Latest update: SDXL branch made default! In case of issues, use master branch (read instructions how to change branches there)
Now this extension should work in WebUI Forge too!
Discussion: AUTOMATIC1111/stable-diffusion-webui#7659
This is extension for AUTOMATIC1111/stable-diffusion-webui for creating and merging Textual Inversion embeddings at runtime from string literals.
It creates a tab named EM
This extension is included into the official index! Just use Available → Load from in WebUI Extensions tab.
Or copy the link to this repository into Install from URL:
https://github.com/klimaleksus/stable-diffusion-webui-embedding-merge
Also you may clone/download this repository and put it to stable-diffusion-webui/extensions directory.
Did you know that StableDiffusion reads your prompt by so-called tokens? They are multidimensional numerical vectors that construct together words and phrases.
It is actually possible to create new words by simple merging (adding) different vectors together, resulting in something that could mean both things simultaneously!
However, it is not always working, and sometimes it won't give what you would expect, but it is definitely worth experimenting.
Basically, this extension will create Textual Inversion embeddings purely by token merging (without any training on actual images!) either automatically during generation, or manually on its tab.
The tab EM can be used to:
- inspect your prompt or specific words
- create TI embeddings from text fragments with or without merging
- check correctness of your merge expressions
Use syntax <'one thing'+'another thing'> to merge terms "one thing" and "another thing" together in one single embedding in your positive or negative prompts at runtime.
Also use <'your words'*0.5> (or any number, default is 1.0) to increase or decrease the essence of "your words" (which can be even zero to disable that part of the prompt).
To use attention with round brackets ( ), put them around < >, like (<'one'+'two'>:0.9)
Use as many <> in one prompt, as you want; also you can put your existing TI embedding names inside ' '.
When you need literal <' for some reason, put a space between. You cannot have literal <' anywhere in your prompts; but with a space between (< ') it will be ignored by this extension.
If some other extension interferes with this syntax, change angular brackets to curly: {'also works'*4}
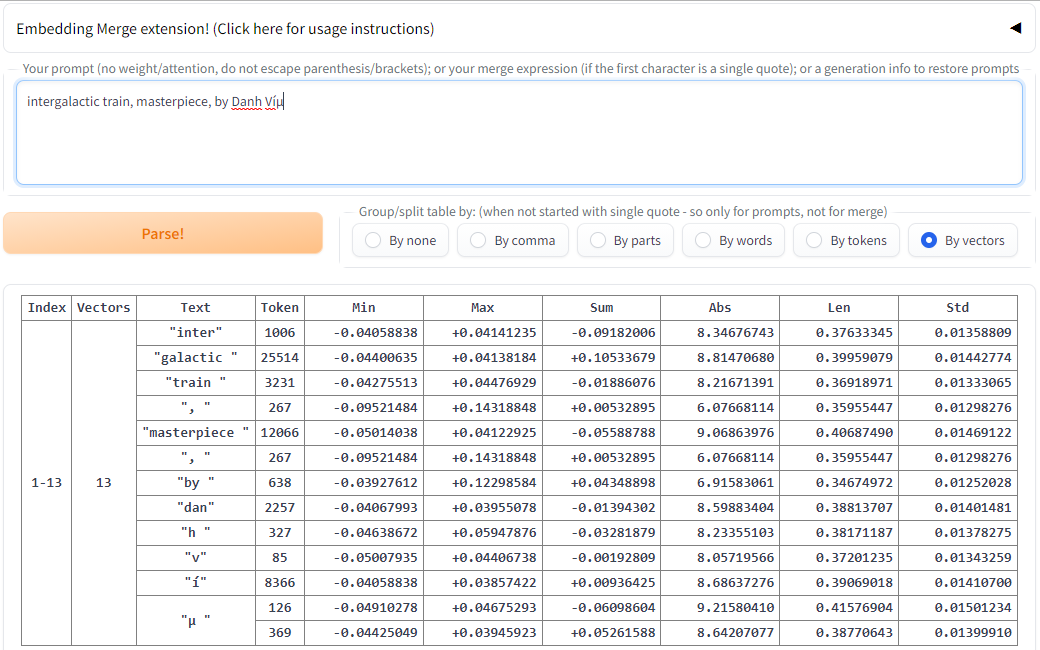
You can paste your vanilla prompt (without any other special syntax) into the textbox in EM tab to see how it is parsed by WebUI. All of detected Textual Inversion embeddings will be extracted and presented to you along with literal text tokens. For example:
intergalactic train, masterpiece, by Danh Víµ
By none= interpret the prompt as a whole, extracting all characters from real tokensBy comma= split the prompt by tags on commas, removing commas but keeping source space charactersBy parts(default) = split at TI embeddings, joining text parts together, keeping spacesBy words= split only after tokens that actually produce space character at the endBy tokens= split at everything except characters that are represented with more than one vectorBy vectors= show all vectors separated, even for TI embeddings
Index= index of one vector or index range (inclusive) for this rowVectors= number of final vectors for this row (to clearly see it)Text= original or recreated from tokens text, enclosed in quotes for clarityToken= list of CLIP token numbers that represent this row; for TI embeddings * or *_X where X is the index of current embedding vectorMin= lowest (negative) value of the vector or grouped vectors valuesMax= largest valueSum= sum of all values with signAbs= sum of modulus of each value, without sign (always positive)Len= vector length in L2 norm, square root of sum of squared values (computed approximate)Std= standard deviation for vector values.
To make sure your prompt is interpreted the way you expect (for example, that existing TI embeddings are detected). Also you can explore CLIP tokens this way.
If you type a new name into the textbox on the bottom, your whole current prompt will be converted into a single Textual Inversion embedding with that name (and stored inside /embeddings/embedding_merge/ subdirectory). You can use this for:
- Creating a shortened part to quickly use in prompts (not recommended though, since you will lose the original text later), but with no other benefits;
