Enabling ResourceQuotas increases controller-manager CPU usage ~4x #60988
Comments
|
I'm not marking this as a release-blocker as it's failures we started seeing due to testing something new (that we weren't before). |
|
For now I'll send a revert disabling it. However, you can easily experiment against 100-node cluster with the presubmit job I newly added. See #56032 (comment) for details. |
|
One thing to note here is that, even before this change we were seeing flakes of this kind. E.g:
But after this change, we're seeing those continuously. My feeling is that this worsened things on top of something bad that happened already earlier. |
…-e2es Automatic merge from submit-queue. If you want to cherry-pick this change to another branch, please follow the instructions <a href="https://github.com/kubernetes/community/blob/master/contributors/devel/cherry-picks.md">here</a>. Revert "Use quotas in default performance tests" This reverts commit c3c1020. Ref #60988 /cc @gmarek /kind bug /sig scalability /priority critical-urgent ```release-note NONE ```
|
@kubernetes/sig-scalability-bugs do you see this as a v1.10 milestone issue? |
|
Not really.. for the reason I mentioned in #60988 (comment) |
|
Gathered some interesting evidence today. Look at how the CPU usage of controller-manager increased ~4x across runs 454 and 455:
|

|
From the commit diff, it seems most likely that enabling quotas (#60421) caused the mischief. Also, I looked at controller-manager logs from one of the newer runs and find many such lines: |
|
Found one final piece of evidence to prove that it's indeed a problem caused by resource-quotas. Look at how our scalability job running against HEAD saw a fall back to normal CPU usage (across runs 11485 and 11486), with the only change being disabling of quotas:
|
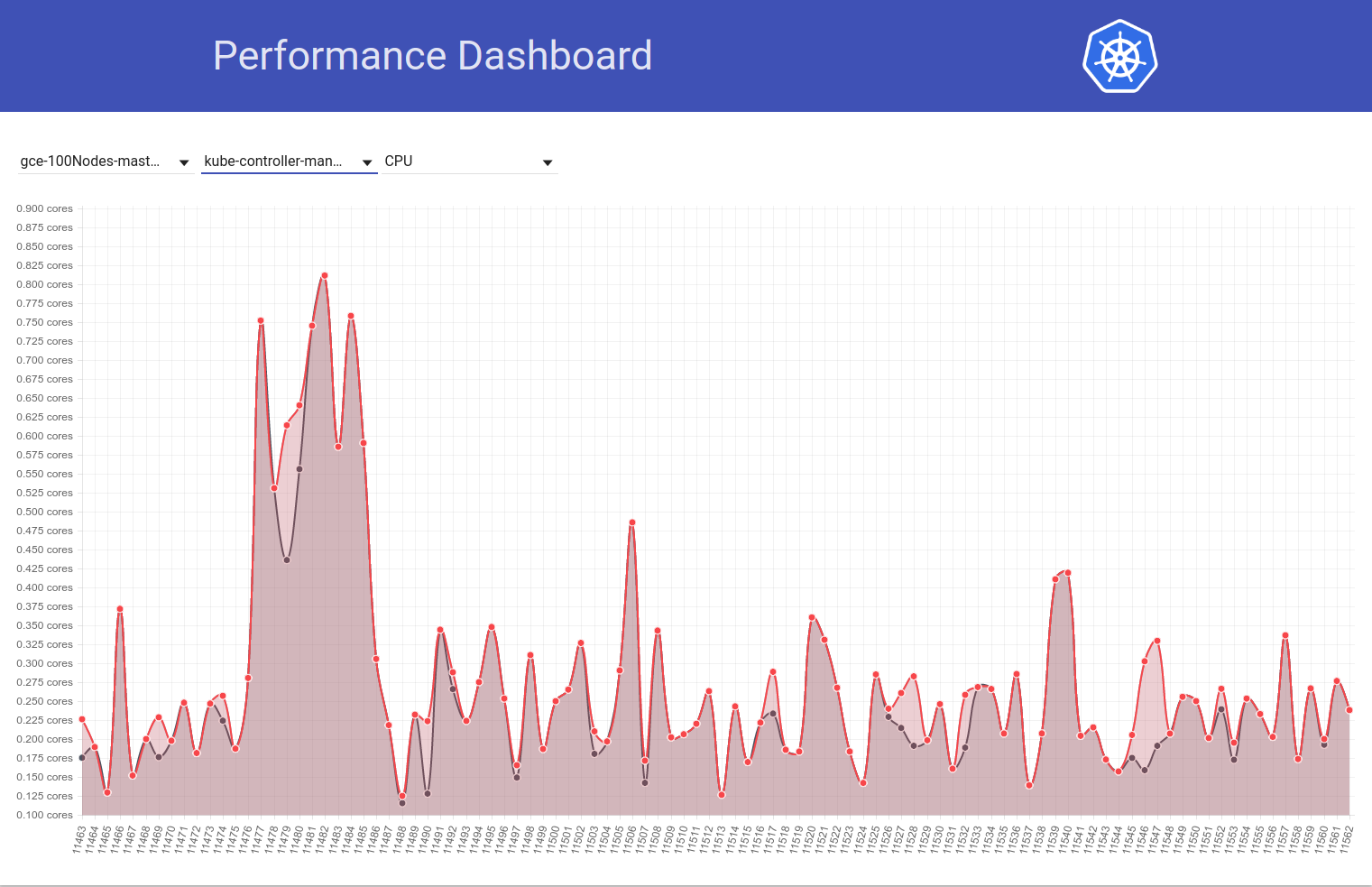
|
cc @davidopp |
|
cc @deads2k |
@derekwaynecarr point of interest |
|
Issues go stale after 90d of inactivity. If this issue is safe to close now please do so with Send feedback to sig-testing, kubernetes/test-infra and/or fejta. |
|
/remove-lifecycle stale |
Based on #60589 (comment)
After enabling quotas (specifically pods per namespace) by default in our tests, we're continuously seeing such failures:
This may be a serious issue with scalability of quotas and needs some digging in.
/assign @gmarek
(who enabled it.. feel free to redirect this as apt)
cc @kubernetes/sig-scalability-bugs
The text was updated successfully, but these errors were encountered: