sky is a web scraping framework, implemented with the latest python versions in mind (3.5+). It uses the asynchronous asyncio framework, as well as many popular modules and extensions.
Most importantly, it aims for next generation web crawling where machine intelligence is used to speed up the development/maintainance/reliability of crawling.
It mainly does this by considering the user to be interested in content from domains, not just a collection of single pages (templating approach).
See it live in action with a news website YOU propose:
- Locally (view demo)
- Remotely (needs online hosting)
Note that the following is only meant as a demo of some kind of app that could be built upon the scraping framework.
Make no mistake: the goal is to provide a smart-scraper, not some ugly UI.
Run:
- Install using pip:
pip3 install -U sky - Run
sky viewat the command line (use-port PORTto change port) - Visit localhost:7900
- Enter a Domain/URL and see the result after clicking
[>>>].
The demo uses a standard configuration that can easily be improved on when setting up a project.
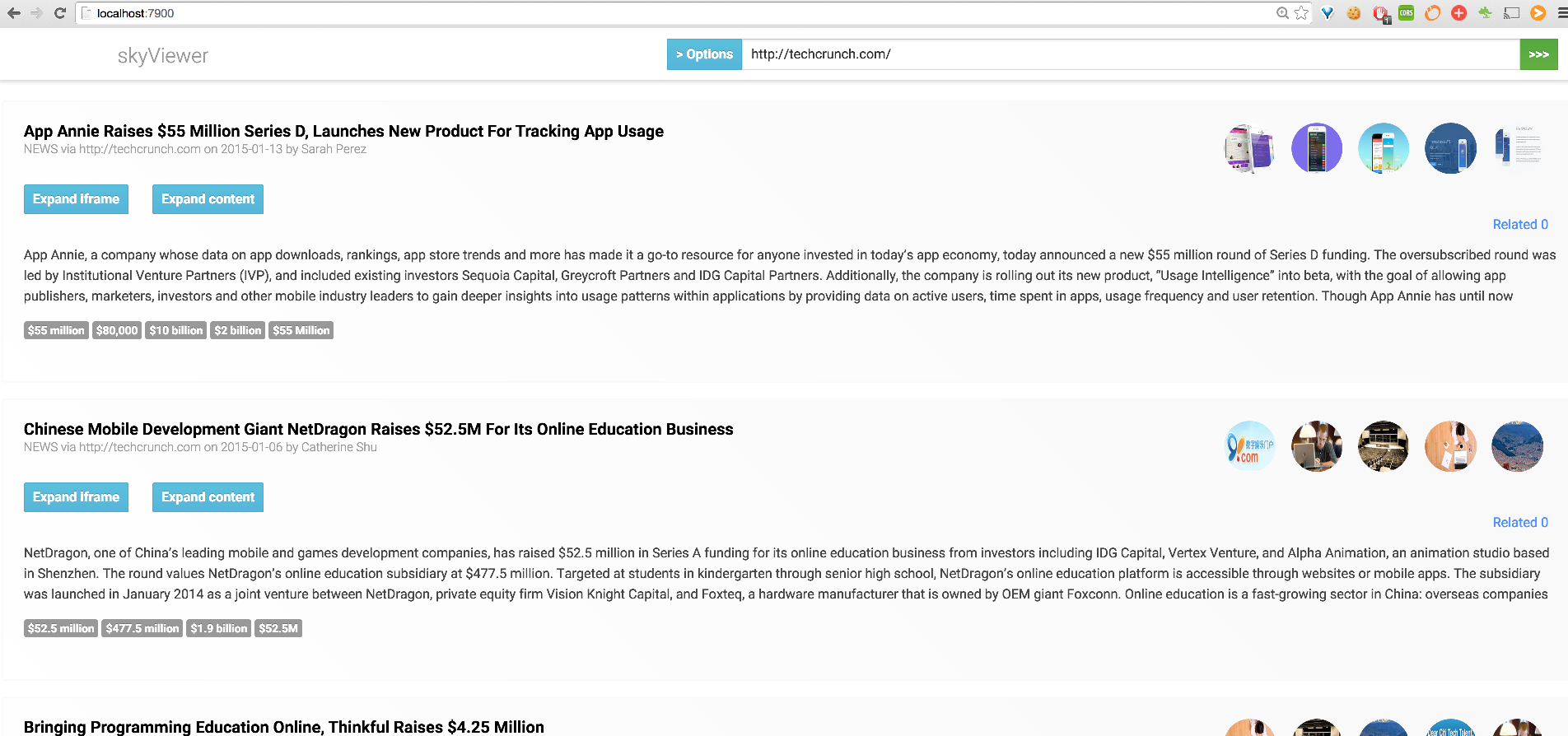
Similar data (title, body, publish_date, images etc) will be very easy to use in your own applications.
These are the features/goals of sky. Checkmarks have been accomplished:
- ✓ Really fast, due to Python 3.5+ new asyncio/aiohttp libraries, based on 500lines/crawler
- ✓ Smart, due to considering crawling of websites instead of single pages
- ✓ Boilerplate FREE, removes crappy content (images, text, etc) that does not belong on pages
- ✓ Nice API, carefully crafted, easily extendible
- ✓ Open-source, democracy driven, with actual support
- ✓ Free, versus enormous costs for even medium scale projects using (worse) online services
- Link-graph-analysis, find out how a domain "looks" like
- Include Batteries, Crawl any news website without any configuration
- Automatic Natural Language Processing, detecting keywords in text automatically
Use pip to install sky:
pip3 install -U skyThis will install only the required packages. Storing data on the local system does not require any other packages.
To store data, the following optional backends are currently available: elasticsearch, cloudant and ZODB.
To setup a project/crawling service, visit this readme for a "Getting started".
It is very much appreciated if you'd like to contribute in one or more of the following areas:
- More Backends
- Documentations/tests
- Improvement of detection
- NLP
By considering crawl content to originate from a domain, rather than individual pages, the following willl be possible:
- ✓ Drop duplicate content (menus, texts, images)
- ✓ Provide error checking tools (making sure no bad documents slip by)
- Detect whether a website changed the layout (causing non-sky scrapers to fail)
- Understand sections of a website, such as comments, forum posts, related links etc
- Consider which pages are linked to which (star graph)
- Figure out the content pages by just pointing at the domain
- Relate pages (page A is related by content to page B)
- Consider an optimal re-crawling path