- Prepare TI embedding for actual training by using existing embeddings for its initialization.
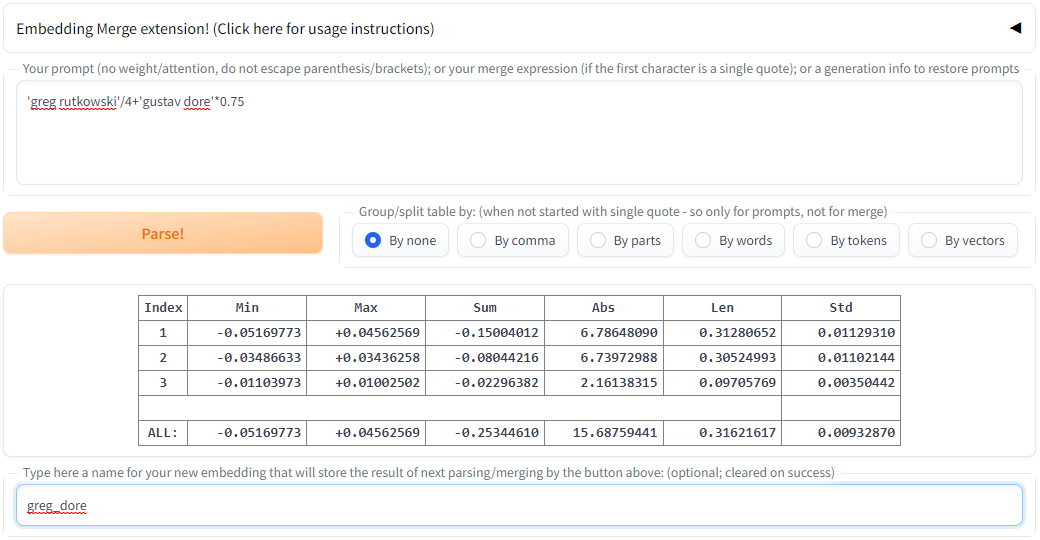
In EM tab you can enter a "merge expression" that starts with a single quote, to see how it will be parsed and combined by this extension. It should contain single quotes around literal texts or TI embeddings, and special operators between them. For example:
'greg rutkowski'/4+'gustav dore'*0.75
'one' + 'two'= blend vectors together by simple sum of all values. If length is different, smallest part will be right-padded with zeroes.'one' - 'two'= as above, but subtraction. Note that + and - can be put only between textual parts and will have lowest priority.'text' * NUM= multiply all vectors of quoted literal by numeric value. You can use floating point (0.85) and negative numbers (-1), but not arithmetic expressions.'text' / NUM= division by number, just as multiplication above. Applies to previous text literal but after previous similar operations, so you can multiply and divide together (*3/5)'text' : NUM= change vector count of literal, to shrink or enlarge (padded with zeros). Only integer without sign!'text' :+ NUMand'text' :- NUM= circular rotate vectors in this token, for example +1 will shift index of each vector by one forward, wrapping on last.'text',NUM(chainable as'a',B,'c','d',E,F…) = concatenate text with a token by its numerical index (so, to get any pure token – use empty left string:'',256). Special tokens:0000= "start token" (index 49406),000= "end token" (index 49407),00= "padding token" (also 49407 for SD1, but 0 for SD2). Token number0is not zero-vector, but for some reason counts as symbol "!" without a space after it, which is impossible to normally enter anyway.
To apply multiplication (or division), cropping or shifting to the result of addition (or subtraction), you cannot use parenthesis; instead, try this syntax:
'one' + 'two' =* NUM= will multiply the sum of 'one' and 'two', but not 'two' alone'one' + 'two' =/ NUM= divide the sum (or any number of sums to the left), effectively the "result" of everything'one' + 'two' =: NUM= crop or enlarge the results'one' + 'two' =:+ NUMor'one' + 'two' =:- NUM= rotate the result
Thus, the following operations are doing the same:
'a'/2 + 'b'/2 + '':1 - 'd'
'a'+'b' =* 0.5 + 'c'*0 + 'd'*-1
There is no true "concatenation" operator (since you will be able to concatenate several separate merge expressions later), but you may replicate it with addition of the same text enlarged and shifted, if you need.
Operation "," has the highest priority (it will directly construct the string before doing anything else), so you cannot concatenate anything to the result of addition or multiplication. Use it only to add tokens by index in your text.
For example, repeating a two-vector word, resulting in 4 vectors of two equal pairs:
'artstation' + 'artstation' :4 :+2
'artstation','artstation'
You can use shifting to join several vectors of the same text together. For example, given a 4-vectors word you may merge those vectors in one:
'kuvshinov' + 'kuvshinov':-1 + 'kuvshinov':-2 + 'kuvshinov':-3 =: 1
'',1836 + '',85 + '',43074 + '',341
Note that those indices are referring to "ku|v|shino|v[space]" and cannot be entered from raw text, since it would be parsed as "ku[space]", "v[space]" and "shino[space]", which are different tokens!
When you merge strings of unequal length, shortest one is padded with zero vectors; if you want to pad it with something else, you should check the vector count and concatenate accordingly:
'close-up',00,00 + 'out-of-frame' + 'cropped',00,00,00,00
'up',00,00+'of-frame'+'',00,00,00 =:5:+2 + 'close-'+'out-'+'cropped',00
To prepare your expression and fix any errors. You can evaluate its correctness by roughly comparing numbers in table (for example, adding vectors will generally result in higher Abs value; while multiplication is directly changing all numbers straightforwardly).
If for some reason you couldn't use the syntax for merging prompts at runtime, at least you will be able to enter a name and create a regular TI embedding from your merge expression. Then you may use it even without this extension installed!
Also you can check numerical parameters of your trained textual embedding and compare it with "normal" vectors. For example, very large Len or Std will mean that something is wrong and at least you may divide it in attempt to fix.
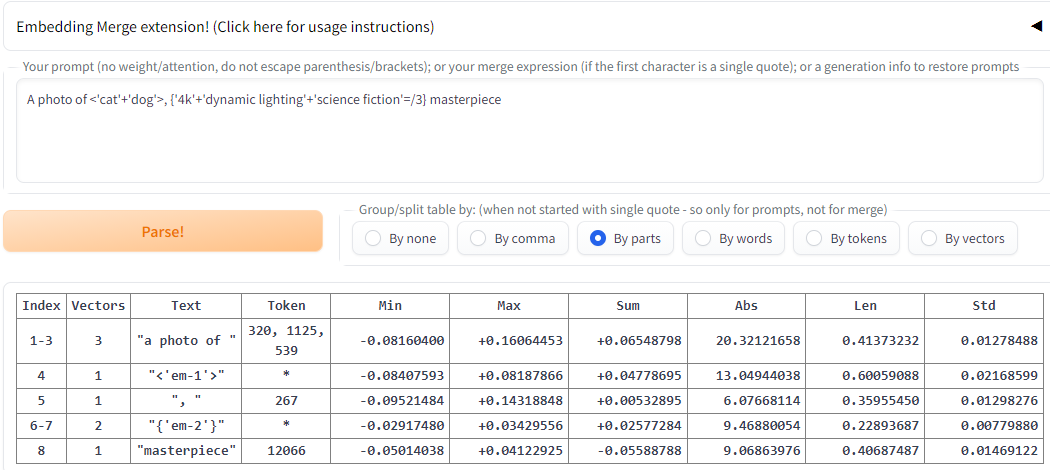
If you put a valid merge expression enclosed in angular <'…' …> or curly {'…' …} brackets anywhere in your prompt (with no space between < or { and ') on EM tab, it will be parsed and merged into one temporary Textual Inversion embedding, which replaces the expression itself. The resulting prompt will be joined from those embeddings and anything between expressions. For example:
A photo of <'cat'+'dog'>, {'4k'+'dynamic lighting'+'science fiction'=/3} masterpiece
Combining different subjects or styles together, resulting in joined concepts:
A realistic photo of the <'girl'+'doll'> in rainbow dress standing on a shore.
Art by <'greg rutkowski'*X+'hayao miyazaki'*Y> style.
Notes:
- Works best when all of your subjects have the same number of vectors (also can be roughly simulated by BREAK statement:
… photo of the girl in rainbow … BREAK … photo of the doll in rainbow …); - You don't have to divide on the number of added parts, especially if your subjects are very different (e.g. not contain same tokens);
- By multiplying each part in second example (where X and Y are numbers between 0.0 and 1.0) you may get a weighed combination or interpolation.
Changing weight of individual words in prompt:
A <'peacock'*X> is standing on a top of <'giraffe'*Y>.
worst quality, ugly, <'bad anatomy,':0> blurry, cropped
Where X and Y will be numbers from 0.0 to 1.0 or even higher, up to 5. This way you can directly change relative affection between subjects.
Notes:
- Often values between 0.5 and 1.5 don't really change anything, looking like plain 1.0
- Values lower than 0.5 and near to 0.0 are greatly reducing subject weight indeed! Up to its complete absence (which is not possible otherwise, for example even zero attention
(word:0)does not eliminate "word" from the prompt) - High numbers might increase the presence of an object, not in quantity but in essence. Very high multipliers (above 10) corrupt the subject, but still don't destroy the image itself.
Eliminating a part of the negative prompt by zeroing its vectors can be used to understand the effect of the part in question, without shifting the rest of the text otherwise. Since WebUI is splitting long prompts at arbitrary commas (and then merging resulting parts together), simple deletion of a part might change things severely.
You can actually put merge expressions in angular or curly brackets into your txt2img or img2img prompt in WebUI. This extension will intercept both main and negative prompts, parse and merge expressions creating temporary TI embeddings that WebUI will "see" instead of your original text. In generation info there will be internal meaningless names like <'EM_1'>, but extra parameter "EmbeddingMerge" will contain original merge expressions. To quickly restore your prompts, just paste your complete generation information (from .txt or PNG Info) into the textbox on EM tab (also it should work for the official "paste" toolbar button too) – its temporary embeddings will be replaced back with expressions, for example:
a photo of <'EM_1'>
Negative prompt: {'EM_2'}
Steps: 8, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1374372309, Size: 512x512, Model hash: c6bbc15e32, Model: sd-v1-5-inpainting, EmbeddingMerge: "<'EM_1'>=<'sky' * 2/4 + 'forest' * 3/4>, {'EM_2'}={'blurry'+'cropped'}", Conditional mask weight: 1
For your information replicating start tokens of the syntax itself:
<'=<'',27,6>or<'',27,262>{'=<'',90,6>or<'',90,262>
Photo of a <'blonde'+'boy'> in <'red'+'shirt'> wearing <'green'+'pants'> and <'blue'+'shoes'>
– results in anything but not what was requested.
Painting by <'William' + '-' + 'Adolphe'+'Adolphe':+1 + 'Bouguereau'+'Bouguereau':+1+'Bouguereau':+2 =:1>. A girl, masterpiece
– results in something barely distinct from zeroing the term altogether.
Full-body photo of a <'king'-'man'+'woman'>
Detailed photo of <'yellow'-'red'> car
– generally results in totally ruined composition.
A portrait of the princess. <'frame, black-white'*-1>
A cat is chasing a dog. <''-'road'-'grass'>
– will still add those concepts to positive prompt, but with weird presence. You could find more luck with small values -0.1-0.0 though.
All of the images below were created on sd-v1-5-inpainting with 32 steps of Euler_a.
a realistic photo of the XXX in rainbow dress standing on a shore. Symmetric face, full-body portrait, award-winning masterpiece.
Negative prompt: bad anatomy, ugly, cropped
XXX = doll: (starting from this prompt)

