load topics, there is always an IO overhead on transferring data from and to Kafka. This approach allows you to consume data concurrently.
Karafka is designed to efficiently handle a high volume of Kafka messages by leveraging a pool of worker threads. These workers can run in parallel, each processing messages independently. This parallelization allows Karafka to achieve high throughput by distributing the work of processing messages across multiple threads. However, this concurrent processing model can sometimes encounter a phenomenon known as work saturation or job saturation.
Work saturation, in the context of multi-threaded processing, occurs when there are more jobs in the queue than the worker threads. As a result, an increasingly large backlog of jobs accumulates in the queue. The implications of work saturation can be significant, and the growing backlog leads to increased latency between when a job is enqueued and when it's eventually processed. Persistent saturation can also lead to a strain on system resources, possibly exhausting memory or rendering the system unable to accept new jobs.
Recognizing the potential challenge of job saturation, Karafka provides monitoring capabilities to measure job execution latency. This allows you to track the time from when a job enters the queue to when it's processed. Rising latency can indicate that the system is nearing saturation and isn't processing jobs as quickly as it should.
There are a few ways to measure the saturation in Karafka:
- You can look at the
Enqueuedvalue in the Web-UI. This value indicates the total number of jobs waiting in the internal queues of all the Karafka processes. The high value there indicates increased saturation. - You can log the
messages.metadata.processing_lagvalue, which describes how long a batch had to wait before it was picked up by one of the workers. - If you are using our Datadog integration, it contains the
processing_lagmetrics.
Job saturation in Karafka isn't inherently critical, but it may lead to increased consumption lag, resulting in potential delays in processing tasks. This is because when the system is overloaded with jobs, it takes longer to consume and process new incoming data. Moreover, heavily saturated processes can create an additional issue; they may exceed the max.poll.interval.ms configuration parameter. This parameter sets the maximum delay allowed before the Kafka broker considers the consumer unresponsive and reassigns its partitions. In such a scenario, maintaining an optimal balance in job saturation becomes crucial for ensuring efficient message processing.
In the Karafka framework, the default operation mode favors minimal connections to Kafka, typically using just one connection per process for all assigned topic partitions. This approach is generally efficient and ensures even workload distribution when data is evenly spread across partitions. However, this model might lead to reduced parallelism in scenarios where significant lag and many messages accumulate in a few partitions. This happens because polling under such circumstances retrieves many messages from the lagging partitions, concentrating work there rather than distributing it.
Karafka's default compliance with the max.poll.interval.ms setting exacerbates this issue. The framework will initiate a new poll once all data from the previous poll is processed, potentially leading to periods where no further messages are being consumed because the system is busy processing a backlog from one or a few partitions. This behavior can dramatically reduce the system's overall concurrency and throughput in extreme cases of lag across many partitions.
To address these challenges and enhance parallel processing, Karafka offers several strategies:
-
Optimizing Polling: Adjusting the
fetch.message.max.bytessetting can reduce the number of messages fetched per partition in each poll. This ensures a more effective round-robin distribution of work and prevents any single partition from overwhelming the system. -
Non-Blocking Jobs: This approach allows the same connection to fetch new messages while previous messages are still being processed. It uses a sophisticated pausing strategy to manage the flow, ensuring processing stays caught up in polling.
-
Virtual Partitions: By subdividing actual Kafka partitions into smaller, virtual ones, Karafka can parallelize the processing of messages from a single physical partition. This can significantly increase the processing throughput and efficiency.
-
Connection Multiplexing: Establishing multiple connections for the same consumer group allows for independent polling and processing. Each connection handles a subset of partitions, ensuring that a lag in one doesn't halt the polling of others.
-
Subscription Groups: Organizes topics into groups for parallel data polling from multiple topics, mitigating lag effects and improving performance by utilizing multiple threads.
Choosing the right strategy (or combination of strategies) depends on your system's specific characteristics and requirements, including the nature of your workload, the scale of your operations, and your performance goals. Each approach offers different benefits and trade-offs regarding complexity, resource usage, and potential throughput. Therefore, carefully analyzing your system's behavior under various conditions is crucial to determining the most effective path to improved parallelism and performance. For detailed guidance and best practices on implementing these strategies, consulting the dedicated documentation pages on Multiplexing, Non-Blocking Jobs, and other relevant sections of the Karafka documentation is highly recommended.
Karafka provides an advanced operation mode known as Swarm, designed to optimize the framework's performance by leveraging Ruby's Copy-On-Write (CoW) mechanism and multi-process architecture. This mode significantly enhances Karafka's ability to utilize multiple CPU cores more efficiently, thus improving the throughput and scalability of your Ruby applications that process Kafka messages.
In Swarm Mode, Karafka forks multiple independent processes, each capable of running concurrently. This approach allows the framework to manage and supervise these processes effectively, ensuring high availability and resilience. By doing so, Karafka can better distribute the workload across available CPU cores, minimizing bottlenecks and maximizing processing speed.
Swarm has its own section. You can read about it here.