XXX = girl: (what if we change the subject?)

XXX = <'girl'+'doll'>: (merging them together!)

XXX = <'girl'+'doll'=/2>: (see, you don't have to equalize the sum, difference is negligible)

XXX = <'girl'/2+'doll'>: (halving girl's weight to reveal more essence from a doll)

a XXX is standing on a top of YYY. Rare naturalistic photography.
XXX = peacock, YYY = giraffe: (starting prompt, not really working as requested though)

XXX = <'peacock'*0.5>, YYY = giraffe: (less blue bird, more brown animals)

XXX = peacock, YYY = <'giraffe'*0.5>: (less animal, more birds!)

XXX = <'peacock'*4>, YYY = <'giraffe'*2>: (increase both, looks like "on top" is now shadowed by their heavy weight)

XXX = <'peacock'*0>, YYY = <'giraffe'*0>: (completely remove both words without a trace!)

Epic fantasy photography: a gigantic robot is stepping on a small city. Art by XXX style.
XXX = <'greg rutkowski'+'hayao miyazaki'>: (this is what we can get by merging)

XXX = hayao miyazaki: (mr. Miyazaki alone looks like this)

XXX = greg rutkowski: (and our Greg alone like this)

XXX = greg rutkowski and hayao miyazaki: (they both mentioned together otherwise)

XXX = hayao miyazaki and greg rutkowski: (reversed order, still not the same as merging!)
